mysql优化设计方案
首先讲一下项目的场景:
1:这是一个基于web的java项目,其主要功能是对一些视音频信息的处理跟展示,其中视音频数据是由爬虫进行爬取的千万级别量的数据
2:该项目使用的是mysql5.5版本的数据库
3:该项目有一个搜索的功能,需要根据关键字在千万条数据中模糊匹配查询出相应的数据
4:该项目可能面向的用户会比较多,会出现大量高并发
主要涉及问题:
1:本项目对于数据的读操作需求远大于写操作,而且考虑到写操作可能出现的事务问题需要选择innodb作为搜索引擎。然而innodb读取的性能远远低于myIsam
2:由于数据量比较大,对于搜素功能的实现时我们需要使用到模糊查询,此时i需要使用like '%keywords%',那么mysql的搜索将不走索引而是进行全表搜索,那么每次搜索查找都需要消耗至少50秒的时间,这样对性能要求是绝对不允许的
针对以上问题做出以下的解决方案:
1:对数据库进行读写分离,分配1主(Master)1从(Slave)的数据库 ,Master为可读写数据库(使用innodb搜索引擎:为了支持事务),Slave为只读数据库(使用myisam数据引擎:只读可考虑不支持事务,而使用myisam可以提高检索速度)。
1)读写分离需要注意的一点:slave中数据会有延迟,在master中数据进行写入后slave需要一定时间后才会得到同步,所以需要我们项目对于实时性的要求不用做到绝对的精确。
2)读写分离使用于读远大于写的场景,如果只有一台服务器,当select很多时,update和delete会被这些select访问中的数据堵塞,等待select结束,并发性能不高,所以进行读写分离还能提高并发性能。
3)读写分离减少了服务器的压力,使数据库不那么容易奔溃
2:在slave数据库中考虑到全文检索性能问题,使用mysql+coreseek
1)对于mysql数据库,在5.6版本前只有myIsam搜索引擎支持全文索引(fulltext关键字),5.6版本后支持innodb的全文索引。然而它们却不支持中文的索引,这对于我们这个项目需要的中文搜索是个很大的问题。
2)一开始我的想法是使用lucence进行中文分词索引,但是效率跟使用方法都没有达到理想的效果,比较lucence不是针对数据库来的
3)之后是选择了sphinx,然而sphinx也是不支持中文的,想要支持到中文需要自己做很多处理。
4)最后选择了coreseek,它是中华民国的伟大开发者们开发的支持中文分词的,支持mysql的一个全文检索的一个搜索引擎(它是基于Sphinx的),它对于千万级别数据的搜索速度能达到零点几的级别。用它结合mysql能解决问题2。
以下是流程图:
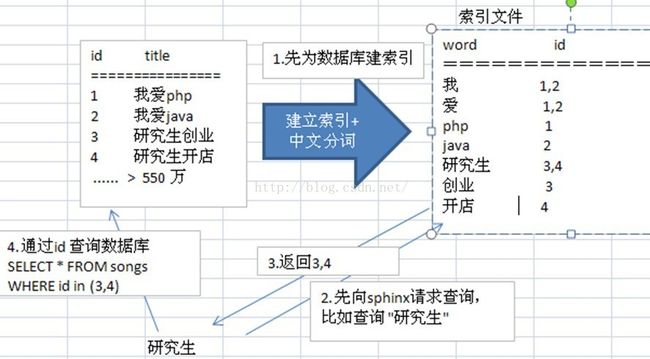
在web中通过调用sphinx提供的api我们能够检索出mysql中对于的主键id值,然后再通过这些id值查询数据库(走数据库中的索引),这样就能大大的提升搜索的速度了。
当然这只是我个人的解决方案,可能有很多不足之处,希望大家帮忙纠正学习