Phoenix / HBase中的salted table
What are salted tables
为了避免读写HBase表数据时产生hot-spot问题,我们使用Phoenix来创建表时可以采用salted table。
salted table可以自动在每一个rowkey前面加上一个字节,这样对于一段连续的rowkeys,它们在表中实际存储时,就被自动地分布到不同的region中去了。当指定要读写该段区间内的数据时,也就避免了读写操作都集中在同一个region上。
简而言之,如果我们用Phoenix创建了一个salted table,那么向该表中写入数据时,原始的rowkey的前面会被自动地加上一个byte(不同的rowkey会被分配不同的byte),使得连续的rowkeys也能被均匀地分布到多个regions。
Examples
安装Phoenix
本文使用的Phoenix版本是4.3.1,可以从这里下载
Hadoop平台为 CDH 5.2.1,其中的HBase版本为HBase 0.98.6-cdh5.2.1。
创建salted table
CREATE TABLE "test:salted"(pk VARCHAR PRIMARY KEY, c1 VARCHAR, c2 VARCHAR, c3 VARCHAR) SALT_BUCKETS=5;上述语句创建了一个名为”test:salted”的table(HBase中事先要创建名为test的namespace),SALT_BUCKETS=5 说明该salted table由5个bucket组成(必须在1~256之间)。
注:上面在创建table时,没有指定family,只指定了qualifier(c1, c2, c3),因此在HBase shell向表salted写入数据时,column name 要写成’0:[qualifier]’(如’0:c1’),否则HBase会报错:
ERROR: Unknown column family! Valid column names: 0:*
现在,我们从HBase的UI中观察表”test:salted”,可以发现它确实是由5个bucket构成的: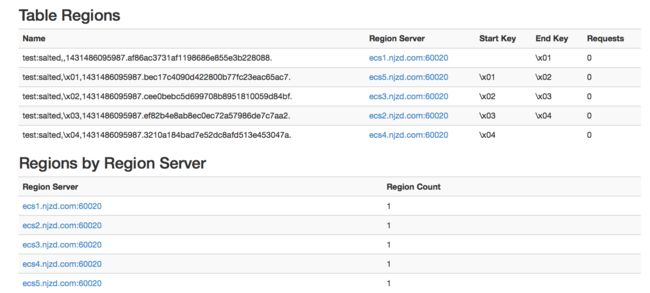
关于Family
如果在Phoenix SQL中创建table时为qualifier指定了family,如下:
CREATE TABLE "example" (my_pk bigint not null, m1.col varchar(50), m2.col varchar(50), m3.col varchar(50) constraint pk primary key (my_pk)) ;此时在客户端SQuirreLSQL中查看该表的结构,会发现显示时它没有包含family的名称,而是直接显示了3个相同的qualifier,如下:
用SQL查询该表的数据,显示结果时也没有区分family,如下
如果在SQL查询语句中直接指明
col,则会发现没有这个column。所以,在用SQL语句引用列名时,必须带上family,如下:select m1.col, m2.col, m3.col from "example";


Phoenix primary key 与HBase rowkey 的关系
在创建phoenix table时,必须指定一个primary key,但是这个主键我们不一定用到。如果我们想在用Phoenix创建table时,让Phoniex的主键自动地与HBase的rowkey对应起来,则可以用以下方式来创建:
create table "{空间名:表名}" ("pk" varchar primary key, "{列1}" varchar, "{列2}" varchar, "{列3}" varchar) salt_buckets=10;这样,Phoniex的主键(名为pk)就自动地与HBase的rowkey对应起来了。
写入数据
创建了名为test:salted的salted table之后,我们尝试向该表写入一些数据。
通过HBase shell写入数据
hbase(main):003:0> put 'test:salted', 'row-1', '0:c1', 'value-1'现在查看写入的数据
hbase(main):006:0> get 'test:salted', 'row-1'
COLUMN CELL
0:c1 timestamp=1431487895411, value=value-1 写入的数据的原始rowkey为row-1,在HBase shell中按照row-1也能直接将该数据取出。
但是如果通过Phoenix则无法取出该数据:
通过Phoenix写入数据
upsert into "test:salted" values('row-2', 'value-2');现在查看写入的这条数据:
但是,HBase shell则无法正常查看这条数据:
所以,记住:
- 创建salted table后,应该使用Phoenix SQL来读写数据,而不要混用Phoenix SQL和HBase API
- 如果通过Phoenix创建了一个salted table,那么只有通过Phoenix SQL插入数据才能使得被插入的原始rowkey前面被自动加上一个byte,通过HBase shell插入数据无法prefix原始的rowkey
批量导入CSV数据
参考 Bulk CSV Data Loading
在使用MapReduce导入CSV文件时,遇到以下问题:
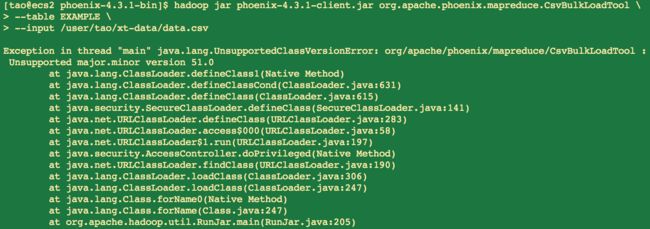
这里的异常信息Unsupported major.minor version 51.0代表什么意思?
意思是编译的时候用了JDK 7(51.0就是指Java 7,50.0指Java 6,52.0指Java 8) 但是运行时使用的是低版本的JDK(比如1.6)。
但是用命令java -version查看系统的Java版本确实是Java 7。其实,问题在于:hadoop使用的是Java 6,而不是Java 7。
怎样确定Hadoop用的是哪种Java? 对于CDH而言,默认情况下,它使用的系统的
$JAVA_HOME变量来确定使用哪种Java,当然也可以进行配置,使它不通过$JAVA_HOME变量来确定Java,如下图:
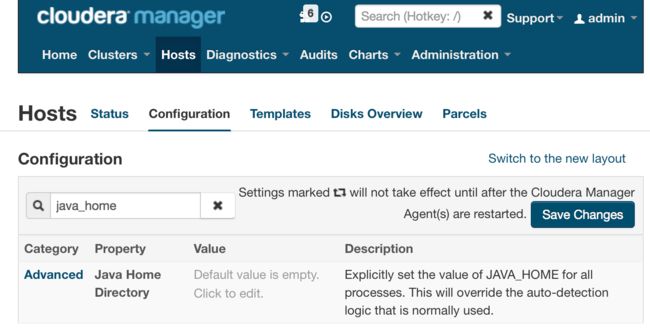
通过命令echo $JAVA_HOME验证,发现这确实导致了CDH使用了Java 6,所以,在上图中的配置中修改后重启系统即可,或者修改系统变量JAVA_HOME的值。How to set Java environment variables in Linux or CentOs 以及 Setting Global Environment Variables in CentOs
简而言之,要想Hadoop使用正确的Java版本,需要做两件事:
- 通过CDH配置使得Hadoop的各个进程使用预期的JDK;
- 在通过命令
hadoop jar ···命令来提交任务时,所在的console session的JAVA_HOME要指向预期的JDK目录。仅仅java -version输出java version "1.7.0_67"是不够的,它们两有时是矛盾的,如下: