Flume安装
最近实验室在搞storm流计算处理广告异常方面的学习。
思路就是“Flume+Kafka+storm”平台,其中Flume可以模拟数据源发送源源不断的流数据,Kafka是个类似缓冲机制的东西,有生产者和消费者接口,分别与上流的Flume和下流的storm交互,storm平台则从Kafka取得数据处理。

![]()
![]()
![]()
![]()
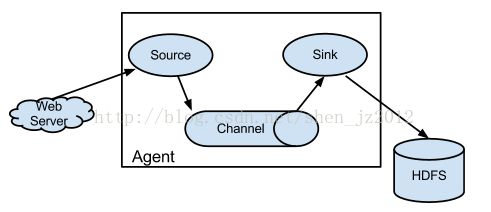
Flume的安装非常简单,去到官网看一张图可以迅速又深刻的理解它的概貌:
Agent是它的最小处理单位,在处理每一个Agent的时候,你必须按照conf目录下提供的模板文件来设计你的angent,里面的参数包括设置上述的source,channel,sink。数据源关联的对象也非常丰富,可以是本地文件,可以是分布式系统文件,也可以是avro对象以及其他,具体的测试在这篇文章中有提到 http://idoall.org/home.php?mod=space&uid=1&do=blog&id=550 ,或者去官方的wiki找到更多详细的配置:http://flume.apache.org/FlumeUserGuide.html
1、到官网下载页面 http://flume.apache.org/download.html 下载版本,然后解压到自定义的文件夹下。
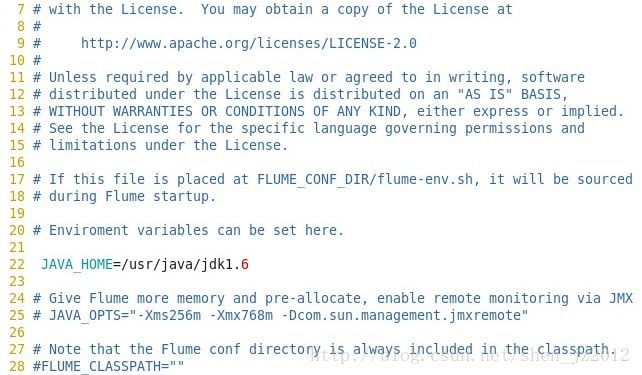
2、修改conf目录下的flume-env.sh文件,主要是修改java的目录路径就可以了,可选的是jvm的内存参数那些:
然后检测一下是否安装成功:
3、测试。
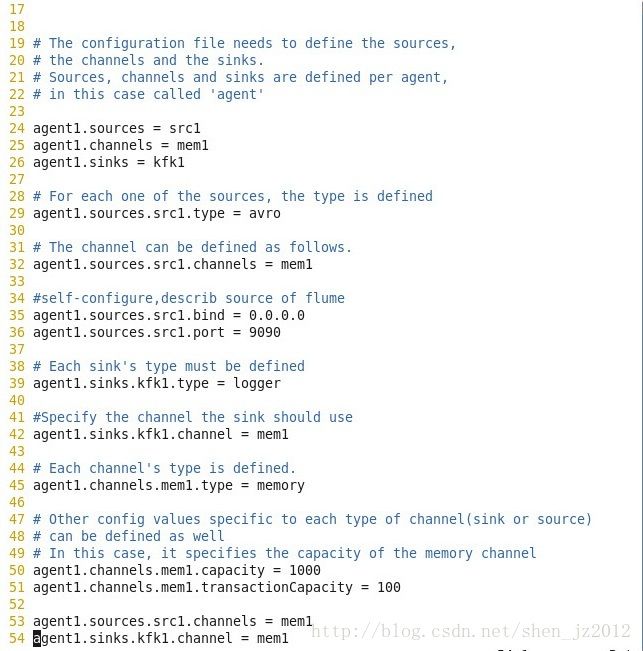
首先,给你的angent设计一个配置文件。我使用的如下:
24~25行分别定义了sources,channels,和sinks的名字。
29~36定义了该sources的具体配置,指定type为avro,让它通过avro的RPC机制读取avro对象作为数据源;sources的channels类型指定为刚才我们命名为mem1的channels(联想一下刚才Agent的内部结构图,很好理解)
39~42行定义了sinks的具体配置,作为angent的输出端。指定type类型为logger;channel的值指定为刚才定义好的mem1。
