Web缓存机制综述(HTML5缓存总结与细节释疑)
[转]Web缓存机制综述(HTML5缓存总结与细节释疑)
开篇:
最近项目里用到了HTML5缓存机制,于是很想搞清楚 浏览器缓存,HTML5离线缓存,还有项目中用到的 CDN缓存 这三部分的关系以及更新机制。看了一堆关于HTML5缓存机制的文章,各有所长,各有疏漏。因此本人想在此做一总结,本文假设读者对基本的HTML5缓存应用已有所了解,因此不再详述概念,可以将本文当做释疑汇总吧。
以下部分内容引用自网络。
一、Web缓存的类型
在Web应用领域,Web缓存大致可以分为以下几种类型:
数据库数据缓存
Web应用,特别是SNS类型的应用,往往关系比较复杂,数据库表繁多,如果频繁进行数据库查询,很容易导致数据库不堪重荷。为了提供查询的性能,会将查询后的数据放到内存中进行缓存,下次查询时,直接从内存缓存直接返回,提供响应效率。比如常用的缓存方案有memcached等。
服务器端缓存
代理服务器缓存
代理服务器是浏览器和源服务器之间的中间服务器,浏览器先向这个中间服务器发起Web请求,经过处理后(比如权限验证,缓存匹配等),再将请求转发到源服务器。代理服务器缓存的运作原理跟浏览器的运作原理差不多,只是规模更大。可以把它理解为一个共享缓存,不只为一个用户服务,一般为大量用户提供服务,因此在减少相应时间和带宽使用方面很有效,同一个副本会被重用多次。常见代理服务器缓存解决方案有Squid等,这里不再详述。
CDN缓存
CDN(Content delivery networks)缓存,也叫网关缓存、反向代理缓存。CDN缓存一般是由网站管理员自己部署,为了让他们的网站更容易扩展并获得更好的性能。浏览器先向CDN网关发起Web请求,网关服务器后面对应着一台或多台负载均衡源服务器,会根据它们的负载请求,动态将请求转发到合适的源服务器上。虽然这种架构负载均衡源服务器之间的缓存没法共享,但却拥有更好的处扩展性。从浏览器角度来看,整个CDN就是一个源服务器,从这个层面来说,本文讨论浏览器和服务器之间的缓存机制,在这种架构下同样适用。
浏览器端缓存
浏览器缓存根据一套与服务器约定的规则进行工作,在同一个会话过程中会检查一次并确定缓存的副本足够新。如果你浏览过程中,比如前进或后退,访问到同一个图片,这些图片可以从浏览器缓存中调出而即时显现。
这里解释一下,HTML5时代所谓“浏览器”缓存有两部分:browser cache (浏览器缓存)和app cache(HTML5的离线应用缓存)后面会详细介绍。
Web应用层缓存
应用层缓存指的是从代码层面上,通过代码逻辑和缓存策略,实现对数据,页面,图片等资源的缓存,可以根据实际情况选择将数据存在文件系统或者内存中,减少数据库查询或者读写瓶颈,提高响应效率。
二、浏览器缓存与HTML5离线缓存
了解了Web缓存的组成,现在把重点放在项目中的HTML5缓存机制上。我们都知道HTML5没生出来以前,浏览器自身也是有缓存机制的,所以我得搞清楚现在它和HTML5离线缓存之间到底是如果调用和更新的。
缓存清单
引用清单文件
要启用某个应用的应用缓存,请在文档的 html 标记中添加 manifest 属性:
<html manifest="example.appcache">
...
</html>
您应在要缓存的网络应用的每个页面上都添加 manifest 属性。如果网页不包含 manifest 属性,浏览器就不会缓存该网页(除非清单文件中明确列出了该属性)。这就意味着用户浏览的每个包含manifest 的网页都会隐式添加到应用缓存。因此,您无需在清单中列出每个网页。
manifest 属性可指向绝对网址或相对路径,但绝对网址必须与相应的网络应用同源。清单文件可使用任何文件扩展名,但必须以正确的 MIME 类型提供
<html manifest="http://www.example.com/example.mf">
...
