ODPS MapReduce入门
MapReduce 原理简介
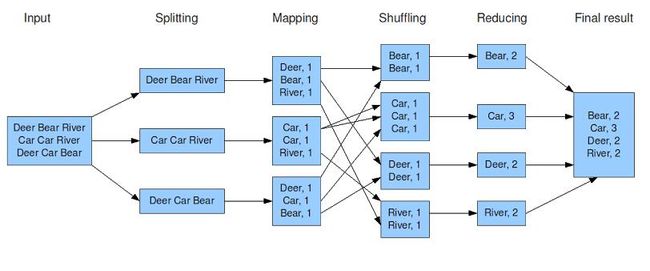
以MapReduce中最经典的wordcount应用为例,来分析一下MapReduce的全过程。这里我们要统计文件中每个单词出现的次数。
Input就是我们要处理的原始数据,一共有3行。
Splitting步骤是分配任务,这里把任务分给3台机器同时处理,每台机器只负责处理一行的数据。
Mapping步骤就是这3台机器具体要做的事情。在这里每台机器要做的就是统计一行文字里的单词频率。这里就涉及到比较重要的一个概念,就是key和value。这里key就是单词,value就是这个单词在这一行出现的次数。
Shuffling步骤就是对Mapping步骤产生的9行数据,按照key进行分组。这里分成了4组,每组交给一台电脑去处理。
Reducing,把相同key对应的value相加,每个key最终只输出一行,依然是key,value的形式输出。
Final result,把Reducing的输出合并。
(注:这里Mapping工作交给3台电脑,Reducing工作交给4台电脑的说法其实是不严谨的,具体要用多少资源来完成MapReduce由系统根据任务的状况决定,通常一台电脑需要完成多个Mapping与Reducing的工作。)
为何要如此设计?简单来说,因为MapReduce为的是能实现分布式运算,涉及到多台机器同时运算的步骤有Mapping和Reducing,参与Mapping工作的机器可以完全独立工作而不需要知道其他机器上有什么数据;参与Reducing步骤的机器,由于数据之前已经按照key进行了分组,因此其他机器上有什么数据与他毫无关系。参与计算的机器都是互相独立,完全不依赖其他机器的数据,这样就可以很方便写代码,因为所有参与Mapping工作的机器使用一模一样的代码,所有参与Reducing工作的机器也使用一模一样的代码。
我们要在ODPS上要实现MapReduce,就需要写两类代码,一类称为Mapper,另一类称为Reducer。抛开前面所说的原理,我们只需要记住以下两点:
Mapper每次只处理一行数据。即Mapper的Input是数据库中的一条记录。
Reducer每次要处理的是相同key下的所有记录,通常会是多行的。
目标
通过MapReduce计算对每个user每天对不同品牌产生的4种行为(点击、购买、收藏、购物车)的次数进行统计,并且计算在某天某user对某个brand的累计点击次数:

比如output table里第三行的意思是,user_101在06-03这天一共点了brand_20001 1次,从user_101第一次接触brand_20001以来,已经累计点了4次。
由于我们想要实现累计求和,因此我们可以在Mapping步骤中,使用(user_id,brand_id)作为key,而(type,visit_datetime)作为value。
这么一来,在Reducing步骤中,每个Reducer就能接受到某个user对某个brand的所有交互信息,这样就能衍生出我们所需的新的value,即(visit_datetime, clicks, buy, collect, basket cum_clicks)。
在ODPS中需要达到上述目标,需要动手实现3个类,这里我把他们命名为TestMapper,TestReducer,TestDriver,其中TestDriver用来进行一些任务的配置。下面来具体看看如何实现。
TestDriver
Driver主要用来进行一些格式设定。在此之前你需要在eclipse中新建一个ODPS项目。然后在项目的src上右键->new->other,在Aliyun Open Data Processing Service下选择MapReduce Driver…
接着eclipse会帮我们生成一个Driver的模板。官方写的很清楚了,所有的TODO部分是需要我们进行修改的。先来看第一个TODO:
// TODO: specify map output types
job.setMapOutputKeySchema(SchemaUtils.fromString("user_id:string,brand_id:string"));
job.setMapOutputValueSchema(SchemaUtils.fromString("type:string,visit_datetime:string"));
这是用来设定Mapper输出的时候,key与value的格式。按照之前说的,以(user_id,brand_id)为key,(type,visit_datetime)为value。
第二个TODO:
InputUtils.addTable(TableInfo.builder().tableName(args[0]).build(),job);
OutputUtils.addTable(TableInfo.builder().tableName(args[1]).build(),job);
设定input table与output table。这里把待会儿命令行调用中,第一个参数(args[0])设为input table,第二个参数(args[1])设为output table。待会儿会通过下面的命令在odps console中启动MapReduce任务。(暂时不需要搞清楚的地方都用*代替)
jar *** TestDriver t_alibaba_bigdata_user_brand_total_1 tb_output
其中args[0]就指代t_alibaba_bigdata_user_brand_total_1,args[1]就指代tb_output。
第三个TODO:
// TODO: specify a mapper
