字典树模板
字典树
字典树,又称单词查找树,Trie树,是一种树形结构,哈希表的一个变种。用于统计,排序和保存大量的字符串(也可以保存其
的)。
优点就是利用公共的前缀来节约存储空间。在这举个简单的例子:比如说我们想储存3个单词,nyist、nyistacm、nyisttc。如果只是
单纯的按照以前的字符数组存储的思路来存储的话,那么我们需要定义三个字符串数组。但是如果我们用字典树的话,只需要定义
一个树就可以了。在这里我们就可以看到字典树的优势了。
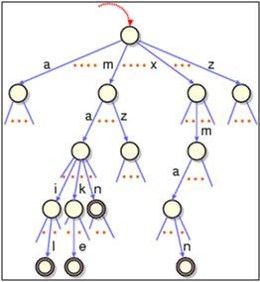
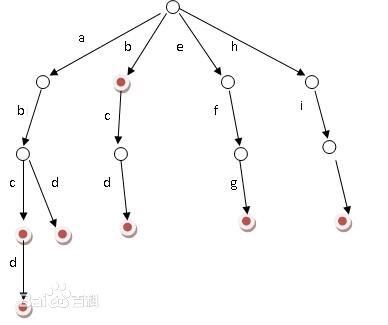
基本的操作
1.定义(即定义结点)
- struct node
- {
- int cnt;
- struct node *next[26];
- node()
- {
- cnt=0;
- memset(next,0,sizeof(next));
- }
- };
据题意来确定。
cnt可以表示一个字典树到此有多少相同前缀的数目,这里根据需要应当学会自由变化。
2.插入(即建树过程)
构建Trie树的基本算法也很简单,无非是逐一把每则单词的每个字母插入Trie。插入前先看前缀是否存在。如果存在,就共享,否则
创建对应的节点和边。比如要插入单词add(已经插入了单词“ad”),就有下面几步:
考察前缀"a",发现边a已经存在。于是顺着边a走到节点a。
考察剩下的字符串"dd"的前缀"d",发现从节点a出发,已经有边d存在。于是顺着边d走到节点ad
考察最后一个字符"d",这下从节点ad出发没有边d了,于是创建节点ad的子节点add,并把边ad->add标记为d。
- void buildtrie(char *s)
- {
- node *p=root;
- node *tmp=NULL;
- int i,l=strlen(s);
- for(i=0;i<l;i++)
- {
- if(p->next[s[i]-'a']==NULL)
- {
- tmp=new node;
- p->next[s[i]-'a']=tmp;
- }
- p=p->next[s[i]-'a'];
- p->cnt++;
- }
- }
3.查找
(1)每次从根结点开始进行搜索;
(2)取要查找关键词的第一个字母,并根据该字母选择对应的子树并转到该子树继续进行检索;
(3)在相应的子树上,取得要查找关键词的第二个字母,并进一步选择对应的子树进行检索;
(4)迭代刚才过程。。。
(5)直到在某个结点处:
——关键词的所有字母都被取出,则读取附在该结点上的信息,即完成查找。
——该结点没有任何信息,则输出该关键词不在此字典树里。
- void findtrie(char *s)
- {
- node *p=root;
- int i,l=strlen(s);
- for(i=0;i<l;i++)
- {
- if(p->next[s[i]-'a']==NULL)
- {
- printf("0\n");
- return;
- }
- p=p->next[s[i]-'a'];
- }
- printf("%d\n",p->cnt);
- }
4.释放内存
有些题目,数据比较大,需要查询完之后释放内存(比如:hdu1671 Phone List)
递归释放内存:
- void del(node *root)
- {
- for(int i=0;i<10;i++)
- if(root->next[i])
- del(root->next[i]);
- delete(root);
- }