spark streaming初试之wordcount
Spark streaming是一个离散化的流数据处理工具,将数据按照时间窗口切分成一个个RDD然后再处理。所以和逐条处理记录的storm比起来延迟稍大,在一些不需要秒内延迟的数据处理业务中,spark streaming的表现还是不错的。
简单介绍之后进入正题:
本例是创建一个实时的wordcount程序,程序监听TCP套接字的数据服务器获取文本数据,然后计算文本中包含的单词数。本例是在spark-shell中实现的,如果想编写独立的应用程序会稍有不同。在编写程序之前我们要先运行Netcat作为数据服务器,比如你可以在master节点运行以下命令:
nc –lk 9999
运行结果如下:
这时下面会有一个光标在闪动。然后在spark-shell中输入 :paste 回车,冒号也要输入,进入粘贴模式。

然后将下面的代码复制过去:
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
val ssc = new StreamingContext(sc, Seconds(1))
val lines = ssc.socketTextStream("master", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
按下ctrl+D执行这段代码。这时会不断打印出处理结果,每1s打印一次:
这时我们在第二个终端输入hello word,回车:
![]()
看到如下结果,说明测试成功:
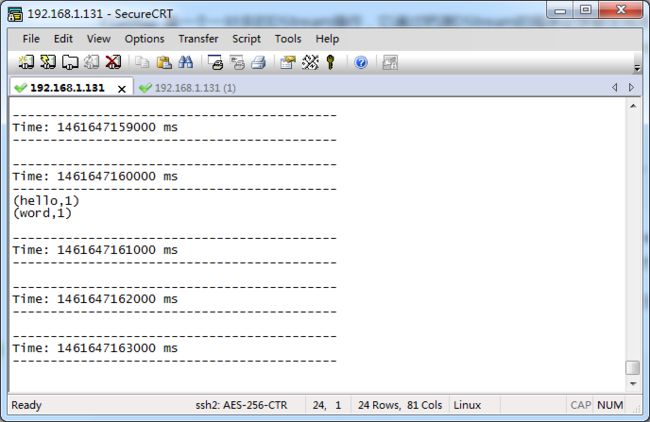
下面解释一下这段代码:
在上面的代码中,我们首先导入相关的类。然后创建一个StreamingContext对象,这个对象类似于sparkcontext,是spark所有流操作的主要入口。
这里要注意一点,官方文档中的ssc创建方式是这样的:
val conf = newSparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = newStreamingContext(conf, Seconds(1))
这是在独立应用中的创建方式,如果在spark-shell下这样做会报异常,因为在spark-shell中默认给我们创建好了一个sparkcontext对象sc,而上面这种方式则相当于又创建了一个匿名的sparkcontext,这样就起了冲突。因为在一个进程中只能有一个sparkcontext。
参数Second(1)表示数据流按照1s进行切分。接下来连接地址、端口。你可以将任何一个安装了netcat的机器作为这里的测试数据服务器。只需要填写对应的地址、端口就可以了。
这个lines变量是一个DStream,表示即将从数据服务器获得的流数据。这个DStream的每条记录都代表一行文本。下一步,我们需要将DStream中的每行文本都切分为单词。
flatMap是一个一对多的DStream操作,它通过把源DStream的每条记录都生成多条新记录来创建一个新的DStream。在这个例子中,每行文本都被切分成了多个单词,我们把切分的单词流用words这个DStream表示。
words这个DStream被mapper(一对一转换操作)成了一个新的DStream,它由(word,1)对组成。然后,我们就可以用这个新的DStream计算每批数据的词频。最后,我们用wordCounts.print()打印每秒计算的词频。
需要注意的是,当以上这些代码被执行时,SparkStreaming仅仅准备好了它要执行的计算,实际上并没有真正开始执行。在这些转换操作准备好之后,要真正执行计算,需要调用如下的方法:
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate