Google图算法引擎Pregel介绍
参考文献点击打开链接
【前言:有一种说法[1]是Google的程序里面80%用的是MapReduce,20%用的是Pregel。今天就来介绍一下这个Pregel。想要深入研究的同志们,可以参考最新的SIGMOD 2010 ppt[2]。】
简介
Pregel是一个用于分布式图计算的计算框架,主要用于图遍历(BFS)、最短路径(SSSP)、PageRank计算等等。共享内存的运行库有很多,但是对于google来说,一台机器早已经放不下需要计算的数据了,所以需要分布式的这样一个计算环境。没有Pregel之前,你可以选择用MapReduce来做,但是效率很低;你也可以用已有的并行图算法库Parallel BGL或者CGMgraph来做,但是这两者又没有容错。所以google就自己开发了这个新的计算框架。
(八卦一下:Pregel的名字来历很有意思。是为了纪念欧拉的七桥问题[7],七座桥就位于Pregel这条河上。)
核心概念
从高层次看,Pregel是BSP[8]模型,就是“计算”-“通信”-“同步”的模式,参看图1。
- 输入输出为有向图
- 分成超步
- 以节点为中心计算,超步内每个节点执行自己的任务,执行节点的顺序不确定
- 两个超步之间是通信阶段

图1: BSP Model
在Pregel中,以节点为中心计算。Step 0时每节点都活动着,每个节点主动“给停止投票”进入不活动状态。如果接收到消息,则激活。没有活动节点和消息时,整个算法结束。
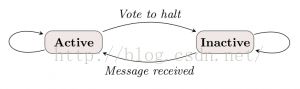
图2: Vetex State Machine(参考2)
容错是通过检查点来做的。在每个超步开始的时候,对主从节点分别备份。
核心的概念就是这些,其他还有一些消息聚集(combiner)等优化。有兴趣可以看看Lixiang的阅读笔记[6]和Pregel Slides[2]。
类似开源实现
人人都喜欢免费。跟Pregel最像的是Hama[5],也是基于BSP,但是,开源的Hama还未成气候。笔者原来打算拿它来做些实验,结果还不能运行。
国内似乎还没有类似Pregel的计算引擎,不知道百度和淘宝这些公司有没有需求。淘宝最近9月份开源了他们的文件系统TFS[3][4],很敬仰。不知道上面的运行环境是不是在开发中。大宋的开源软件也要有自己的创新,不能老是拿老外的改改就用了。
参考资料
1. Pregel: Google’s other data-processing infrastructure, http://www.royans.net/arch/pregel-googles-other-data-processing-infrastructure/
2. Pregel: A System for Large-Scale Graph Processing, SIGMOD 2010的ppt, http://www.slideshare.net/shatteredNirvana/pregel-a-system-for-largescale-graph-processing
3. 淘宝文件系统TFS开源代码,http://code.taobao.org/project/view/366/
4. 淘宝文件系统TFS介绍,http://rdc.taobao.com/blog/cs/?p=128
5. Hama homepage, http://incubator.apache.org/hama/
6. 论文阅读笔记:Google的图模型分布式计算框架Pregel
7. Seven Bridges of Königsberg, http://en.wikipedia.org/wiki/Seven_Bridges_of_K%C3%B6nigsberg
8. http://en.wikipedia.org/wiki/Bulk_synchronous_parallel