浅谈系统的高可用性
“高可用性”(High Availability)通常来描述一个系统经过专门的设计,从而减少停工时间,而保持其服务的高度可用性。
对于高可用这个概念,个人认为至少满足下列几点:
1.程序异常处理,这个是基本功,仅能在正常情况下运行的程序不叫程序
2.机房容灾,即当个别机器损坏,或者个别机房网络割接时,仍可正常运作
3.系统容易扩展,即当遇到性能瓶颈时,可横向扩展解决,比如多部署几个程序即可解决,无需更改代码
4.无需过多的人工干预,7*24都能工作,遇错自动调整,不必投入人力时刻关注程序的状态
下面拿一个比较简单数据采集系统来分析一下问题,图是用Windows画图板画的,不够严谨,有时间再换过来
数据流程:producer(采集)->rabbitmq(转发)->consumer(消费入库)->DB
producer:采集器,消息生产者
rabbitmq:消息转发
consumer:数据消费者
DB:数据库
图1:最简单的模型
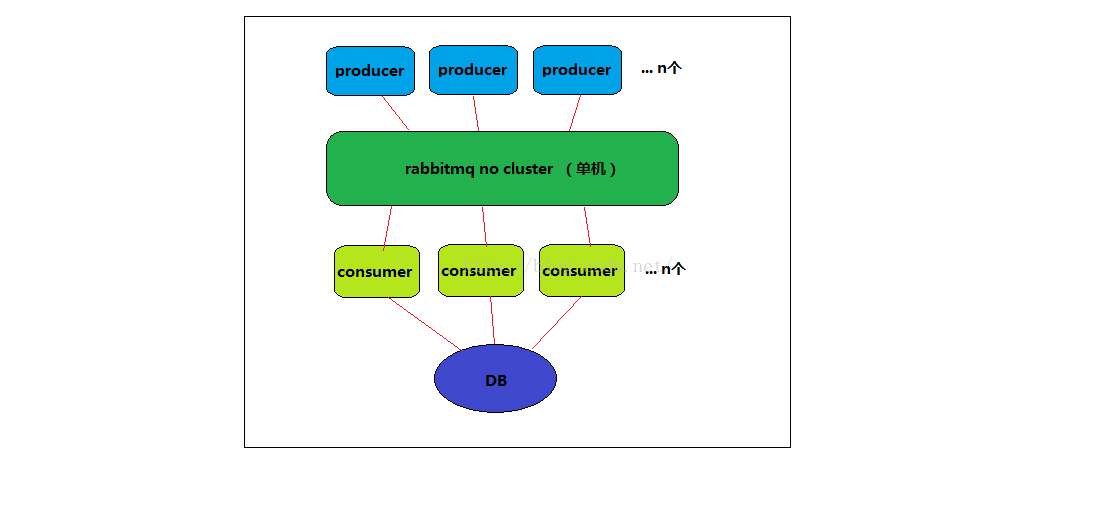
先来看看图1的架构达成了哪些高可用的要素,还有哪些致命的缺陷
1.producer可灵活增加,目的达成
2.rabbitmq为单机进程,一旦出现机器或者网络故障则不可用
3.consumer可灵活增加,目的达成
4.DB为单点,一旦出现机器或者网络故障则不可用,且容易出现性能瓶颈
仔细想一想,很容易就发现图1系统的缺陷,机器和网络故障都是很常见的,所以这个方案根本不靠谱。
图2:稍作优化的模型
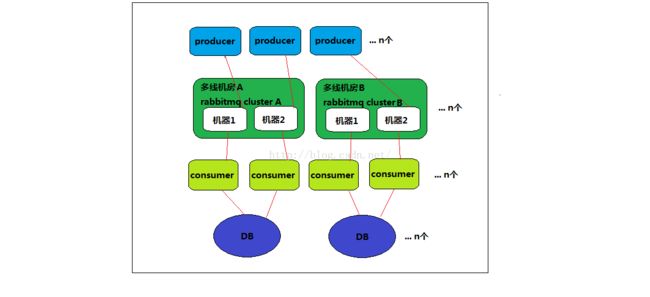
先来看图2比图1多了哪些组件,
rabbitmq从单机版变成了2个独立集群,且部署在不同的机房,且是多线机房,满足电信联通移动等网络
DB根据业务特性,拆分成N独立DB,分摊了数据库的写压力,也将数据的可用性提高了。
再来详细讲解图2各个程序的设定,
producer:
1.根据同ISP原则配置了多个rabbitmq节点,首先避免跨ISP传输数据的情况,速度更快,可以进一步优化为就近访问线路
2.遇到rabbitmq节点死机或者网络故障时,自动切换rabbitmq节点,解决了传输故障的问题
rabbitmq:
1.分布在多个机房,且可为多个ISP服务,基本达到了高可用的目标
2.当集群性能出现瓶颈时,横向新增集群即可,这里缺陷就是当rabbitmq新增集群时,如何更新所有的producer配置,通过逐一更改程序的配置再重启这种方式显然很原始,后面再优化这一点
consumer:
1.每个消息队列至少应该对应2个consumer,并部署在不同的机器,这样就避免了单机单进程的问题
2.如果consumer的消费能力跟不上,则横向增加程序即可,瓶颈转移至DB的写压力上,基本达到目标
DB:
1.一个DB变为N个DB,分摊了写压力
2.在没有备份的情况下,数据同时不可读的概率就降低了
