Zookeeper介绍
Zookeeper是一个分布式的开源系统,目的是为分布式应用提供协调一致性服务。分布式应用能够在Zookeeper提供的简单原语集之上构造更高层次的服务,例如统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。Zookeeper使用了类似文件系统的目录树结构的数据模型,帮助简化程序编写。
目前,一些知名的大数据开源框架就是利用了Zookeeper来完善分布式的协调一致性服务,例如HDFS的HA特性,HBase,Storm等。
架构
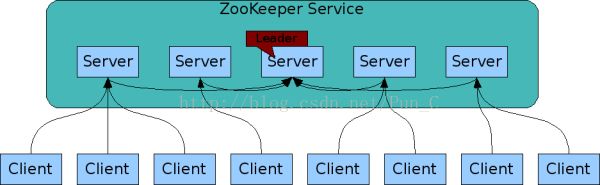
Zookeeper服务
作为一个分布式系统,Zookeeper自身也是由几台服务器之间复制相同的镜像状态对外提供服务。一台服务器必须知道其它所有的服务器的存在。服务器在内存保留了一份镜像状态,同时利用事务日志和快照保留在持久化存储中。只要大部分服务器能够正常工作,Zookeeper就处于可用状态。
一般客户端会连接其中一台Zookeeper服务器。客户端通过维持一个TCP连接,发送请求、获得相应、监控事件、还有心跳包。如果TCP连接失效,客户端会连接另外的服务器。
Zookeeper之间有Leader、Follower。通过选举算法选举出唯一的Leader以后,Leader就要负责对其它Follower进行状态同步,保证每台服务器的数据一致性。
数据模型

Zookeeper分层命名空间
Zookeeper提供的命名空间类似于规范的文件系统。一个命名就是用反斜杠分隔的路径元素序列。Zookeeper命名空间的每个节点都是用一个路径来区分的。
与规范的文件系统不同的是,Zookeeper命名空间中的每个节点(znode)都有数据关联。这些节点用来保存协调一致性数据:状态信息,配置,位置信息等,所以每个节点保存的数据一般都比较小,都在kb范围内。
Znode的读写操作都是原子性的。读操作会返回znode关联的所有数据,写操作会替换所有数据。每个节点都有ACL限制。
Zookeeper也有临时节点的概念。临时节点的生命周期和建立znode的会话保持一致。会话结束,临时节点就会被删除。
Zookeeper支持观察(watches)的功能。客户端在znode上设置一个watch事件,当znode改变的时候,一个watch事件就会被触发。
实现
原子广播(AtomicBroadcast)
Zookeeper的核心原理是通过原子性消息系统保证所有的服务器同步。该消息系统包括以下特性:
可依赖传递
如果消息m被服务器传递,它最终会被所有服务器传递过。
全序性
如果消息a在消息b之前传递在服务器上,则最终在所有服务器上,a都会在b之前传递过。
因果顺序
如果消息b在消息a之后被发送者b传递,a一定会在b的顺序之前。如果发送者发送b之后发送c,在c一定会在b的顺序之后。
Zookeeper在服务器之间建立了点对点的FIFO通道,通道是TCP通信,由于TCP的顺序性以及保证关闭后没有消息传递,另外为了保证在失败的时候保持一致性,使用了TCP的超时特性,当超时失效的时候,消息系统可能会被挂起,但不会破坏一致性。这样Zookeeper就保证了消息的全序性。
Zookeeper使用全局唯一的事务id(zxid)来区分每个消息(proposal),zxid是一个64位数字,高32位是时间戳,低32位是计数值。时间戳代表了Leader的改变,每次一个新的Leader选举出来时,就有自己的时间戳数值。Leader简单增加zxid的值设置到每个消息上。Leader选举算法会确保只有一个Leader使用特定的时间戳,这样就保证每个消息都会有唯一的id。
Zookeeper的消息传递包含两个主要的阶段:
Leader选举以及消息传递。
Leader选举
Leader选举算法较为复杂,主要是参考Paxos算法(经典的消息传递一致性算法)。大致有两种选举算法:LeaderElection和FastLeaderElection(AuthFastLeaderElection是FastLeaderElection变种,使用了UDP以及允许服务器使用简单的鉴权避免IP欺骗)。具体算法可以参考文章http://www.cnblogs.com/lpshou/archive/2013/06/14/3136738.html,这里不再赘述。
要注意的是,当选举出新的Leader后,Leader需要对Follower进行数据同步。Leader会发送Follower缺少的消息,如果一个Follower丢失太多消息,则Leader会发送一个全状态快照到Follower。
假设Follower有一个消息U,但并没有到达的Leader。由于消息是按顺序发送,因此消息U一定比Leader所访问过最大的zxid更大。这个时候当Follower连接到Leader的时候,Leader会告诉Follower丢弃U。
消息传递

