python学习2016.4.1
(1)pandas.Series.value_counts:返回对象中包含唯一值个数,
Series.value_counts(normalize=False, sort=True, ascending=False, bins=None,dropna=True)
| 参数: |
normalize : boolean, default False 如果True则返回counts的相对频率 sort : boolean, default True 对值进行排序 ascending : boolean, default False 默认对counts降序排列 bins : integer, optional 不是返回个数,而是归入半开的组区间,方便用 pd.cut,只能对数值型数据有用 dropna : boolean, default True 默认不包含NAN的个数 |
| 返回值: |
counts : Series |
示例:
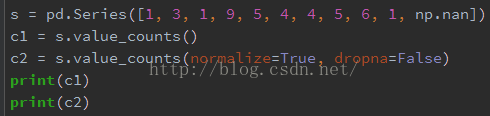
输出结果:
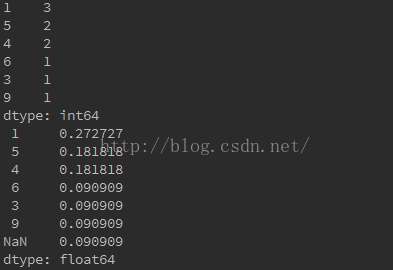
(2)s.values_counts().reset_index(),加入了行的索引
(3)df_today = df[df.insertday == dt1] 取出数据框中insertday对应的值为dt1的行。
(4)x.shape可以应用于各种存储结果,查看其各维度大小,但是不能应用于单个值。
(5)from scipy.stats import ks_2samp是片python内置的函数,计算两个数据样本分布KS统计量,函数ks_2samp(s1,s2)=(ks,p),返回KS值,和双尾检验的p值。
(6)isinstance(value, float),判断对象数据类型,返回True OrFalse
(7)round(x,n),返回浮点数X的四舍五入值。
(8)异常处理:避免程序中途出错而停止运行,而是以另一种方式处理,或则提示异常。
try:
<...............> #可能得到异常的语句
except<.......>: #锁定是哪种异常
<...............> #出现异常的处理方法
(9)if __name__ =='__main__':
模块是对象,并且所有的模块都有一个内置属性 __name__。一个模块的 __name__ 的值取决于您如何应用模块。如果 import 一个模块,那么模块__name__ 的值通常为模块文件名,不带路径或者文件扩展名。但是您也可以像一个标准的程序样直接运行模块,在这 种情况下, __name__的值将是一个特别缺省"__main__"。
#Test.py
classTest:
def __init(self):pass
def f(self):print 'Hello, World!'
if__name__ == '__main__':
Test().f()
#End
(10)help(函数)可以出现函数的帮助使用方式
(11)zip(seq1 [, seq2 [...]]) -> [(seq1[0], seq2[0] ...), (...)]:返回一个列表,其中的元素是元组,并且对应着每个List中的元素。
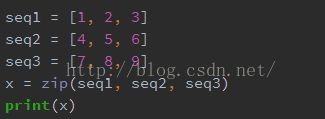
输出结果:
[(1, 4, 7), (2, 5, 8), (3, 6, 9)]
(11)dict()

输出:
![]()
注:用dict()后,顺序被打乱,由于字典存储方式不是按顺序的,这样比较快,而字典是以键取值,不会有影响。