</html>
清单文件必须以 text/cache-manifest MIME 类型提供,且必须以UTF-8编码。您可能需要向网络服务器或 .htaccess 配置添加自定义文件类型。
例如,要在 Apache 中提供此 MIME 类型,请在您的配置文件中添加下面一行内容:(扩展名自定义)
AddType text/cache-manifest .appcache
另外,Web开发时,也可直接在web.xml中指定MIME类型:
<mime-mapping>
<extension>manifest</extension>
<mime-type>text/cache-manifest</mime-type>
</mime-mapping>
清单文件结构
CACHE MANIFEST
# the above line is required
# this is a comment
# there can be as many of these anywhere in the file
# they are all ignored
# comments can have spaces beforethem
# but must be alone on the line
# blank lines are ignored too
# these are files that need to be cached they can either be listed
# first, or a "CACHE:" header could be put before them, as isdone
# lower down.
images/sound-icon.png
images/background.png
# note that each file has to be put on its own line
# here is a file for the online whitelist -- it isn't cached, and
# references to this file will bypass the cache, always hitting the
# network (or trying to, if the user is offline).
NETWORK:
comm.cgi
# here is another set of files to cache, this time just the CSS file.
CACHE:
style/default.css
# static.html will be served if main.py is inaccessible# offline.jpg willbe served in place of all images in images/large/# offline.html will be servedin place of all other .html filesFALLBACK:/main.py /static.htmlimages/large/images/offline.jpg*.html /offline.html
以“#”开头的行是注释行,但也可用于其他用途。应用缓存只在其清单文件发生更改时才会更新。例如,如果您修改了图片资源或更改了 JavaScript 函数,这些更改不会重新缓存。您必须修改清单文件本身才能让浏览器刷新缓存文件。使用生成的版本号、文件哈希值或时间戳创建注释行,可确保用户获得您的软件的最新版。您还可以在出现新版本后,以编程方式更新缓存
CACHE:
这是条目的默认部分。系统会在首次下载此标头下列出的文件(或紧跟在 CACHE MANIFEST 后的文件)后显式缓存这些文件。
NETWORK:
此部分下列出的文件是需要连接到服务器的白名单资源。无论用户是否处于离线状态,对这些资源的所有请求都会绕过缓存。可使用通配符(这个用法很讲究)。
FALLBACK:
此部分是可选的,用于指定无法访问资源时的后备网页。其中第一个 URI 代表资源,第二个代表后备网页。两个 URI 必须相关,并且必须与清单文件同源。可使用通配符。
请注意:这些部分可按任意顺序排列,且每个部分均可在同一清单中重复出现。
请注意:系统会自动缓存引用清单文件的 HTML 文件。因此您无需将其添加到清单中,但我们建议您这样做。
请注意:HTTP 缓存标头以及对通过 SSL 提供的网页设置的缓存限制将被替换为缓存清单。因此,通过 https 提供的网页可实现离线运行。
这里有一种特例需要解释一下:
CACHE MANIFEST
FALLBACK:
/ /offline.html
NETWORK:
*
上面的代码定义了一个匹配所有的错误页offline.html,离线访问时,所有在同一域名下的页面都会应用到它。同时这段代码也指定了白名单通配符状态为打开(Open),意思是访问其他域名下的资源不会被阻塞。
白名单通配符*,有两种状态(是否使用) Open和 Blocking。
Open状态意思是所有未在CACHE中声明的URL都会被隐式认为属于NETWORK;
Blocking状态意思是所有未明确地在manifest文件中声明的URL都会被认为不可用(unavailable.),都将不能访问。
使用了NETWORK的通配符“*”,只要你有网络连接,任何不在应用程序缓存中的资源将仍然从原网络地址下载,这对开放的应用程序非常重要。这意味着浏览器可以获取各种资源,即使它们和你的应用程序不在同一个域名下。如果没有此通配符,当你在线时,我们设想支持离线的应用将会行为诡异——它将不会加载任何不同域名下的资源。
事件流
当用户访问一个声明了manifest的页面时,浏览器会尝试获取一份manifest文件的拷贝,如果发现有更新,则下载该manifest文件中声明的所有资源并重新缓存它们。
同时,这将触发一系列事件,如下所示:
| Event name |
Interface |
Fired when... |
Next events |
| checking |
Event |
The user agent is checking for an update, or attempting to download the manifest for the first time.This is always the first event in the sequence. |
noupdate,downloading,obsolete,error |
| noupdate |
Event |
The manifest hadn't changed. |
Last event in sequence. |
| downloading |
Event |
The user agent has found an update and is fetching it, or is downloading the resources listed by the manifest for the first time. |
progress,error,cached,updateready |
| progress |
ProgressEvent |