客户端的读操作(查询和管理命令)只需要读取其中一台服务器的数据即可。写操作(create,setData,setAcl,delete,createSession,closeSession等)则较为复杂,正常情况下,
其中一台服务器收到客户端的写请求后,需要向Leader进行request,Leader就会对Follower广播修改请求(proposal),当超过一般数量的Follower(N/2 + 1)响应后(Ack),Leader则会提交(Submit)这个写请求,并且通知之前的服务器给客户端一个回应。从这里可以看出,写操作比读操作更加耗时,一般情况下,当读写操作约为10 : 1的时候,Zookeeper能够发挥最高性能。
以上所有的通信都是FIFO,所以事件都是有序的。特别是下面的操作必须有序:
- Leader发送proposals到所有的Follower使用相同的顺序。这个顺序按照请求被接收的顺序发送。
- Follower按照接收的顺序处理消息。因此消息会被有序地Acked并且Leader会接收到Followers的有序ACK。
- Leader会提交一个COMMIT到所有的Follower,当最低法定的Follower数返回ACKed消息。
- COMMIT会被有序地处理。所有的Followers都会在proposal提交之后传递proposal消息。
TheTao of ZooKeeper
关于为何这个分布式协调消息一致性系统被命名为ZooKeeper。官方有一篇很有意思的文章介绍,里面还包括了ZooKeeper设计的原则。这里截取一小部分:
ZooKeepers are dedicated to the animals theyare in charge of as well as the people that visit those animals. They areguided by a code, until now known only to those of their craft, that keep boththe animals and their visitors safe.
有兴趣可以到https://cwiki.apache.org/confluence/display/ZOOKEEPER/Tao阅读全文。
性能
关于Zookeeper的性能,官方给出了一些数据:
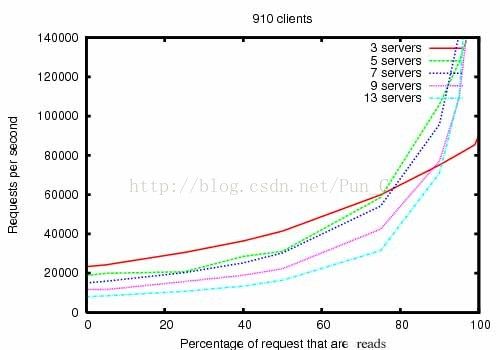
首先这个图里,横轴是在请求里读操作所占百分比,纵轴是每秒的处理的请求数RPS。从图可以明显看到,当读操作所占百分比越高,则Zookeeper的RPS也会相应提高。
另外,由于分布式系统的每个节点都有故障的可能性,假若运气不好,某个节点出现故障,则Zookeeper的性能会有如何影响呢?同样地,官方给出了以下的数据。

其中虚线代表发生了5个不同的故障:
1、Follower的故障和恢复
2、另一个Follower的故障和恢复
3、Leader的故障和恢复
4、两个Followers的故障和恢复
5、另一个Leader的故障和恢复
另外,这里的读操作保持30%的比例。
从图里可以看到,第一,Follower的故障和恢复很迅速,Zookeeper仍然能够保持一个较高的的吞吐量。第二,重要的是,Leader的选举算法能够保证足够快,避免吞吐量的急剧下降。从数据里看到,Zookeeper少于200ms去选举新的Leader。第三,当Follower恢复的时候,Zookeeper能够再次提升吞吐量。
总结
综上,Zookeeper作为一个分布式的协调消息一致性系统,能够为分布式应用提供高吞吐量、低延迟、高可用性、严格有序的消息一致性功能。充分利用好Zookeeper,就能避免分布式应用对于处理这类问题中常常容易出现的问题和错误。