数据库(十一)mysql sql函数
.1)count
语法如下:
select count(*) from tableName; select count(column_name) from tableName; select count(DISTINCT column_name) from tableName;Note:
count(column_name) 函数返回指定列的值的数目(NULL 不计入):
count(distinct column_name) 函数返回指定列的不同值的数目
.2)group by
分组函数,根据一个列或者多个列多结果集进行分组,常常结合合计函数使用。
语法如下:
SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name
.3)having
sql中出现having函数的原因是where不能跟合计函数一起使用,通俗的将,having就是对where条件下查询出来的结果进行过滤。
语法如下:
SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name HAVING aggregate_function(column_name) operator value
举个例子,数据库表tt中有如下数据:
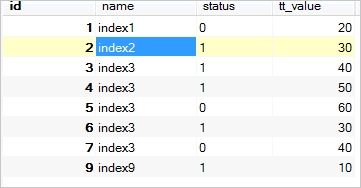
数据库表tt2的数据如下:
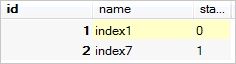
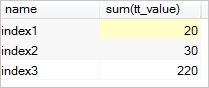
统计表tt中name下各个index的tt_value之和,且统计结果value不小于20;
select name,sum(tt_value) from tt group by name having sum(tt_value)>=20;结果集如下:
Note:
当同时含有where子句、group by 子句 、having子句及聚集函数时,执行顺序如下:
(1)执行where子句查找符合条件的数据;
(2)使用group by 子句对数据进行分组;对group by 子句形成的组运行聚集函数计算每一组的值;
(3)最后用having 子句去掉不符合条件的组。
.4)avg
AVG 函数返回数值列的平均值(NULL 值不包括在计算中).
语法如下:
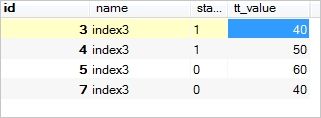
SELECT AVG(column_name) FROM table_name如我们tt表中大于tt_value平均值的列sql如下:
select * from tt where tt_value >(select avg(tt_value) from tt);tt_value中平均值为35,大于35的列如下:
.4)join
多张表通过表中的字段连接起来返回结果,join 有以下几种类型:
JOIN: 如果表中有至少一个匹配,则返回行
LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行
RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行
FULL JOIN: 只要其中一个表中存在匹配,就返回行
下面我们一一介绍以上几种的用法:
(a)inner join

产生的结果是两个表的交集。
(b)left join
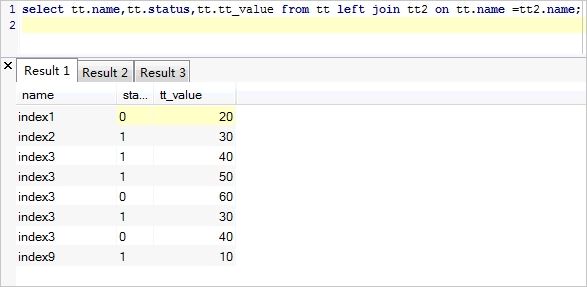
left join 关键字会从左表 (tt) 那里返回所有的行,即使在右表 (tt2) 中没有匹配的行。
(c)right join
right join 跟left join z正好相反,返回右表中所有的行,即使左标中没有匹配的行。
(d)full join
可以理解为left join 跟right join 的集合,也就是tt表跟tt2表结果集的并集。
.5)union
将两个sql的结果合并起来,两个sql查询的结果要一致,列的顺序也必须一致。
语法如下:
select column1,column2 from table1 union select column1,column2 from table2
执行如下sql:
select name,status from tt union select name,status from tt2;结果集如下:

通过tt,tt2的表数据,我们来分析union后的数据结果,发现union函数将重复的记录给删除了,并且结果是按照name 进行排序的。
union all
union all 是将两个sql的结果集合并起来,不会剔除重复的数据,我们执行如下sql
select name,status from tt union all select name,status from tt2;结果集如下:
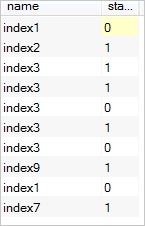
可以看出union跟union all相比,union需要排序并剔除重复的数据,所以性能上较union all要高的多。