Hadoop自定义数据类型和输入格式
Hadoop自定义数据类型和输入格式
一,自定义一个数据类型:User类
该类实现WritableComparable接口,并且带三个属性:name,sex,age
重写其write(),readFields(),compareTo()方法,分别对应
写出文件格式,读文件的格式,和比较该对象的值
设置其属性的get()与set()方法。
WritableComparable接口与Writable接口的区别是:
WritableComaparable多了一个compareTo()方法,用来比较对象的值,这里
也做了个简单的比较,用来比较age
二,自定义输入格式,该类是:YaoUerRecordRead类:
它继承了RecordReader类,这里还是保留了他以前的
lineRecordReader它封装了按行读取的格式。是
key value的形式value指的是我们自己定义的User.
在setKeyValue方法中我们会对User重新进行截取
和值的存储以达到自定义的输入的目的。这里会先
通过“;”分割,然后再通过:进行第二次分割。最后
存值。
然后通过hadoop底层的调用会将结果输出到文件。
三,代码:
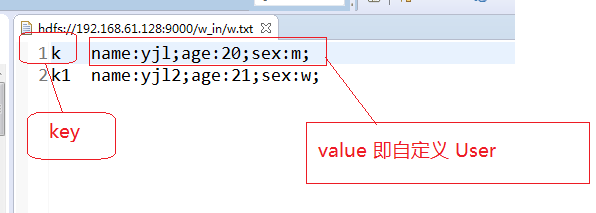
1,输入的数据:
2,自定义数据类:
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class User implements WritableComparable {
private Integer age;
private String name;
private String sex;
public User() {
}
public User(Integer age, String name, String sex) {
this.age = age;
this.name = name;
this.sex = sex;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
@Override
public String toString() {
return "User [age=" + age + ", name=" + name + ", sex=" + sex + "]";
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(age);
out.writeUTF(name);
out.writeUTF(sex);
}
@Override
public void readFields(DataInput in) throws IOException {
this.age = in.readInt();
this.name = in.readUTF();
this.sex = in.readUTF();
}
@Override
public int compareTo(User o) {
return this.age-o.age;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((age == null) ? 0 : age.hashCode());
result = prime * result + ((name == null) ? 0 : name.hashCode());
result = prime * result + ((sex == null) ? 0 : sex.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
User other = (User) obj;
if (age == null) {
if (other.age != null)
return false;
} else if (!age.equals(other.age))
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
if (sex == null) {
if (other.sex != null)
return false;
} else if (!sex.equals(other.sex))
return false;
return true;
}
}
3,输入格式类:YaoUerInputFormat
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
public class YaoUerInputFormat extends FileInputFormat<Text, User> {
@Override
public RecordReader<Text, User> createRecordReader(InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException {
context.setStatus(split.toString());
return new YaoUerRecordRead(context.getConfiguration());
}
}
4,自定义的RecordRead类:YaoUerRecordRead
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.LineRecordReader;
public class YaoUerRecordRead extends RecordReader<Text, User> {
public static final String KEY_VALUE_SEPERATOR =
"mapreduce.input.keyvaluelinerecordreader.key.value.separator";
private LineRecordReader lineRecordReader;
private byte separator = (byte)'\t';
private Text key;
private User value;
private Text innerValue;
public Class getKeyClass() {
return Text.class;
}
public YaoUerRecordRead(Configuration conf) {
lineRecordReader = new LineRecordReader();
String sepStr = conf.get(KEY_VALUE_SEPERATOR,"\t");
this.separator = (byte) sepStr.charAt(0);
}
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
lineRecordReader.initialize(split, context);
}
public static void setKeyValue(Text key, User value, byte[] line,int lineLen, int pos) {
if (pos == -1) {
key.set(line, 0, lineLen);
value.setAge(0);
value.setName("");
value.setSex("");
} else {
key.set(line, 0, pos);
Text text=new Text();
text.set(line, pos + 1, lineLen - pos - 1);
System.out.println("text:"+ text.toString() );
String[] userAll=text.toString().split(";");
//User userInfo=new User();
for (String u : userAll) {
String k=u.split(":")[0];
String v=u.split(":")[1];
System.out.println(k+"==>"+v);
if(k.equals("name")){
value.setName(v);
}else if(k.equals("age")){
value.setAge(Integer.parseInt(v));
}else if(k.equals("sex")){
value.setSex(v);
}
}
System.out.println("setkv--value======="+value);
}
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
byte[] line = null;
int lineLen = -1;
if (lineRecordReader.nextKeyValue()) {
innerValue = lineRecordReader.getCurrentValue();
System.out.println("元数据innerValue:"+innerValue);
line = innerValue.getBytes();
lineLen = innerValue.getLength();
} else {
return false;
}
if (line == null){
return false;
}
if (key == null) {
key = new Text();
}
if (value == null) {
value = new User();
}
int pos = findSeparator(line, 0, lineLen, this.separator);
setKeyValue(key, value, line, lineLen, pos);
return true;
}
public static int findSeparator(byte[] utf, int start, int length,
byte sep) {
for (int i = start; i < (start + length); i++) {
if (utf[i] == sep) {
return i;
}
}
return -1;
}
@Override
public Text getCurrentKey() throws IOException, InterruptedException {
return key;
}
@Override
public User getCurrentValue() throws IOException, InterruptedException {
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
return lineRecordReader.getProgress();
}
@Override
public void close() throws IOException {
lineRecordReader.close();
}
}
测试类:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TestUserInputFormat {
public static class UserMapper extends Mapper<Text,User, Text, User>{
protected void map(Text key, User value, Mapper<Text, User, Text, User>.Context context) throws IOException, InterruptedException {
context.write(key, value);
}
}
public static void main(String[] args) {
try {
Configuration conf=new Configuration();
Job job=Job.getInstance(conf,"Test1 UserInfo");
job.setJarByClass(TestUserInputFormat.class);
job.setInputFormatClass(YaoUerInputFormat.class);
job.setMapperClass(UserMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(User.class);
FileInputFormat.addInputPath(job, new Path("hdfs://192.168.61.128:9000/w_in/"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.61.128:9000/w_out/"+System.currentTimeMillis()+"/"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (IllegalStateException e) {
e.printStackTrace();
} catch (IllegalArgumentException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
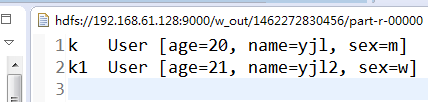
测试结果: