R语言爬虫之——RCurl
RCurl作者
Duncan Temple Lang
现任加州大学 U.C. Davis分校副教授
致力于借助统计整合进行信息技术的探索
RCurl的概述
The RCurl package is an R-interface to the libcurl library that provides HTTP
facilities. This allows us to download files from Web servers, post forms, use
HTTPS (the secure HTTP), use persistent connections, upload files, use binary
content, handle redirects, password authentication, etc.
RCurl这个程序包提供了由R到libcurl库的接口,从而实现HTTP的一些功能。例如,从
服务器下载文件、保持连接、上传文件、采用二进制格式读取、句柄重定向、密码认证等等。
什么是curl&libcurl
– curl:利用URL语法在命令行方式下工作的开源文件传输工具
– curl背后的库就是libcurl
功能
– 获得页面
– 有关认证
– 上传下载
– 信息搜索
– ……
HTTP协议
协议是指计算机通信网络中两台计算机之间进行通信所必须共同遵守的规定或规则,超文本传输协议(HTTP)是一种通信协议,它允许将超文本标记语言(HTML)文档从Web服务器传送到客户端的浏览器
目前我们使用的是HTTP/1.1 版本
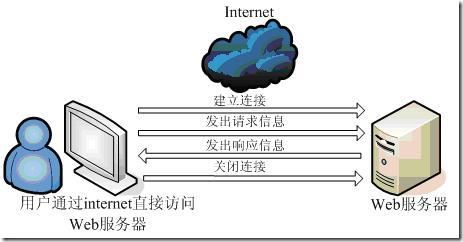
1. URL详解
基本格式:schema://host[:port#]/path/…/[?query-string][#anchor]
scheme 指定低层使用的协议(例如:http, https, ftp)
host HTTP服务器的IP地址或者域名
port# HTTP服务器的默认端口是80,这种情况下端口号可以省略。
path 访问资源的路径
query-string 发送给http服务器的数据
anchor- 锚
2. 请求request
请求行、请求报头、消息正文

Method 表示请求方法,比如“GET”,“POST”,““HEAD”,”PUT“等
Path-to-resource 表示请求的资源
Http/version-number 表示HTTP协议的版本号
请求报头
Host 服务器地址
Accept 浏览器端可以接受的媒体类型,text/html
Accept-encoding 浏览器接收的编码方法,通常所指的是压缩方法
Accept-language 浏览器声明自己接收的语言
User-agent 告诉服务器客户端的操作系统、浏览器版本
Cookie 最重要的请求报头的成分,为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)
Referer 跳转页
Connection 客户端与服务器的连接状态
3. 响应response
状态行、消息报头、响应正文

HTTP/version-number表示HTTP协议的版本号
status-code 和message表示状态码以及状态信息
status-code(状态码)
状态码用来告诉HTTP客户端,HTTP服务器是否产生了预期的Response.
HTTP/1.1中定义了5类状态码, 状态码由三位数字组成,第一个数字定义了响应的类
别
– 1XX 提示信息 - 表示请求已被成功接收,继续处理
– 2XX 成功 - 表示请求已被成功接收,理解,接受
– 3XX 重定向 - 要完成请求必须进行更进一步的处理
– 4XX 客户端错误 - 请求有语法错误或请求无法实现
– 5XX 服务器端错误 - 服务器未能实现合法的请求
消息报头
Server 服务器的软件信息,如nginx
Date 响应日期
Last-Modified 上次修改时间
Content-type 服务器告诉浏览器自己响应的对象类型,text/html
Connection 服务器和客户端是否保持链接
X-Powered-By 表示网站是什么技术开发的,如PHP
Content-Length 请求返回的字节长度
Set-Cookie 响应最重要的一个header,用于把cookie发给相应的浏览器,每一个写入cookie都会生成一个set-cookie
RCurl三大函数
getURL()
getForm()
postForm()
getURL()
# 判断url是否存在
url.exists(url="www.baidu.com") # 判断url是否存在
# [1] TRUE
d <- debugGatherer() #收集调试信息
# verbose = TRUE 这时候,d$value()值是会叠加的
tmp <- getURL(url="www.baidu.com", debugfunction = d$update, verbose = TRUE)
names(d$value())
# [1] "text" "headerIn" "headerOut" "dataIn" "dataOut" "sslDataIn" "sslDataOut"
cat(d$value()[1]) #服务器地址及端口号
cat(d$value()[2]) #服务器返回的头信息
cat(d$value()[3]) #提交给服务器的头信息
d$reset() # 清除d$value()
d$value() # 清除之后全部为空
# text headerIn headerOut dataIn dataOut sslDataIn sslDataOut
# "" "" "" "" "" "" "" # 查看服务器返回的头信息
## 列表形式
h <- basicHeaderGatherer()
txt <- getURL(url="http://www.baidu.com", headerfunction = h$update)