The user agent is downloading resources listed by the manifest. The event object'stotal attribute returns the total number of files to be downloaded. The event object'sloaded attribute returns the number of files processed so far. |
progress,error,cached,updateready |
| cached |
Event |
The resources listed in the manifest have been downloaded, and the application is now cached. |
Last event in sequence. |
| updateready |
Event |
The resources listed in the manifest have been newly redownloaded, and the script can useswapCache() to switch to the new cache. |
Last event in sequence. |
| obsolete |
Event |
The manifest was found to have become a 404 or 410 page, so the application cache is being deleted. |
Last event in sequence. |
| error |
Event |
The manifest was a 404 or 410 page, so the attempt to cache the application has been aborted. |
Last event in sequence. |
| The manifest hadn't changed, but the page referencing the manifest failed to download properly. |
|||
| A fatal error occurred while fetching the resources listed in the manifest. |
|||
| The manifest changed while the update was being run. |
The user agent will try fetching the files again momentarily. |
这些事件都是可取消的,它们的目的是让浏览器显示下载进度信息。但如果你要显示自己的更新UI,那么取消这些事件会避免显示冗余的用户进度信息。
更新机制
应用在离线后将保持缓存状态,除非发生以下某种情况:
1. 用户清除了浏览器对您网站的数据存储。
2. 清单文件经过修改。请注意:更新清单中列出的某个文件并不意味着浏览器会重新缓存该资源。清单文件本身必须进行更改。
3. 应用缓存通过编程方式进行更新。
缓存状态
window.applicationCache 对象是对浏览器的应用缓存的编程访问方式。其 status 属性可用于查看缓存的当前状态:
var appCache = window.applicationCache;
switch (appCache.status) {
case appCache.UNCACHED: //UNCACHED == 0
return 'UNCACHED';
break;
case appCache.IDLE: // IDLE == 1
return 'IDLE';
break;
case appCache.CHECKING: //CHECKING == 2
return 'CHECKING';
break;
case appCache.DOWNLOADING: //DOWNLOADING == 3
return 'DOWNLOADING';
break;
case appCache.UPDATEREADY: // UPDATEREADY == 4
return 'UPDATEREADY';
break;
case appCache.OBSOLETE: //OBSOLETE == 5
return 'OBSOLETE';
break;
default:
return 'UKNOWN CACHE STATUS';
break;
};
要以编程方式更新缓存,请先调用 applicationCache.update()。此操作将尝试更新用户的缓存(前提是已更改清单文件)。最后,当applicationCache.status 处于UPDATEREADY 状态时,调用 applicationCache.swapCache() 即可将原缓存换成新缓存。
var appCache = window.applicationCache;
appCache.update(); // Attempt to update the user's cache.
...
if (appCache.status == window.applicationCache.UPDATEREADY) {
appCache.swapCache(); // The fetch was successful, swap in the newcache.
}
请注意:以这种方式使用 update() 和 swapCache() 不会向用户提供更新的资源。此流程只是让浏览器检查是否有新的清单、下载指定的更新内容以及重新填充应用缓存。因此,还需要对网页进行两次重新加载才能向用户提供新的内容,其中第一次是获得新的应用缓存,第二次是刷新网页内容。
好消息是,您可以避免重新加载两次的麻烦。要使用户更新到最新版网站,可设置监听器,以监听网页加载时的 updateready 事件:
// Check if a new cache is available on page load.
window.addEventListener('load', function(e) {
window.applicationCache.addEventListener('updateready', function(e) {
if(window.applicationCache.status == window.applicationCache.UPDATEREADY) {
// Browser downloaded a newapp cache.
// Swap it in and reload thepage to get the new hotness.
window.applicationCache.swapCache();
if (confirm('A new version ofthis site is available. Load it?')) {
window.location.reload();
}
} else {
// Manifest didn't changed.Nothing new to server.
