spark集群参数配置理解
一、spark-env.sh
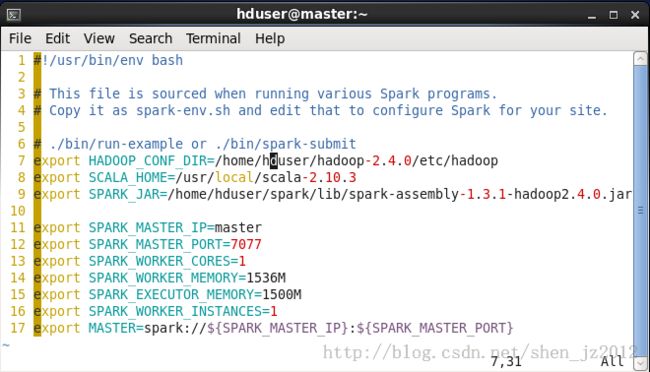
图1 我自己的配置文件spark-env.sh
line 7中指定hadoop安装目录的配置路径,如果不配置这一项,就要把${HADOOP_HOME}/etc/hadoop下的所有xml文件拷贝到${SPARK_HOME}/conf下,而且不保证正确,所以最好配置这一项。
line 9中如果不配置,在运行spark-submit的时候需要用--jars参数指定这个依赖的jar文件。
line13每个worker需要的core数
line14是指分配给运行在worker节点上的worker进程的内存大小
line15是指分配给在worker进程中executor的内存大小,系统默认是512M。之前一直迷惑为什么我worker进程配置了1G,但是在web ui上观察到的是1024M/512M used,就是这个原因。
line16是指worker进程的数目,如果你设置为2,那么在每个worker节点启动的进程数就是2。
因此,生成的executoer的总个数为num = worker节点数 X worker_instances数(worker进程数)X executor数(截图中没配置,即SPARK_EXECUTOR_INSTANCES,默认为2)。
上面三行都要根据具体的worker节点的物理硬件的限度来配置,超过这个限度任务就启动不起来。按照我的理解,上述三者的关系可用下图来解释。

图2
executor是worker里的线程,被限制用可用的cpu core数来执行。
另外在运行spark-submit或者中另一个叫做spark-defaults.con.template的配置文件中,有一项driver_memory。这个首先就要理解我是用过的spark程序的两大类四小种(实际上肯定不止)运行模式了。
两大类是指spark standalone模式和yarn,其实官网上还有一种叫做mesos的部署模式,模式上跟yarn的应该差不多,但原理没去了解,另外还有部署在amazon ec2上的,这后面两个都没亲手测试过,不谈了。,
四小种是指如下:
在standalone下,可分为1)local模式,用本地的线程代替worker进程。2)spark集群,用--master指定spark集群的master节点(其实上面说的mesos部署模式就是用mesos集群代替spark集群,将mesos集群的master节点指定给--master参数)
在yarn模式下,spark系统会将application丢给yarn集群去处理,因此我们强调一定要在图1中的line7示例的配置hadoop集群的信息。然后yarn模式下又根据driver程序是在本地提交还是提交到远程集群分为3)yarn-clien和4)yarn-cluster。因此,driver_memory参数的配置只针对yarn模式下有效,对standalone无效。更具体的,还有例子,可以看看这篇博文《Spark1.0.0 应用程序部署工具spark-submit》
发
二、yarn-cluster和yarn-client
按照对官网上两种模式描述的理解,我绘制如下图:
In yarn-cluster mode
, the Spark driver runs
inside an application master process
which is managed by YARN on the cluster, and the
client can go away
after initiating the application。
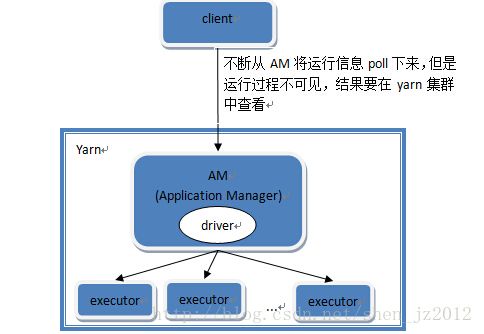
图3 yarn-cluster模式
In
yarn-client mode
, the driver runs
in the client process
, and the application master is only used for requesting resources from YARN。
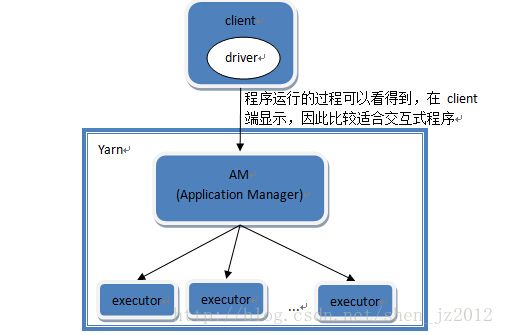
图4 yarn-client模式
因此,yarn-cluster更适用于实际应用,而yarn-client更适用于交互式的应用,比如说调试。更具体的在这篇博文中有提到 《Spark:Yarn-cluster和Yarn-client区别与联系》
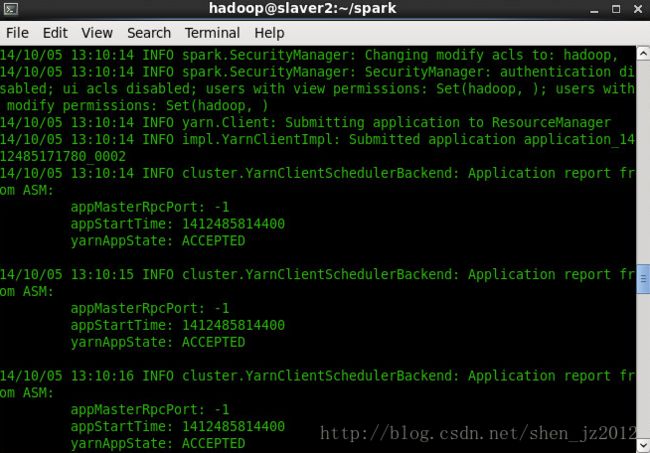
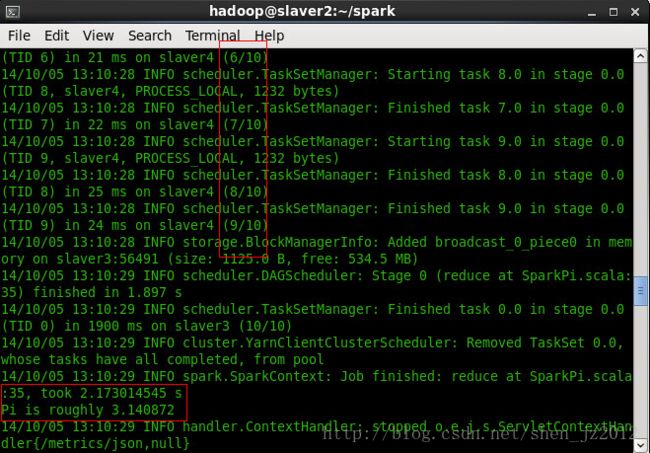
下面几张截图是分别运行两种模式时候的结果。
Yarn-cluster模式:


Yarn-client模式: