插入排序、归并排序和递归算法的复杂性分析
转载请声明出处:http://blog.csdn.net/zhongkelee/article/details/44490315
说在前面
这学期正在学习《计算机算法设计与分析》,所以用博客的形式记录自己的学习心得,与大家交流分享。
一、算法渐进复杂性及其相关记号
1. 复杂度概念
算法的复杂性分析,说白了也就是关于计算机程序的性能和算法所用计算机资源的理论分析。通常包括时间复杂性T(n)和空间复杂性S(n),其中n是问题的输入规模。一般来说算法需要的时间与输入的规模同步增长,所以通常把一个程序的运行时间描述成输入规模的函数。
对许多问题,比如排序或计算离散傅里叶变换最自然的量度是输入中的项数,例如带排序数组的规模n。对许多其他问题,比如两个整数相乘,输入规模的最佳量度是用通常的二进制记号表示输入所需的总位数。
通常一个算法的运行时间依赖于输入,而我们想要获取的是运行时间的上界(实际上每个人都更倾向于获得一种保证)。
最坏情况下的时间复杂性:
![]()
最好情况下的时间复杂性:
![]()
平均情况下的时间复杂性:
![]()
其中 I 是问题的规模为 n 的实例,p(I) 是实例I出现的概率。
2. 渐近复杂性
如果我们忽略机器相关的参数,只考察 T(n) 随着 n 趋于无穷大的增长,则可以引入渐近复杂性的概念:
![]()
t(n) 是 T(n) 的渐进性态,是 T(n) 略去低阶项后留下的主项,我们称作算法的渐进复杂性。
例如,当 n 足够大时,一个![]() 的算法总是能够打败一个
的算法总是能够打败一个![]() 的算法。
的算法。
在后文中,我们使用如下渐进分析记号:
其实,这5个记号可以理解为:
若对所有的![]() ,函数f(n)在一个常量因子内等于g(n),就称g(n)是f(n)的一个渐进紧确界,如下图所示:
,函数f(n)在一个常量因子内等于g(n),就称g(n)是f(n)的一个渐进紧确界,如下图所示:

有关算法分析中渐进函数、常用函数的若干条性质,我这里就不再赘述了,可以参考《算法导论》第三版29~34页相关内容及证明。
3. 最优算法
如果问题的计算时间下界为![]() ,则计算时间复杂性为
,则计算时间复杂性为![]() 的算法,就可以称为最优算法。例如,比较排序问题的计算时间下界为
的算法,就可以称为最优算法。例如,比较排序问题的计算时间下界为![]() ,计算时间复杂性为
,计算时间复杂性为![]() 的排序算法是最优算法(比如堆排序算法,后续博客会详细讲解该算法)。
的排序算法是最优算法(比如堆排序算法,后续博客会详细讲解该算法)。
4.常见时间复杂度
常见时间复杂度从低到高为:常数 < 对数< 多项式 < 指数 < 阶乘。
二、普通算法复杂度分析
1. 顺序搜索算法
例如,顺序搜索算法:
Template<class Type>
Int seqSearch(Type *a, int n, Type k){
for(int i = 0; i < n; i++)
if(a[i] == k)
return i;
return -1;
}
它的三种时间复杂性计算如下:
一般来说,对于非递归算法的复杂性分析,有以下几个基本法则:
(1)for/while循环:循环体内计算时间*循环次数;
(2)嵌套循环:循环体内计算时间*所有循环次数;
(3)顺序语句:个语句计算时间相加;
(4)if-else语句:if语句计算时间和else语句计算时间的较大者。
2. 插入排序算法
再举一个例子,比如插入排序算法的代码如下:
template<class type>
void insertion_sort(Type *a, int n){
Type key;
