Python 应用剖析工具介绍
【编者按】本文作者为来自 HumanGeo 的工程师 Davis,主要介绍了用于 Python 应用性能分析的几个工具。由国内 ITOM 管理平台 OneAPM 编译呈现。
在 HumanGeo,我们广泛使用 Python 进行编程,并且乐趣无穷。用 Python 写的程序不仅整洁美观,而且运行速度快得惊人。不论是私底下还是工作中,Python 都是笔者最爱的语言。然而,即便是 Python 这样美妙的语言,却也可能出现运行缓慢的情况。幸运的是,有许多不错的工具,可以帮助我们分析 Python 代码,从而保证其运行效率。
当笔者刚开始在 HumanGeo 工作时,就曾遇到过一个运行一次耗时数小时的程序,而笔者的任务,就是找出其性能瓶颈,再尽可能地提高其运行效率。当时,笔者使用了许多工具,包括 cProfile, PyCallGraph(源码),甚至 PyPy(一个运行快速的 Python 解释器),以确定最佳的程序优化方案。在本文中,笔者将介绍上述工具(为了保持生产环境中的解释器一致性,本文将不会介绍 PyPy 工具)的使用方法。甚至即便是最老练的开发者,也可以借助这些工具进一步优化他们的代码。
免责声明:不要过早地进行优化!有关过早优化的详细分析请查阅本文。
工具
闲话少叙,下面开始介绍分析 Python 代码的几种便捷工具。
cProfile
CPython distribution 自带两种分析工具:profile 与 cProfile。两者使用同样的 API,按理说运行效果应该差不多。然而,前者的运行时开销更大,因此,本文将主要介绍 cProfile。
借助 cProfile,可以轻松实现对代码的深入分析,并且了解代码的哪些部分亟待提升。查看下面的缓慢代码实例:
--> % cat slow.py
import time
def main():
sum = 0
for i in range(10):
sum += expensive(i // 2)
return sum
def expensive(t):
time.sleep(t)
return t
if __name__ == '__main__':
print(main())
在上面的代码中,笔者通过调用 time.sleep 方法,模拟一个运行时间很长的程序,并假定运行结果很重要。接下来,对这段代码进行分析,结果如下:
--> % python -m cProfile slow.py
20
34 function calls in 20.030 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 __future__.py:48(<module>)
1 0.000 0.000 0.000 0.000 __future__.py:74(_Feature)
7 0.000 0.000 0.000 0.000 __future__.py:75(__init__)
10 0.000 0.000 20.027 2.003 slow.py:11(expensive)
1 0.002 0.002 20.030 20.030 slow.py:2(<module>)
1 0.000 0.000 20.027 20.027 slow.py:5(main)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
1 0.000 0.000 0.000 0.000 {print}
1 0.000 0.000 0.000 0.000 {range}
10 20.027 2.003 20.027 2.003 {time.sleep}
我们发现,分析结果相当琐碎。其实,可以用更有益的方式组织分析结果。在上例中,调用列表是按照字母顺序排列的,这对我们并无价值。笔者更愿意看到按照调用次数或累计运行时间排列的调用情况。幸运的是,通过 -s 参数就能实现这一点。我们马上就能看到存在问题的代码段了!
--> % python -m cProfile -s calls slow.py
20
34 function calls in 20.028 seconds
Ordered by: call count
ncalls tottime percall cumtime percall filename:lineno(function)
10 0.000 0.000 20.025 2.003 slow.py:11(expensive)
10 20.025 2.003 20.025 2.003 {time.sleep}
7 0.000 0.000 0.000 0.000 __future__.py:75(__init__)
1 0.000 0.000 20.026 20.026 slow.py:5(main)
1 0.000 0.000 0.000 0.000 __future__.py:74(_Feature)
1 0.000 0.000 0.000 0.000 {print}
1 0.000 0.000 0.000 0.000 __future__.py:48(<module>)
1 0.003 0.003 20.028 20.028 slow.py:2(<module>)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
1 0.000 0.000 0.000 0.000 {range}
果然!我们发现,存在问题的代码就在 expensive 函数当中。该函数在执行结束之前调用了多次 time.sleep 方法,因此导致了程序的速度下降。
-s参数的有效取值列表可以在此 Python 文档中找到。如果你想将分析结果保存到一个文件中,记得使用输出选项 -o。
基本功能介绍完毕之后,让我们来看看使用分析工具查找问题代码的其他方法。
PyCallGraph
PyCallGraph 可以看做是 cProfile 的可视化扩展工具。借助该工具,我们可以通过出色的 Graphviz 图片了解代码执行的路径。PyCallGraph 并未包含在标准的 Python 安装包内,因此,需要通过如下语句,进行简单的安装:
-> % pip install pycallgraph
通过下面的指令,就能运行图形化应用:
-> % pycallgraph graphviz -- python slow.py
运行完毕之后,在运行脚本的目录下会出现一张 pycallgraph.png 图片文件。同时,还应该得到相似的分析结果(如果你之前已经用 cProfile 分析过了)。结果中的数据应该与 cProfile 提供的结果一致。不过,PyCallGraph 的优点在于,它能展示被调用函数相互间的关系。
让我们来看看图片到底长什么样:
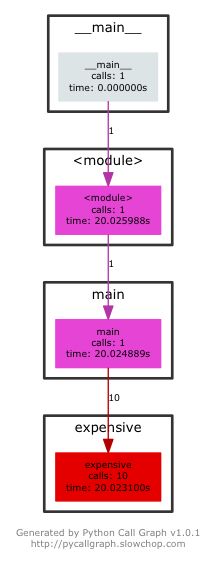
这多方便啊!图片显示了程序的运行路径,告诉我们程序经历过的每个函数、模块以及文件,还带有运行时间与调用次数等信息。如果在庞大的应用中运行该分析工具,会得到一张巨大的图片。但是,根据颜色的差别,我们仍能轻易找到存在问题的代码块。下面是 PyCallGraph 文档中提供的一张图片,展示了一段复杂的正则表达式调用中代码的运行路径:

点此获取此图分析的源码
这些信息有什么用?