names(h$value())
# [1] "Date" "Content-Type" "Content-Length" "Last-Modified" "Connection"
# [6] "Vary" "Set-Cookie" "Set-Cookie" "Set-Cookie" "P3P"
# [11] "Server" "Pragma" "Cache-control" "BDPAGETYPE" "BDQID"
# [16] "BDUSERID" "Accept-Ranges" "status" "statusMessage"
h$value()# 查看服务器返回的头信息
## 字符串形式
h <- basicTextGatherer()
txt <- getURL("http://www.baidu.com", headerfunction = h$update) names(h$value())
# NULL # 说明是字符串形式,没有列
h$value() # 所有的内容只是一个字符串 # [1] "HTTP/1.1 200 OK\r\nDate: Mon, 23 Feb 2015 15:18:28 GMT\r\nContent-Type: text/html\r\nContent-Length: 14613\r\nLast-Modified: Wed, 03 Sep 2014 02:48:32 GMT\r\nConnection: Keep-Alive\r\nVary: Accept-Encoding\r\nSet-Cookie: BAIDUID=FFF680C9F9631969198A77AAFF56096E:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com\r\nSet-Cookie: BAIDUPSID=FFF680C9F9631969198A77AAFF56096E; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com\r\nSet-Cookie: BDSVRTM=0; path=/\r\nP3P: CP=\" OTI DSP COR IVA OUR IND COM \"\r\nServer: BWS/1.1\r\nPragma: no-cache\r\nCache-control: no-cache\r\nBDPAGETYPE: 1\r\nBDQID: 0xc1ae773200820725\r\nBDUSERID: 0\r\nAccept-Ranges: bytes\r\n\r\n" cat(h$value()) # 用cat显示的,会比较好看
HTTP/1.1 200 OK
Date: Mon, 23 Feb 2015 15:18:28 GMT
Content-Type: text/html
Content-Length: 14613
Last-Modified: Wed, 03 Sep 2014 02:48:32 GMT
Connection: Keep-Alive
Vary: Accept-Encoding
Set-Cookie: BAIDUID=FFF680C9F9631969198A77AAFF56096E:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: BAIDUPSID=FFF680C9F9631969198A77AAFF56096E; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: BDSVRTM=0; path=/
P3P: CP=" OTI DSP COR IVA OUR IND COM "
Server: BWS/1.1
Pragma: no-cache
Cache-control: no-cache
BDPAGETYPE: 1
BDQID: 0xc1ae773200820725
BDUSERID: 0
Accept-Ranges: bytes# 查看url请求的访问信息
curl <- getCurlHandle()
txt <- getURL(url="http://www.baidu.com", curl = curl)
names(getCurlInfo(curl))
[1] "effective.url" "response.code" "total.time"
[4] "namelookup.time" "connect.time" "pretransfer.time"
[7] "size.upload" "size.download" "speed.download"
[10] "speed.upload" "header.size" "request.size"
[13] "ssl.verifyresult" "filetime" "content.length.download"
[16] "content.length.upload" "starttransfer.time" "content.type"
[19] "redirect.time" "redirect.count" "private"
[22] "http.connectcode" "httpauth.avail" "proxyauth.avail"
[25] "os.errno" "num.connects" "ssl.engines"
[28] "cookielist" "lastsocket" "ftp.entry.path"
[31] "redirect.url" "primary.ip" "appconnect.time"
[34] "certinfo" "condition.unmet"
getCurlInfo(curl)$response.code
# [1] 200
getCurlInfo(curl=curl)
$effective.url
[1] "http://www.baidu.com"
$response.code