for(int i = 1; i < n; i++){
key = a[i];
int j = i-1;
while(j >= 0 && a[j] > key){
a[j+1] = a[j];
j--;
}
a[j+1] = key;
}
}
下图可以很形象地描述插入这一过程(左手总是持有排好序的牌,右手每次启一张新牌插入):
时间复杂度计算如下:
三、递归算法实例
1. 递归与分治
直接或者间接地调用自身的算法称为递归算法。用函数自身给出定义的函数称为递归函数。有些数据结构,如二叉树等,由于其本身固有的递归特性,特别适合用递归的形式来描述,许多有用的算法在结构上都是递归的,这些算法典型地遵循分治法的思想:将原问题分解为几个规模较小但类似于原问题的子问题,递归地求解这些子问题,然后再合并这些子问题的解来建立原问题的解。原问题与子问题唯一的区别就是输入规模不同。
注:迭代与递归的区别,迭代是指循环的过程,递归是指函数不断调用自身的过程。
例如,阶乘函数递归求解代码为:
int factorial(int n){
if (n == 0)
return 1;
return n*factorial(n-1);
}
复杂性分析:
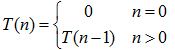
很简单的就能得出 T(n) = n。
一般来说分治模式在每层递归时都有三个步骤:
1. 分解原问题为若干子问题,这些字问题是原问题的规模较小的实例。
2. 解决这些子问题,递归地求解各子问题。然而,若子问题的规模足够小,则直接求解。
3. 合并这些子问题的解成原问题的解。
2. 归并排序算法
归并排序算法完全遵循分治模式。直观上其操作如下:
1. 分解:分解待排序的n个元素的序列成各具n/2个元素的两个子序列。
2. 解决:使用归并排序递归地排序两个子序列。
3. 合并:合并两个已排序的子序列以产生已排序的答案。
边界条件为,当待排序的问题规模为1时,递归开始“回升”,这种情况下不要做任何工作,因为长度为1的每个序列都已排好序。
归并排序算法步骤如下:
其中,合并步骤的伪代码如下(设置哨兵):
子序列排序步骤的伪代码如下:
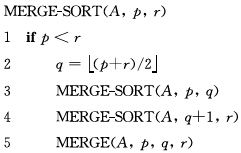
由下图可得出,归并排序中,合并两个已排序子序列这一步的复杂度为线性时间 O(n):
复杂度分析:
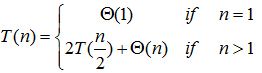
当![]() 时,我们通常不陈述足够小n下的基础情况,但是要求对迭代的渐进解没有影响。
时,我们通常不陈述足够小n下的基础情况,但是要求对迭代的渐进解没有影响。
得到递推公式后,我们使用递归树的方法来求T(n)的上界。
也即求解T(n) = 2T(n/2) + cn,这里c > 0 是常数:

由上图可以看出,整个递归树高度为logn,总共有(log n + 1)层,每层结点复杂度之和为cn,总代价就是cn logn + cn,忽略低阶项和常量c,所以总的归并算法复杂度就是![]() 。
。
下图说明了当n为2的幂时,归并排序在数组A = {5,2,4,7,1,3,2,6}上的操作,随着算法自底向上地推进,待合并的已排好序的各序列的长度不断增加。
3. 插入排序和归并排序算法的比较
从前文关于最优算法的定义可以得出,因为![]() 的增长速度慢于
的增长速度慢于![]() ,所以在最坏情况下,归并排序算法渐进意义上优于插入排序算法。但是,在实际应用中,通常是在 n>30 左右后归并排序才开始打败插入排序!
,所以在最坏情况下,归并排序算法渐进意义上优于插入排序算法。但是,在实际应用中,通常是在 n>30 左右后归并排序才开始打败插入排序!