一旦我们确定了导致问题代码的根源,就可以选择合适的解决方案优化代码,为其提速。下面,让我们根据特定的情况,探讨一些缓慢代码可行的解决方案。
I/O
如果你发现自己的代码严重依赖于输入/输出,譬如,需要发送很多 Web 请求,那么,Python 的标准线程模块或许就能帮你解决该问题。由于 CPython 的全局锁机制(Global Interpreter Lock,GIL)不允许为代码中心任务同时使用多个核,非 I/O 相关的线程并不适合用 Python 实现。
正则表达式
人们都说,一旦你决定用正则表达式解决某个问题,你就有两个问题要解决了。正则表达式真的很难用对,而且难以维护。关于这一点,笔者可以写一篇长篇大论进行阐述。(但是,我不会写的:)。正则表达式真的不简单,我相信有很多博文已经做了详尽的阐述。)不过,在此,笔者将介绍几个有用的技巧:
- 避免使用
.*,贪婪的匹配所有运算符运行起来非常慢,尽可能使用字符类才是更好的选择。 - 避免使用正则表达式!其实,许多正则表达式都可以用简单的字符串方法替代,比如
str.startswith与str.endswith
方法。阅读str文档可以找到更多有用的信息。 - 多使用
re.VERBOSE!Python 的正则表达式引擎非常强大,超级有用,一定要好好利用!
以上是有关正则表达式笔者想说的全部内容。如果你想要更多信息,相信网络上还有很多好的文章。
Python 代码
以笔者之前剖析过的代码为例,我们的 Python 函数会运行成千上万次以找出英文词的词根。该函数最迷人的地方在于,其进行的操作很容易缓存。保存函数的运行结果之后,代码的运行速度提升了整整十倍。而在 Python 中创建缓存是轻而易举的事情:
from functools import wraps
def memoize(f):
cache = {}
@wraps(f)
def inner(arg):
if arg not in cache:
cache[arg] = f(arg)
return cache[arg]
return inner
该技术名为记忆(memoization),在具体实现时会执行为装饰器,可轻易应用在 Python 函数中,如下所示:
import time
@memoize
def slow(you):
time.sleep(3)
print("Hello after 3 seconds, {}!".format(you))
return 3
现在,如果我们多次运行该函数,运行结果就会立即出现:
>>> slow("Davis")
Hello after 3 seconds, Davis!
3
>>> slow("Davis")
3
>>> slow("Visitor")
Hello after 3 seconds, Visitor!
3
>>> slow("Visitor")
3
对于该项目来说,这是极大的速度提升。而且代码运行起来也没有出现故障。
免责声明:请确保该方法只用于 pure 函数!如果将记忆(memoization)用于带有副作用(譬如:I/O)的函数,缓存可能无法达到预期的效果。
其他情况
如果你的代码无法使用记忆(memoization)技巧,你的算法也不像 O(n!) 这样疯狂,或者代码的剖析结果也没有引人注意的地方,这可能说明你的代码并不存在显著的问题。这时候,你可以尝试一下别的运行环境或语言。PyPy 就是一个好的选择,你可能还要将算法用C语言扩展方法重写一下。幸运的是,笔者之前的项目并未走到这一步,但是这仍是很好的排错方案。
结论
剖析代码可以帮助你理解项目的执行流程、找出潜在的问题代码,以及作为开发者该如何提升程序运行速度。Python 剖析工具不但功能强大,简单易用,而且足够深入以快速找出问题根源。虽然 Python 并不是以快速著称的语言,但这并不意味着你的代码应该拖拖拉拉。管理好自己的算法,适时进行剖析,但绝不要过早优化!
OneAPM 能够帮你查看 Python 应用程序的方方面面,不仅能够监控终端的用户体验,还能监控服务器性能,同时还支持追踪数据库、第三方 API 和 Web 服务器的各种问题。想阅读更多技术文章,请访问 OneAPM 官方技术博客。
本文转自 OneAPM 官方博客
原文地址:http://blog.thehumangeo.com/2015/07/28/profiling-in-python/