45~51定义了channels的具体配置,主要指定type的类型为memory内存,这样,整个的数据流有点类似从avro对象输入到内存,然后sinks端从内存中再读取出来。
53~54是将三者关联起来,可能跟上述有些地方做了重复的工作。
补充一下,这个agent的名字叫做“agent1”,就是每行的第一个字段,可以自定义。该命名在你发送数据或者其他工作的时候要用到。
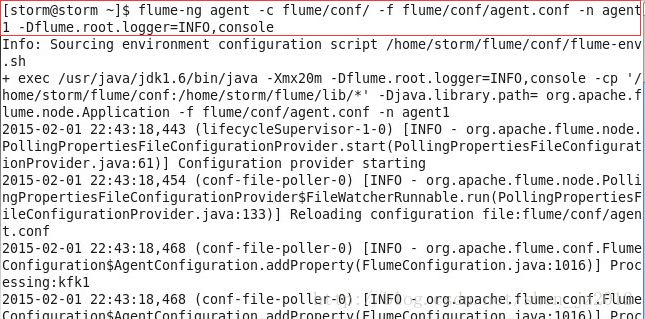
定义好agent的配置文件之后,启动这个agent:
你可以在终端键入flume-ng,这样就会有提示各个参数的意义。其中:
agent:表明要运行一个跟agent有关的命令
-c :即configuration,后面接flume配置文件目录的路径
-f :后面接要运行的agent的配置文件。在本例中是上述我们配置的agent.conf
-n :即name,后面接你要运行的agent的名字,本例中是我们在配置文件中命名的angent1
最后一个参数表明将输出端设置为控制台,并只输出INFO级别的日志。
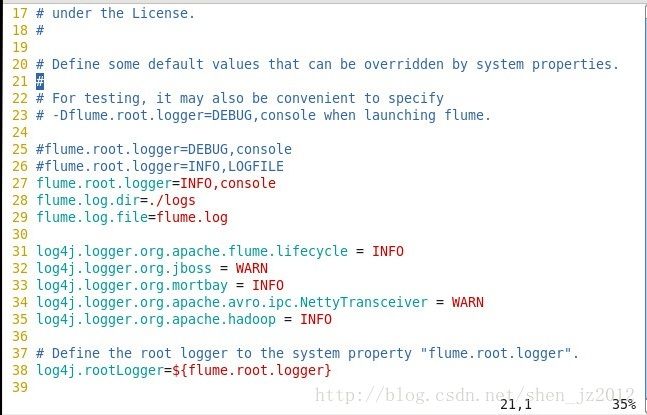
PS:之前在启动agent的时候老是失败,查找日志修改过后没有bug,但是运行结果老是没有打印在控制台console上,后来根据日志排错修改conf目录下的log4j.properties配置,运行成功。
原来配置是第26行,注意到它的输出是到一个叫做“LOGFILE”的端,这里修改为27行的console就可以了。
现在在flume目录下有一个叫做testLog.txt的文件,里面写着“hello world, flume”。另一个终端使用avro-client发送文件。
各参数的意义如下:
-H :指定主机名,本例中是storm
-p :指定的端口号,就是刚才在agent.conf文件中配置的端口号,本例为9090
-F :指定要发送的文件,也即刚才的testLog.txt文件
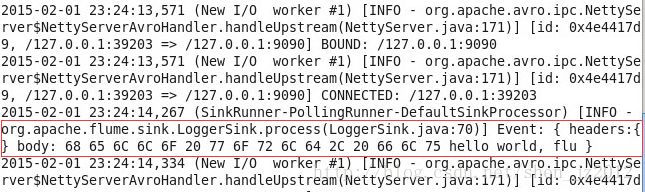
回到启动agent的那个终端可以看到结果。
这样Flume就算是安装完成了。
PS:可以看到的发送的数据并不完整hello world, flu,只能显示16个字节,但是在实际中发送数据正常情况下并没有丢失。