4. 代码实现和论证
为此,我用c++实现了插入排序和归并排序算法,并进行了对比,实验结果论证了上述结论,代码如下:
#include <iostream>
#include <fstream>
#include <stdlib.h>
#include <time.h>
#include <assert.h>
using namespace std;
template<typename T>//插入排序
void InsertSort(T* ptr, int length){
typedef T type;
typedef type* ptr_type;
type key;
for(int i = 1; i < length; i++){
key = ptr[i];
int j = i-1;
while(j>=0 && ptr[j]>key){
ptr[j+1] = ptr[j];
j--;
}
ptr[j+1] = key;
}
}
template<typename T>//归并排序合并操作
void Merge(T* ptr, int begin, int mid, int end){
typedef T type;
typedef type* ptr_type;
/*使用哨兵位*/
type imax = std::numeric_limits<type>::max();//哨兵牌
int lsize = mid - begin +1;//左堆牌数
int rsize = end - mid;//右堆牌数
ptr_type left = new type[lsize+1];//增加哨兵牌的新左堆
ptr_type right = new type[rsize+1];//增加哨兵牌的新右堆
for (int i = 0; i < lsize; i++)//原左堆牌放入新左堆
left[i] = ptr[begin+i];
left[lsize] = imax;//新左堆最下面放置哨兵牌
for (int i = 0; i < rsize; i++)//右堆同理
right[i] = ptr[mid+1+i];
right[rsize] = imax;
/*比较新左右堆顶牌大小,较小者放入新堆ptr[]中*/
int i = 0, j = 0;
for (int k = begin; k <= end; k++){
if (left[i] <= right[j])
ptr[k] = left[i++];
else
ptr[k] = right[j++];
}
delete[] left;
left = NULL;
delete[] right;
right = NULL;
}
template<typename T>//归并排序子序列排序操作
void MergeSort(T* ptr, int begin, int end){
if (begin >= end)
return;
int mid = (begin+end)/2;
MergeSort(ptr, begin, mid);
MergeSort(ptr, mid+1, end);
Merge(ptr, begin, mid, end);
}
int main()
{
const int TEST_NUM = 100;//测试数组大小
ofstream fout;
fout.open("SortResult.txt", ios::out|ios::app);
if (fout.fail()){
cout<<"can't open SortResult.txt"<<endl;
getchar();
return 0;
}
srand((int)time(NULL));//以当前时间对应的int值为随机序列起点
fout<<"Test Array Number:\t"<<TEST_NUM<<endl;
int* testPtr1 = new int [TEST_NUM];
int* testPtr2 = new int [TEST_NUM];
for (int i = 0; i < TEST_NUM; i++)
testPtr1[i] = testPtr2[i] = rand();//产生随机数
clock_t t = clock();//当前时间
InsertSort(testPtr1, TEST_NUM);
fout<<"Insert Sort Time:\t"<<clock()-t<<endl;
t = clock();
MergeSort(testPtr2, 0, TEST_NUM-1);
fout<<"Merge Sort Time:\t"<<clock()-t<<endl;
for (int i = 0; i < 10; i++)//判断是否正确排序
assert(testPtr1[i] == testPtr2[i]);
cout<<"sort done!"<<endl;
delete[] testPtr1;
testPtr1 = NULL;
delete[] testPtr2;
testPtr2 = NULL;
fout.close();
return 0;
}
实验对比结果:
从实验代码和以上算法分析可以总结出如下结论:
(1)插入排序算法时间复杂度是O(n^2),空间复杂度是1。
(2)归并排序算法时间复杂度是O(nlogn),空间复杂度是n。
四、递归算法的复杂性分析
接下来,将递归算法分析的三种求解渐近紧确界方法,归纳如下:
1.代入法
实质上就是数学归纳法,先对一个小的值做假设,然后推测更大的值得正确性。由于是数学归纳法,那么我们就需要对值进行猜测。
代入法求解递归式一般分为两步:
(1)猜测解的形式。
(2)验证解的形式,并计算常数。
优势:将归纳假设应用于较小的值时,我们将猜测的解带入函数,单凭经验直接猜出复杂度,有没有相当强大?
劣势:并不存在通用的方法来猜测递归式的正确解,很有可能猜错。
注意:代入法的证明过程中,要严格按照完整定义给出进行证明,不可以使用渐进表达法!
示例一:

(经验:在证明过程中,当常数无法获取时,通常是减去一个低阶项而不是增加。)
示例二:
针对T(n) = 2T(n/2)+n,我们猜测T(n) = O(nlogn),有:
故假设成立,T(n) = O(nlogn)。
2. 递归树法
前提:当声明、求解递归式时,我们常常忽略向下取整、向上取整及边界条件。
虽然你可以用代入法简洁地证明一个解确是递归式的正确解,但想出一个好的猜测可能会很困难。画出递归树,如我们前面分析归并排序的递归式时所做的那样,是设计好的猜测的一种简单而直接的方法。递归树模型刻画了一个算法在递归执行时的时间消耗。
在递归树中,每个结点表示一个单一子问题的代价,子问题对应某次递归函数调用。我们将树中每层中的代价求和,得到每层代价,然后将所有层的代价求和,得到所有层次的递归调用的总代价。所以,我们利用递归树求解代价,需要知道什么呢,一个是每一层的代价,一个是层数,就是这两个。这个模式一般是典型的等差或等比级数。
利用递归树方法求算法复杂度我想最好的例子就是归并排序了,但是前面第二部分已经做了说明,这里用课堂上的一个更形象的例子来说明:
对递归方程:![]()
有如下递归树:
于是:
![]()
(因为等比数列的比例因子![]() )。
)。
注解:
当出现等比数列,整个递推式的量级由最大项决定,
 。
。
3. 主定理
主定理方法应用于如下的递归形式:
为了使用主定理,需要牢记三种情况,但随后你就可以很容易地求解很多递归式,通常不需要纸和笔的帮助!