[1] 200
$total.time
[1] 0.041523
$namelookup.time
[1] 0.011336
……设置自己的header
# 设置自己的header,把系统设置成ihpone的系统Mac OS
myheader <- c(
"User-Agent"="Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_0_1 like Mac OS X; ja-jp) AppleWebKit/532.9 (KHTML, like Gecko) Version/4.0.5 Mobile/8A306 Safari/6531.22.7",
"Accept"="text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language"="en-us",
"Connection"="keep-alive",
"Accept-Charset"="GB2312,utf-8;q=0.7,*;q=0.7"
)
d <- debugGatherer()
tmp <- getURL(url = "http://www.baidu.com", httpheader = myheader, debugfunction = d$update, verbose = T)
cat(d$value()[3]) # 提交给服务器的头信息,发现设置成功
GET / HTTP/1.1
Host: www.baidu.com
User-Agent: Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_0_1 like Mac OS X; ja-jp) AppleWebKit/532.9 (KHTML, like Gecko) Version/4.0.5 Mobile/8A306 Safari/6531.22.7
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us
Connection: keep-alive
Accept-Charset: GB2312,utf-8;q=0.7,*;q=0.7设置其他参数
verbose 输出访问的交互信息
httpheader 设置访问信息报头
.encoding=”UTF-8” “GBK”
debugfunction, headerfunction, curl
.params 提交的参数组
dirlistonly 仅读目录,这个在ftp的网页,非常好用
followlocation 支持重定向
maxredirs 最大重定向次数
# 设置其他参数,共174个参数
listCurlOptions()
[1] "address.scope" "append"
[3] "autoreferer" "buffersize"
[5] "cainfo" "capath"
[7] "certinfo" "closepolicy"
……
……
[165] "url" "useragent"
[167] "username" "userpwd"
[169] "use.ssl" "verbose"
[171] "writedata" "writefunction"
[173] "writeheader" "writeinfo"getForm()
# getForm()函数 # 在百度里面搜索“rcurl”的url为(浏览器为google chrome): url <- c("http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=2&ch=&tn=SE_hldp02870_0v135xhf&bar=&wd=rcurl&rsv_spt=1&rsv_pq=a3ed162a0088df8f&rsv_t=43d18gWNyd6HWpqDiKov7Dm548s4HY4cgcJlXc8ujpzRW9Okec2aOb5screzftZo5DJ60Cp7aILvRK2Q&rsv_enter=1&inputT=2119") # wd=rcurl 这里就是关键字为rcurl getFormParams(query=url) # 查看url的结构和值 names(getFormParams(query=url)) [1] "ie" "f" "rsv_bp" "rsv_idx" "ch" "tn" "bar" "wd" "rsv_spt" [10] "rsv_pq" "rsv_t" "rsv_enter" "inputT" tmp <- getForm(uri="http://www.baidu.com/s", ie="utf-8", f="8", rsv_bp="1", rsv_idx="2", ch="", tn="SE_hldp02870_0v135xhf", bar="", wd="rcurl", rsv_spt="1", rsv_pq="a3ed162a0088df8f", rsv_t="43d18gWNyd6HWpqDiKov7Dm548s4HY4cgcJlXc8ujpzRW9Okec2aOb5screzftZo5DJ60Cp7aILvRK2Q", rsv_enter="1", inputT="2119") # 这里的getForm函数不稳定(原因还不知道),有时候运行2到3次,才能真正找到页面 # 出来的错误的结果,爬取的页面为: [1] "<html><body><script type=\"text/javascript\">function d(a,n){var c=a.length,b=a[c-1];if(n&&n!='JSSESSID'){for(var i=c-2;i>=0;i--){b=a[i]+'.'