}
}, false);
}, false);
更新流程示意图
它们各自的更新机制如下:

Browser cache
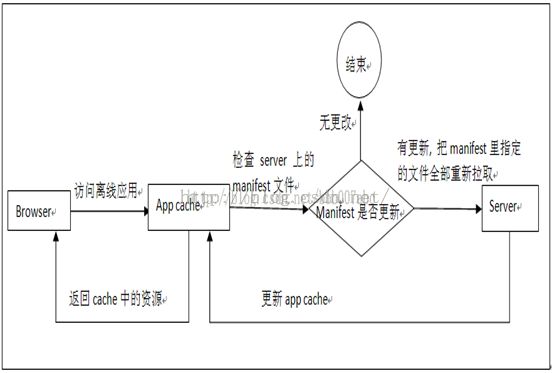
App cache
其中browser cache的机制大家都很清楚了, 其中离线应用的更新是: 除了第一次访问是直接拉取server的, 然后后台更新app cache之外, 其余的情况都是直接访问app cache. 因此, 要如果离线应用的代码更新了, 只有下次打开或者刷新才会生效.。
三、浏览器缓存的控制
使用HTML Meta 标签
Web开发者可以在HTML页面的<head>节点中加入<meta>标签,代码如下:
<META HTTP-EQUIV="Pragma" CONTENT="no-cache">
上述代码的作用是告诉浏览器当前页面不被缓存,每次访问都需要去服务器拉取。使用上很简单,但只有部分浏览器可以支持,而且所有缓存代理服务器都不支持,因为代理不解析HTML内容本身。
可以通过这个页面测试你的浏览器是否支持:Pragma No-Cache Test 。
使用缓存有关的HTTP消息报头
一个URI的完整HTTP协议交互过程是由HTTP请求和HTTP响应组成的。有关HTTP详细内容可参考《Hypertext Transfer Protocol — HTTP/1.1》、《HTTP协议详解》等。
在HTTP请求和响应的消息报头中,常见的与缓存有关的消息报头有:
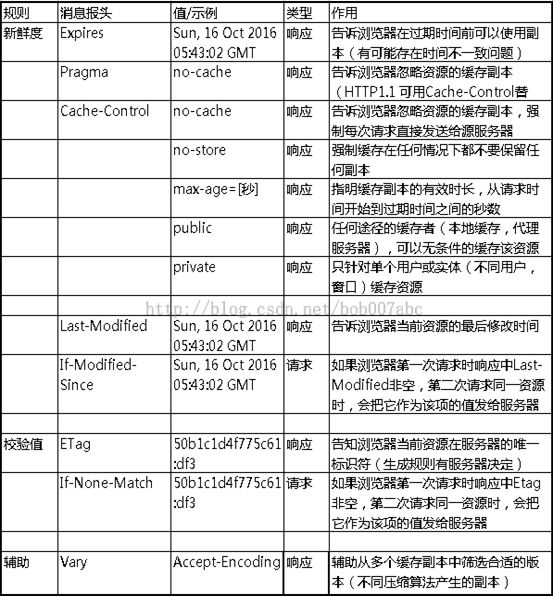
Cache-Control与Expires
Cache-Control与Expires的作用一致,都是指明当前资源的有效期,控制浏览器是否直接从浏览器缓存取数据还是重新发请求到服务器取数据。只不过Cache-Control的选择更多,设置更细致,如果同时设置的话,其优先级高于Expires。
Last-Modified/ETag与Cache-Control/Expires
配置Last-Modified/ETag的情况下,浏览器再次访问统一URI的资源,还是会发送请求到服务器询问文件是否已经修改,如果没有,服务器会只发送一个304回给浏览器,告诉浏览器直接从自己本地的缓存取数据;如果修改过那就整个数据重新发给浏览器;
Cache-Control/Expires则不同,如果检测到本地的缓存还是有效的时间范围内,浏览器直接使用本地副本,不会发送任何请求。两者一起使用时,Cache-Control/Expires的优先级要高于Last-Modified/ETag。即当本地副本根据Cache-Control/Expires发现还在有效期内时,则不会再次发送请求去服务器询问修改时间(Last-Modified)或实体标识(Etag)了。
一般情况下,使用Cache-Control/Expires会配合Last-Modified/ETag一起使用,因为即使服务器设置缓存时间, 当用户点击“刷新”按钮时,浏览器会忽略缓存继续向服务器发送请求,这时Last-Modified/ETag将能够很好利用304,从而减少响应开销。
Last-Modified与ETag
你可能会觉得使用Last-Modified已经足以让浏览器知道本地的缓存副本是否足够新,为什么还需要Etag(实体标识)呢?HTTP1.1中Etag的出现主要是为了解决几个Last-Modified比较难解决的问题:
1. Last-Modified标注的最后修改只能精确到秒级,如果某些文件在1秒钟以内,被修改多次的话,它将不能准确标注文件的新鲜度
2. 如果某些文件会被定期生成,当有时内容并没有任何变化,但Last-Modified却改变了,导致文件没法使用缓存
3. 有可能存在服务器没有准确获取文件修改时间,或者与代理服务器时间不一致等情形