再来汇总一下图2的缺陷:
1.如何自动更新producer程序的配置
2.DB既然有写,肯定会有读,如果查询很频繁,或者单表数据很大,那么读写效率如何进一步进行优化
3.整套系统虽然容错性强了,依然处于无监控状态,比如producer全损坏了,无数据产生;
比如consumer损坏了,数据阻塞在rabbitmq;比如进程内存泄露等等;
4.如何做到系统自动提示需要扩容了?我们的终极目标就是尽量少的人工干预,解放大脑和眼睛
图3:进一步优化的模型
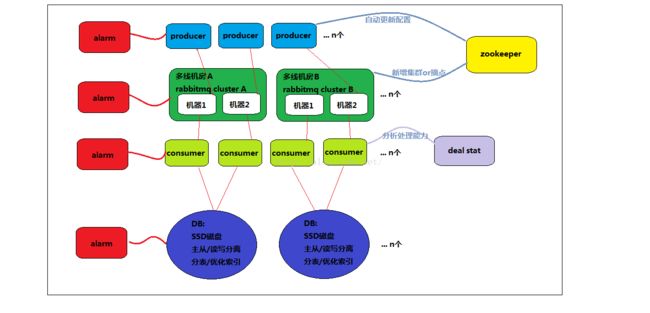
再来对比下图3比图2多了哪些组件:
1.引入zookeeper管理配置的更新
2.进一步优化了DB
3.引入了deal stat程序,分析系统的处理性能
4.引入了alarm程序监控系统
先来谈谈配置自动更新:
zookeeper可做到配置的自动分发至producer,也可以告知producer某个rabbitmq的节点坏掉了,可以摘掉,那么人工干预的成本就进一步降低了
再来谈谈DB的优化,这里对DB做了进一步的优化,采用SSD磁盘,主从化,读写分离,分表设计,优化索引,在这里只提一些很常规的优化手段。
deal stat程序有什么用,我们想一个问题,我们不可能经常去看系统的处理能力数据,那么瓶颈出现的时候我们怎么知道?这里引入deal stat主要是实时分析系统的处理能力,一旦达到我们设置的瓶颈,则通过邮件/短信/微信等各种手段通知程序维护者去处理,比如扩容。
最后再来谈alarm系统,可以说,一个没有告警机制的系统,本质上是个裸奔或者烂系统,不具备可维护性。
针对图3,我们可以想出很多种情况,假设我们的告警手段是邮件/短信/微信
1.内存/cpu占用异常,用crontab就可以做到定期检测,通知程序维护者并自动重启进程
2.DB磁盘空间达到阀值,通知程序维护者扩容
3.自动回滚压缩日志文件,磁盘空间总是有限的,不可能人工去rm,几千台机器怎么破,对吧
4.rabbitmq的队列过大,consumer处理能力不足,通知程序维护者
5.程序异常(僵死),比如consumer定期输出running状态的日志,一旦alarm程序发现一段时间没收集到该日志,则认为consumer异常,通知程序维护者
6.不一一举例了
图3总结:
1.要避免重要的进程出现单机运行的情况
2系统应该是容易扩展的,而不是遇到性能问题就要修改代码.
3.系统要处理各种异常情况,包括软硬件的问题
4.系统要进行监控,里里外外监视起来,并自动通知管理员
5.尽力减少人力去维护系统,一切都自动化,只需要点点鼠标就能把系统运营好
6.关注系统的数据指标,这是系统优化的数据基础
图3的缺陷:
DB由于业务的特性,数据不需要做一致性处理,但是并没有做到容灾处理,一旦某个节点的DB出现故障,仍然会影响系统的可用性
DB部分参考这个文章:支付宝的高可用与容灾演进