理解:将n规模的问题拆分成a个n/b规模的问题,并且剩下的操作为f(n)。
主定理主要来自递归树方法,如果我们画T(n)的递归树T(n)=aT(n/b)+f(n),我们会发现根节点的值为f(n),所有的叶子节点的和为![]() ,递归树的高度为
,递归树的高度为![]() 。(求解方法为
。(求解方法为![]() ,得出迭代次数(树高度)为
,得出迭代次数(树高度)为![]() ,叶子节点有
,叶子节点有![]() 个,又
个,又![]() )。
)。
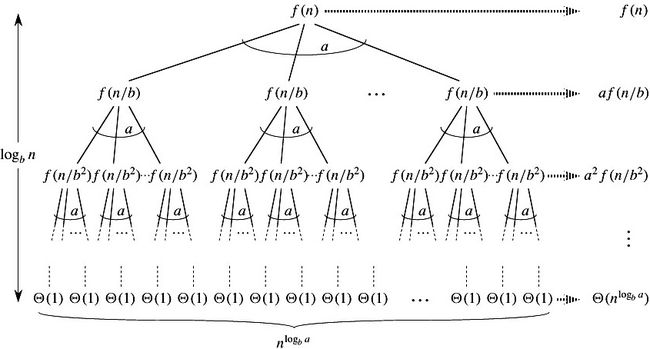
在递归树方法中,我们计算所有节点的和。
(1)如果在叶子节点的值是多项式的,那么叶子是占主导地位的一部分,而我们的结果变成叶子节点的值(主定理情况1)。
(2)如果叶和根是渐近一样的,那么结果就变成树高度乘以所有层的和(主定理情况2)。
(3)如果根节点的值是渐近多,那么我们的结果变成在根节点的值(主定理情况3)。
示例:
注意:
五、总结
我们分别对普通算法和递归算法进行了复杂度分析,但在最后我还是要强调一点,就是我们在分析之前做出了两个假设:
1. 输入规模为n。
2. 我们是按照最坏情况来分析算法的时间复杂度。
上面重点描述了三种求解递归式的方法,即得出算法的![]() 渐进界的方法:
渐进界的方法:
(1)代入法 我们猜测一个界,然后用数学归纳法证明这个界是正确的。
(2)递归树法 将递归式转换为一棵树,其结点表示不同层次的递归调用产生的代价。然后采用边界和技术来求解递归式。
(3)主方法 可求解形如下面公式的递归式的界:T(n) = aT(n/b) + f(n),其中,![]() 是一个给定的函数。这种形式的递归式很常见,它刻画了这样一个分治方法:生成a个子问题,每个子问题的规模是原问题规模的1/b,分解和合并步骤共花费时间为f(n)。为了使用主方法,必须要熟记三种情况,但是一旦你掌握了这种方法,确定很多简单递归式的渐进界就变得很容易。
是一个给定的函数。这种形式的递归式很常见,它刻画了这样一个分治方法:生成a个子问题,每个子问题的规模是原问题规模的1/b,分解和合并步骤共花费时间为f(n)。为了使用主方法,必须要熟记三种情况,但是一旦你掌握了这种方法,确定很多简单递归式的渐进界就变得很容易。
![]() 好了,这部分内容就说到这,希望对读者有所帮助。在后一篇博文中,我还会介绍一种摊还分析方法,来评价算法操作的代价。
好了,这部分内容就说到这,希望对读者有所帮助。在后一篇博文中,我还会介绍一种摊还分析方法,来评价算法操作的代价。
转载请声明出处:http://blog.csdn.net/zhongkelee/article/details/44490315
源码下载