ID3决策树
决策树
决策树(Decision Tree)是用于分类和预测的主要技术,它着眼于从一组无规则的事例推理出决策树表示形式的分类规则,采用自顶向下的递归方式,在决策树的内部节点进行属性值的比较,并根据不同属性判断从该节点向下分支,在决策树的叶节点得到结论。因此,从根节点到叶节点就对应着一条合理规则,整棵树就对应着一组表达式规则。基于决策树算法的一个最大的优点是它在学习过程中不需要使用者了解很多背景知识,只要训练事例能够用属性即结论的方式表达出来,就能使用该算法进行学习。
决策树技术是一种对海量数据集进行分类的非常有效的方法。通过构造决策树模型,提取有价值的分类规则,帮助决策者做出准确的预测已经应用在很多领域。决策树算法是一种逼近离散函数值的方法。它是一种典型的分类方法,首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后对新数据进行分析。本质上决策树是通过一系列规则对数据进行分类的过程。
决策树的典型算法有ID3、C4.5和CART等,基于决策树的分类模型有如下几个特点:(1)决策树方法结构简单,便于理解;(2)决策树模型效率高,对训练集较大的情况较为适合;(3)决策树方法通常不需要接受训练集数据外的知识;(4)决策树方法具有较高的分类精确度。
决策树算法的优点如下:(1)分类精度高;(2)生成的模式简单;(3)对噪声数据有很好的健壮性。
决策树的基本思想
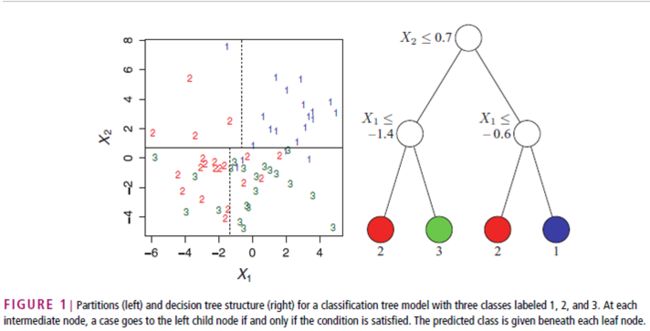
ID3决策树
ID3算法是以信息论为基础,以信息熵和信息增益度为衡量标准,从而实现对数据的归纳分类。ID3算法计算每个属性的信息增益,并选取具有最高增益的属性作为给定的测试属性。
例子
任务:
根据天气预测否去打网球
数据:
这个数据集来自Mitchell的机器学习,叫做是否去打网球play-tennis,以下数据仍然是从带逗号分割的文本文件
*play-tennis data,其中6个变量依次为:编号、天气{Sunny、Overcast、Rain}、温度{热、冷、适中}、湿度{高、正常}、风力{强、弱}以及最后是否去玩的决策{是、否}。一个建议是把这些数据导入Excel后,另复制一份去掉变量的数据到另外一个工作簿,即只保留14个观测值。这样可以方便地使用Excel的排序功能,随时查看每个变量的取值到底有多少。*/
NO. , Outlook , Temperature , Humidity , Wind , Play
, Sunny , Hot , High , Weak , No
, Sunny , Hot , High , Strong , No
, Overcast , Hot , High , Weak , Yes
, Rain , Mild , High , Weak , Yes
, Rain , Cool , Normal , Weak , Yes
, Rain , Cool , Normal , Strong , No
, Overcast , Cool , Normal , Strong , Yes
, Sunny , Mild , High , Weak , No
, Sunny , Cool , Normal , Weak , Yes
, Rain , Mild , Normal , Weak , Yes
, Sunny , Mild , Normal , Strong , Yes
, Overcast , Mild , High , Strong , Yes
, Overcast , Hot , Normal , Weak , Yes
, Rain , Mild , High , Strong , No
用决策树来预测:
决策树的形式类似于“如果天气怎么样,去玩;否则,怎么着怎么着”的树形分叉。那么问题是用哪个属性(即变量,如天气、温度、湿度和风力)最适合充当这颗树的根节点,在它上面没有其他节点,其他的属性都是它的后续节点。
那么借用上面所述的能够衡量一个属性区分以上数据样本的能力的“信息增益”(Information Gain)理论。
如果一个属性的信息增益量越大,这个属性作为一棵树的根节点就能使这棵树更简洁,比如说一棵树可以这么读成,如果风力弱,就去玩;风力强,再按天气、温度等分情况讨论,此时用风力作为这棵树的根节点就很有价值。如果说,风力弱,再又天气晴朗,就去玩;如果风力强,再又怎么怎么分情况讨论,这棵树相比就不够简洁了。
用熵来计算信息增益:
1 计算分类系统熵
类别是 是否出去玩。取值为yes的记录有9个,取值为no的有5个,即说这个样本里有9个正例,5 个负例,记为S(9+,5-),S是样本的意思(Sample)。那么P(c1) = 9/14, P(c2) = 5/14
这里熵记为Entropy(S),计算公式为:
Entropy(S)= -(9/14)*log2(9/14)-(5/14)*log2(5/14)
2 分别以Wind、Humidity、Outlook和Temperature作为根节点,计算其信息增益
我们来计算Wind的信息增益
当Wind固定为Weak时:记录有8条,其中正例6个,负例2个;
同样,取值为Strong的记录6个,正例负例个3个。我们可以计算相应的熵为:
Entropy(Weak)=-(6/8)*log(6/8)-(2/8)*log(2/8)=0.811
Entropy(Strong)=-(3/6)*log(3/6)-(3/6)*log(3/6)=1.0
现在就可以计算出相应的信息增益了:
所以,对于一个Wind属性固定的分类系统的信息量为 (8/14)*Entropy(Weak)+(6/14)*Entropy(Strong)
Gain(Wind)=Entropy(S)-(8/14)*Entropy(Weak)-(6/14)*Entropy(Strong)=0.940-(8/14)*0.811-(6/14)*1.0=0.048
这个公式的奥秘在于,8/14是属性Wind取值为Weak的个数占总记录的比例,同样6/14是其取值为Strong的记录个数与总记录数之比。
同理,如果以Humidity作为根节点:
Entropy(High)=0.985 ; Entropy(Normal)=0.592
Gain(Humidity)=0.940-(7/14)*Entropy(High)-(7/14)*Entropy(Normal)=0.151
以Outlook作为根节点:
Entropy(Sunny)=0.971 ; Entropy(Overcast)=0.0 ; Entropy(Rain)=0.971