+b;document.cookie=n+'=; domain='+b+'; expires=Mon,01-Jan-1973 00:00:01 GMT';}}}(function (){var a=document.cookie.split('; ');for(var i=0;i<a.length;i++){d(location.hostname.split('.'),a[i].split('=')[0])}})();(function(u){if(window.navigate&&typeof navigate=='function')navigate(u);var ua=navigator.userAgent;if(ua.match(/applewebkit/i)){var h = document.createElement('a');h.rel='noreferrer';h.href=u;document.body.appendChild(h);var evt=document.createEvent('MouseEvents');evt.initEvent('click', true,true);h.dispatchEvent(evt);}else{document.write('<meta http-equiv=\"Refresh\" Content=\"0; Url='+u+'\" >');}})('http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=2&ch=&tn=SE_hldp01272_4chwhad3&bar=&wd=rcurl&rsv_spt=1&rsv_pq=a3ed162a0088df8f&rsv_t=43d18gWNyd6HWpqDiKov7Dm548s4HY4cgcJlXc8ujpzRW9Okec2aOb5screzftZo5DJ60Cp7aILvRK2Q&rsv_enter=1&inputT=2119');</script></body></html>" attr(,"Content-Type") "text/html" postForm()
以保密的形式上传我们所要页面提交的信息,然后获取服务器端返回该页面信息。例如登陆一个页面,需要账户和密码,那么我们需要提交账户和密码,提交的信息要加密,然后抓取登陆后的页面信息。
getBinaryURL()
# getBinaryURL() 下载一个文件
url <- "http://rfunction.com/code/1201/120103.R"
tmp <- getBinaryURL(url)
note <- file("120103.R", open = "wb")
writeBin(tmp, note)
close(note)# getBinaryURL() 批量下载文件
url <- "http://rfunction.com/code/1202/"
tmp <- RCurl::getURL(url, httpheader = myheader) # 获取网页
tmp_files <- strsplit(x=tmp, split="<li><a href=\"")[[1]]
tmp_files1 <- strsplit(tmp_files, split="\"")
tmp_files2 <- lapply(X=tmp_files1, function(file) {file[1]})
files <- unlist(tmp_files2)
files <- files[c(-1, -2)]
baseURL <- "http://rfunction.com/code/1202/"
for(i in 1:length(files)){
fullURL <- paste(baseURL, files[i], sep = "")
tmp <- getBinaryURL(fullURL)
note <- file(paste("1202-", files[i], sep = ""), open = "wb")
writeBin(tmp, note)
close(note)
Sys.sleep(2) # 休眠2秒
}XML
# XML简介
# 缺点:在windows下对中文支持不理想(我在ubuntu下也不理想)
library(XML)
url <- "http://data.earthquake.cn/datashare/datashare_more_quickdata_new.jsp" # 中文界面,抓出来是乱码
url <- "http://219.143.71.11/wdc4seis@bj/earthquakes/csn_quakes_p001.jsp" # 英文界面,抓出来是对的
wp <- getURL(url)
doc <-htmlParse(wp, asText = TRUE) # 这里切记encoding
tables <- readHTMLTable(doc, header=F, which = 2)
# 选取第二个表
head(tables)
V1 V2 V3 V4 V5 V6
1 Origin time(CST) Lat(°) Long(°) Depth(km) Mag Region
2 2012/01/08 14:20:08.0 42.10 87.50 7.0 M 5.0 NORTHERN XINJIANG, CHINA
3 2012/01/01 13:27:55.5 31.40 138.30 360.0 M 7.0 SOUTHEAST OF HONSHU, JAPAN
4 2011/12/27 23:21:58.5 51.80 95.90 10.0 M 7.0 SOUTHWESTERN SIBERIA, RUSSIA
5 2011/12/14 13:04:56.2 -7.50 146.80 120.0 M 7.2 EASTERN NEW GUINEA REG., P.N.G.
6 2011/12/12 09:42:34.0 39.60 118.20 5.0 M 3.2 NORTHEASTERN CHINA
解析xml文件的XPath设置
斜杠(/)作为路径内部的分割符
/:表示选择根节点
//:表示选择任意位置的某个节点
@: 表示选择某个属性
*表示匹配任何元素节点
@*表示匹配任何属性值
node()表示匹配任何类型的节点