云计算大赛&hadoop2.4.1安装
身处大数据时代,一下子一个词:“云计算”火了起来。最近参加了第一届云计算大赛。大二开始跟着老师做云计算的项目,还正在看老师发给我的项目资料呢,突然就来了这么个比赛,放下手中的ACM和其他琐事,开始琢磨着这个云计算大赛。比赛分为三个类别:创意赛,技能赛,命题赛。权衡之后,加上老师的建议选择了技能赛,简单来说就是主办方出了4道题目给你做,然后我要做的事就是把Map Reduce代码交给他。运行环境就是hadoop,为什么是hadoop呢?一个理由就是选择的原因,开源!hadoop下的分布式系统适合于大数据处理。
第一步,安装Linux操作系统(windows下就真的别考虑了),理论上装个虚拟机和双系统都是可以的(PC不建议Linux单系统23333),推荐装双系统,幸好大一在学校电脑社团混的不错,装系统不成问题,个人选择了Ubuntu12.04(别问我为什么,简单,任性),装系统简单说下吧,Win7+ubuntu12.04,在Win7下用软碟通制作个Ubuntu12.04的启动盘,百度一下,步骤很详细。
第二步,假设你的Ubuntu12.04已经安装成功了,下面就是安装hadoop之前的一些配置。需要一些Linux的命令行操作知识。妈妈说如果Ctrl+Alt+T打开命令行都不知道的话真的是一件很可怕的事。下面我一一道来。
1. 创建hadoop用户组:
| sudo addgroup hadoop |
2. 创建hadoop用户:
| sudo adduser -ingroup hadoop hadoop |
3. 给hadoop用户添加权限,打开/etc/sudoers文件:
| sudo gedit /etc/sudoers |
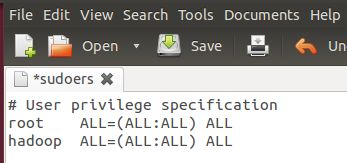
按回车键后就会打开/etc/sudoers文件了,给hadoop用户赋予root用户同样的权限。
在root ALL=(ALL:ALL) ALL下添加hadoop ALL=(ALL:ALL) ALL,
| hadoop ALL=(ALL:ALL) ALL |
第三步,安装JDK。没有JDK你跑什么java你跑什么hadoop!
使用如下命令执行即可:
| sudo apt-get install openjdk-6-jre |
第四步,修改机器名,方便操作,增加可识别度。
每当ubuntu安装成功时,我们的机器名都默认为:ubuntu ,但为了以后集群中能够容易分辨各台服务器,需要给每台机器取个不同的名字。机器名由 /etc/hostname文件决定。
1. 打开/etc/hostname文件:
| sudo gedit /etc/hostname |
2. 将/etc/hostname文件中的ubuntu改为你想取的机器名。这里我取"jingfengxu-ubuntu"。 重启系统后生效。
第五步:安装ssh服务(不懂是为了啥,大概就是服务器远程登录,照做就是了)
安装openssh-server,
| sudo apt-get install ssh openssh-server |
这时假设您已经安装好了ssh,您就可以进行第六步了哦~
首先要转换成hadoop用户,执行以下命令:
| su - hadoop |
ssh生成密钥有rsa和dsa两种生成方式,默认情况下采用rsa方式。
1. 创建ssh-key,,这里我们采用rsa方式:
| ssh-keygen -t rsa -P "" |
(注:回车后会在~/.ssh/下生成两个文件:id_rsa和id_rsa.pub这两个文件是成对出现的)
2. 进入~/.ssh/目录下,将id_rsa.pub追加到authorized_keys授权文件中,开始是没有authorized_keys文件的:
| cd ~/.ssh cat id_rsa.pub >> authorized_keys |
完成后就可以无密码登录本机了。
3. 登录localhost:
| ssh localhost |
当ssh远程登录到其它机器后,现在你控制的是远程的机器,需要执行退出命令才能重新控制本地主机。
4. 执行退出命令:
| exit |