XML DOM解析 基础概念
DOM和SAX
W3C制定了一套书写XML分析器的标准接口规范——DOM。
除此以外,XML_DEV邮件列表中的成员根据应用的需求也自发地定义了一套对XML文档进行操作的接口规范——SAX。
这两种接口规范各有侧重,互有长短,应用都比较广泛。
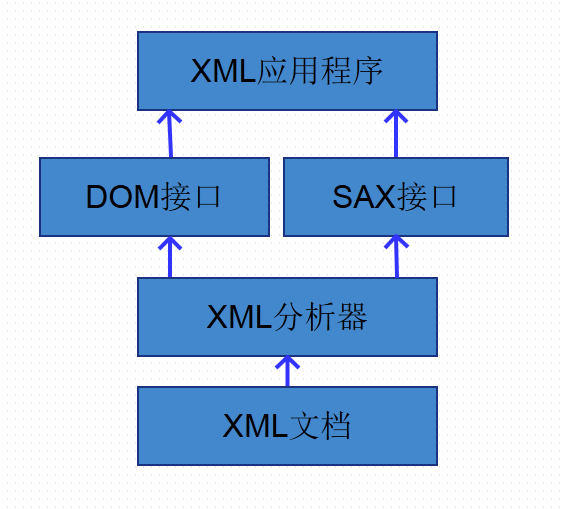
应用程序开发过程中,应用程序不是直接对XML文档进行操作的,而是首先由XML分析器对XML文档进行分析。
然后,应用程序通过XML分析器所提供的DOM接口或SAX接口对分析结果进行操作,从而间接地实现了对XML文档的访问。
DOM介绍 优缺点分析
DOM: Document Object Model 文档对象模型。
在应用程序中,基于DOM的XML分析器将一个XML文档转换成一个对象模型的集合(通常称DOM树),应用程序通过对这个对象模型的操作,来实现对XML文档数据的操作。
通过DOM接口,应用程序可以在任何时候访问XML文档中的任何一部分数据,因此,这种利用DOM接口的机制也被称作随机访问机制。
DOM树所提供的随机访问方式给应用程序的开发带来了很大的灵活性,它可以任意地控制整个XML文档中的内容。
然而,由于DOM分析器把整个XML文档转化成DOM树放在了内存中,因此,当文档比较大或结构比较复杂时,对内存的需求就比较高。
而且,对于结构复杂的树的遍历也是一项耗时的操作。
所以,DOM分析器对机器性能的要求比较高,实现效率不十分理想。
由于DOM分析器所采用的树结构的思想与XML文档的结构相吻合,同时鉴于随机访问所带来的方便,因此,DOM分析器还是有很广泛的应用价值的。
DOM的组成
对于XML应用开发来说,DOM就是一个对象化的XML数据接口,一个与语言无关、与平台无关的标准接口规范。
DOM定义了HTML文档和XML文档的逻辑结构,给出了一种访问和处理这两种文档的方法。
文档代表的是数据,而DOM则代表了如何去处理这些数据。
作为W3C的标准接口规范,目前,DOM由三部分组成,包括:核心(core)、HTML接口和XML接口。
核心部分是结构化文档比较底层对象的集合,这一部分所定义的对象已经完全可以表达出任何HTML和XML文档中的数据了。
HTML接口和XML接口两部分则是专为操作具体HTML文档和XML文档所提供的高级接口。
DOM树
一个XML文档及其所对应的DOM树如下:
<?xml version="1.0" encoding="utf-8"?> <bookstore> <book category="children"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book category="cooking"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> <book category="web"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> <book category="web"> <title lang="en">XQuery Kick Start</title> <author>James McGovern</author> <author>Per Bothner</author> <author>Kurt Cagle</author> <author>James Linn</author> <author>Vaidyanathan Nagarajan</author> <year>2003</year> <price>49.99</price> </book> </bookstore>

要严格区分XML文档树中的根节点与根元素节点:
文档(根节点)和根元素节点是两回事。
根节点代表整个文档,是我们解析XML文档的入口,通过它获取到Document对象;
根元素节点代表XML文档的根元素,必须要在获得Document对象之后才能一层一层地去访问它的元素。
DOM模型结构
最常见的节点类型:
元素:元素是XML的基本构建。
元素可以有其他元素、文本节点或两者兼有来作为其子节点。
元素节点还是可以有属性的唯一类型的节点。
属性:属性节点包含关于元素节点的信息,但实际上,不认为它是元素的子节点。
文本:确切来讲,文本节点是文本。它可以包含许多信息或仅仅是空白。
文档(根节点) :文档节点是整个文档中所有其他节点的父节点。(根节点不等于根元素节点)。
较不常见的节点类型:CDATA、注释、处理指令。
DOM的四个基本接口
在DOM接口规范中,有四个基本的接口:Document, Node, NodeList, NamedNodeMap。
Document
Document接口是对文档进行操作的入口,它是从Node接口继承过来的。
Node
Node接口是其他大多数接口的父类。
在DOM树中,Node接口代表了树中的一个节点。
NodeList
NodeList接口是一个节点的集合,它包含了某个节点中的所有子节点。
它提供了对节点集合的抽象定义,并不包含如何实现这个节点集的定义。
NodeList用于表示有顺序关系的一组节点,比如某个节点的子节点序列。
在DOM中,NodeList的对象是live的,对文档的改变,会直接反映到相关的NodeList对象中。
NamedNodeMap
NamedNodeMap接口也是一个节点的集合,通过该接口,可以建立节点名和节点之间的一一映射关系,从而利用节点名可以直接访问特定的节点,这个接口主要用在属性节点的表示上。
尽管NamedNodeMap所包含的节点可以通过索引来进行访问,但是这只是提供了一种枚举方法,NamedNodeMap所包含的节点集中节点是无序的。
与NodeList相同,在DOM中,NamedNodeMap对象也是live的。
解析器基础
XML解析器实际上就是一段代码,它读入一个XML文档并分析其结构。
分类:
带校验的解析器。
不带校验的解析器。
支持DOM的解析器(W3C的官方标准)
支持SAX的解析器(事实上的工业标准)
参考资料
圣思园张龙老师XML视频教程。
w3school XML DOM 教程:
http://www.w3school.com.cn/xmldom/index.asp
Java API文档:
http://docs.oracle.com/javase/7/docs/api/index.html