Gain(Outlook)=0.940-(5/14)*Entropy(Sunny)-(4/14)*Entropy(Overcast)-(5/14)*Entropy(Rain)=0.247
以Temperature作为根节点:
Entropy(Cool)=0.811 ; Entropy(Hot)=1.0 ; Entropy(Mild)=0.918
Gain(Temperature)=0.940-(4/14)*Entropy(Cool)-(4/14)*Entropy(Hot)-(6/14)*Entropy(Mild)=0.029
这样我们就得到了以上四个属性相应的信息增益值:
Gain(Wind)=0.048 ;Gain(Humidity)=0.151 ; Gain(Outlook)=0.247 ;Gain(Temperature)=0.029
最后按照信息增益最大的原则选Outlook为根节点。子节点重复上面的步骤。
噪声与剪枝
机器学习实战的python代码
<span style="font-size:18px;">'''
Created on Oct 12, 2010
Decision Tree Source Code for Machine Learning in Action Ch. 3
@author: Peter Harrington
'''
from math import log
import operator
import time
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing','flippers']
#change to discrete values
return dataSet, labels
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet: #the the number of unique elements and their occurance
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2) #log base 2
return shannonEnt
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis] #chop out axis used for splitting
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #the last column is used for the labels
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures): #iterate over all the features
featList = [example[i] for example in dataSet]#create a list of all the examples of this feature
uniqueVals = set(featList) #get a set of unique values
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy #calculate the info gain; ie reduction in entropy
if (infoGain > bestInfoGain): #compare this to the best gain so far
bestInfoGain = infoGain #if better than current best, set to best
bestFeature = i
return bestFeature #returns an integer
def majorityCnt(classList):
classCount={}
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]#stop splitting when all of the classes are equal
if len(dataSet[0]) == 1: #stop splitting when there are no more features in dataSet
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:] #copy all of labels, so trees don't mess up existing labels
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
return myTree
def classify(inputTree,featLabels,testVec):
firstStr = inputTree.keys()[0]
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr)
key = testVec[featIndex]
valueOfFeat = secondDict[key]
if isinstance(valueOfFeat, dict):
classLabel = classify(valueOfFeat, featLabels, testVec)
else: classLabel = valueOfFeat
return classLabel
def storeTree(inputTree,filename):
import pickle
fw = open(filename,'w')
pickle.dump(inputTree,fw)
fw.close()
def grabTree(filename):
import pickle
fr = open(filename)
return pickle.load(fr)
def main():
data,label = createDataSet()
t1 = time.clock()
myTree = createTree(data,label)
t2 = time.clock()
print myTree
print 'execute for ',t2-t1
if __name__=='__main__':
main()
</span>
参考http://blog.csdn.net/cxf7394373/article/details/6665968