Etag是服务器自动生成或者由开发者生成的对应资源在服务器端的唯一标识符,能够更加准确的控制缓存。Last-Modified与ETag是可以一起使用的,服务器会优先验证ETag,一致的情况下,才会继续比对Last-Modified,最后才决定是否返回304。Etag的服务器生成规则和强弱Etag的相关内容可以参考,《互动百科-Etag》和《HTTP Header definition》,这里不再深入。
用户操作行为与缓存
用户在使用浏览器的时候,会有各种操作,比如输入地址后回车,按F5刷新等,这些行为会对缓存有什么影响呢?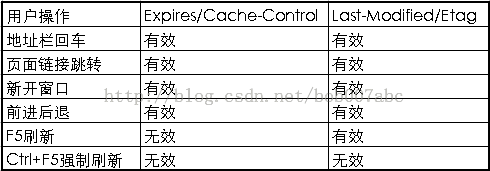
通过上表我们可以看到,当用户在按F5进行刷新的时候,会忽略Expires/Cache-Control的设置,会再次发送请求去服务器请求,而Last-Modified/Etag还是有效的,服务器会根据情况判断返回304还是200;而当用户使用Ctrl+F5进行强制刷新的时候,只是所有的缓存机制都将失效,重新从服务器拉去资源。
相关有趣的分享:
《浏览器缓存机制》:不同浏览器对用户操作行为处理比较 (强烈推荐此文)
《HTTP304客户端缓存优化的神奇作用和用法》:强行在代码层面比对文件的Last-Modified时间,保证用户使用Ctrl+F5进行刷新的时候也能正常返回304
四、为什么有时候你的缓存不能如你所愿及时更新
这段标红,因为这个才是我全文的重点。
以上分析了浏览器缓存和HTML5离线缓存各自的更新机制。那么,当我们同时使用了浏览器缓存和HTML5的离线缓存,结果会是怎样的呢?看图: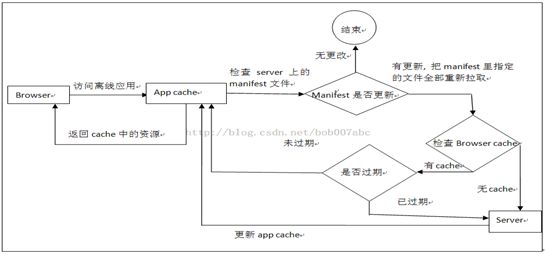
看得出来,浏览器自身的缓存对离线缓存的更新有干扰,如果你的资源曾经被cache过,那么只有你的服务器manifest有更新且在浏览器自身缓存过期的情况下,服务器才会真正去服务器重新下载资源。不过这里要知道的是,如果用户强制刷新(Ctrl+F5),那浏览器自身的缓存就失效被跳过了,浏览器会直接对比本地的manifest并判断是否有更新来决定是否发送请求到服务器重新下载资源。
过程如下:
1. 通过标准的HTTP语义,你的浏览器将会检测缓存名单是否已经过期。就像任何其他由HTTP服务的文件,你的网络服务器将会包含典型的关于此文件在HTTP响应头中的元信息。这些HTTP头中的一些(Expires和Cache-Control)将告诉你的浏览器如何允许缓存文件而不询问服务器此文件是否已更改。此种类型的缓存和离线网络应用程序没有任何关系。它发生在几乎每个HTML页面,样式表,图片或者其他网络资源。
2. 如果缓存名单已过期(根据它的HTTP头),那么你的浏览器将会询问服务器是否有新版本,如果有,浏览器将会下载它。要做到这一点,你的浏览器产生一个包含此缓存名单last-modified数据的HTTP请求,你的网络服务器将浏览器下载名单文件的最后时间包含在HTTP响应头中。如果网络服务器判断从那个时间之后没有被更改,它将简单的返回一个304(未改变)状态。同样的,这不是离线网络应用程序所特有的。它发生于实质上每种类型的网络资源。
3. 如果网络服务器认为名单文件在那个时间之后有被更改,它将返回一个200(OK)HTTP状态码,后面是新文件的内容和新的Cache-Control头,以及一个新的last-modified时间,因此,第1步和第2步将可能在下次发生。(HTTP非常酷,网络服务器总是为将来做打算。如果你的网络服务器绝对需要给你传送一个文件,他尽所有可能确认他不需要无故传送第二次。)一旦下载了新的缓存名单文件,你的浏览器将根据它上次下载的副本检测内容。如果缓存名单文件的内容跟上次的一样,你的浏览器将不会重新下载此名单中列出的任何资源。
当你开发和测试你的离线网络应用程序时,这些步骤的任意一个都可能让你犯错误。例如,比如说你发布了一个新版本的缓存名单文件,10分钟后,你发现你需要在里面添加另一个资源。没问题,对吧?仅仅添加另一行并重新发布。这是将要发生的事情:你重新载入页面,你的浏览器发现了manifest属性,它触发了checking事件,然后…没啥了。你的浏览器坚持认为缓存名单文件并没有被更改。为啥?因为你的网络服务器可能由于默认配置,告诉浏览器需要缓存静态文件几个小时(通过HTTP语义,使用Cache-Control头)。这意味着你的浏览器将不会通过三相进程中的第1步。当然,网络服务器知道文件已经更改,但你的浏览器甚至不会有足够的时间去询问网络服务器。为啥?因为你的浏览器上次下载了缓存名单,网络服务器告诉它需要缓存这个资源几个小时(通过HTTP语义,使用Cache-Control头)。那么10分钟后,这就是你的浏览器确切会做的事情。
你必须清楚,这不是错误,而只是个特性。一切都按照它应该的方式工作着。如果网络服务器没有办法告诉浏览器(和中间代理)去缓存资源,网络可能很快崩溃。但没人来安慰你花上几个小时去尝试想出为啥你的浏览器没有注意到你更新过的缓存名单。(实际上,如果你等待得足够久,它将神秘重新开始工作!因为HTTP缓存过期了!就像它应该的那样!)
所以,这儿有一件你必须要做的事情:重新配置你的网络服务器,以便你的缓存名单文件不会因为HTTP语义而可缓存。如果你使用基于Apache的网络服务器,你.htaccess文件中的这两行将会达到目的:
ExpiresActive On
ExpiresDefault “access”
这将会使每一个在此目录和所有其子目录中的文件缓存失效。这可能是你在制作中所不希望的,所以你应该使用一个<Files>指令来限制它,以致其只对你的缓存名单文件有效,或者创建一个只包含这个.htaccess文件和缓存名单文件的子目录。通常,配置细节随网络服务器而变化,所以查阅你的服务器说明文档来确认如何控制HTTP缓存头。
一旦你使缓存名单文件本身的HTTP缓存失效,你将仍然看到过时的却已在应用程序缓存中更改的某个资源,只因为它仍然以相同的URL存在于你的网络服务器。这里,三相进程中的第2步将会欺骗你。如果你的缓存名单文件没有被更改,浏览器将不会注意到之前缓存的某个资源已被更改。
五、哪些请求不能被缓存?
无法被浏览器缓存的请求:
1. HTTP信息头中包含Cache-Control:no-cache,pragma:no-cache,或Cache-Control:max-age=0等告诉浏览器不用缓存的请求
2. 需要根据Cookie,认证信息等决定输入内容的动态请求是不能被缓存的
3. 经过HTTPS安全加密的请求(有人也经过测试发现,ie其实在头部加入Cache-Control:max-age信息,firefox在头部加入Cache-Control:Public之后,能够对HTTPS的资源进行缓存,参考《HTTPS的七个误解》)
4. POST请求无法被缓存
5. HTTP响应头中不包含Last-Modified/Etag,也不包含Cache-Control/Expires的请求无法被缓存
六、CDN缓存
一般情况下浏览器缓存和HTML5离线缓存已经可以为你省一大笔网络开销了,但大型网络应用还会用到CDN(比如我们的项目)。
凡是项目中应用到的所有资源JS,CSS,image,audio我们都直接去访问CDN,不是其背后的服务器。在用户第一次访问页面时,会直接产生浏览器缓存与CDN服务器缓存两个拷贝,它们同时存在且URI都是一样的。恶心的地方来了,如果你不想办法让CDN缓存在需要更新时失效,那即使浏览器缓存过期,浏览器读取的还会是老数据,它来自于CDN缓存。所以这个时候如果你的资源没更新,要同时检查三个地方的缓存是否都正常更新。
好在项目中我们用路径中加入随机码的机制来使CDN缓存在需要更新时失效(http://cdn/path/to/xxxxx/the/resource.png),该随机码并非真随机,是由各个资源的MD5编码计算来的。资源如有更新,MD5值同时更新,这样在manifest中的资源路径就和上一次完全不同了,所以一旦浏览器缓存过期,访问CDN时,CDN找不到相应路径,就会去服务器去拿同时缓存在其本地, 以后再访问就从缓存中拿。