job.setMapperClass(TestMapper.class)
job.setReducerClass(TestReducer.class)
告诉系统这次任务要用的Mapper和Reducer是谁,按照上面的设定之后,系统就会通知所有负责Mapping工作的电脑待会儿使用TestMapper中的代码进行运算,通知所有负责Reducing工作的电脑待会儿使用TestReducer中的代码进行运算。
TestDriver完整代码如下(省略开头import的部分)
public class TestDriver {
public static void main (String[] args) throws OdpsException {
JobConf job = new JobConf();
// TODO: specify map output types
job.setMapOutputKeySchema(SchemaUtils.fromString("user_id:string,brand_id:string"));
job.setMapOutputValueSchema(SchemaUtils.fromString("type:string,visit_datetime:string"));
// TODO: specify input and output tables
InputUtils.addTable(TableInfo.builder().tableName(args[0]).build(),job);
OutputUtils.addTable(TableInfo.builder().tableName(args[1]).build(),job);
// TODO: specify a mapper
job.setMapperClass(TestMapper.class)
job.setReducerClass(TestReducer.class)
RunningJob rj = JobClient.runJob(job);
rj.waitForCompletion();
}
}TestMapper
之前说过,Mapper的任务就是对读入的一行数据,接着输出key和value。key和value都属于Record类,并且key和value都可以由单个或者多个字段构成,在我们这个任务中,key由(user_id,brand_id)两个字段构成,value由(type,visit_datetime)构成。
与创建TestDriver的步骤类似,使用官方的模板创建一个名为TestMapper的java代码,同样官方模板把大多数代码都生成好了。
public void setup(TaskContext context) throws IOException {
key = context.createMapOutputKeyRecord();
value = context.createMapOutputValueRecord();
}setup当中是对key和value进行初始化。其中key使用createMapOutputKeyRecord()进行初始化,value使用createMapOutputValueRecord()进行初始化。
在map函数中,record代表读入的一行数据,比如101, 20001, 0, 06-01,我们可以通过record.get(n)方法获取该行记录第n列的数据。并且方便的是,这里可以直接对读入的数据进行一个类型转换。例如record.getString()会把读入的数据转为字串,record.getBigInt()则会把读入的数据转为Long型整数。
在TestDriver的设定当中,我们已经把Mapper输出的key定为(user_id,brand_id),value定为(type,visit_datetime),在map函数中,我们可以使用key.set()与value.set()来分别赋予这4个值。
最后context.write(key, value)的意思是输出这条key-value,如果不写这行,Mapper就什么都不输出。一个Mapper可以有0个或多个key-value的输出,每调用一次context.write(key,value)就会输出一行。
TestMapper完整代码如下(省略import部分)
public class TestMapper extends MapperBase{
Record key;
Record value;
@Override
public void setup(TaskContext context) throws IOException {
key = context.createMapOutputKeyRecord();
value = context.createMapOutputValueRecord();
}
@Override
public void map(long recordNum, Record record, TaskContext context)
throws IOException {
key.set("user_id", record.getString(0));
key.set("brand_id", record.getString(1));
value.set("type", record.getString(2));
value.set("visit_datetime", record.getString(3));
context.write(key, value);
}
}TestReducer
通常Driver和Mapper方面都很简单,大多情况下,计算工作都在Reducing步骤完成,因此Reducer的代码会略多一些。同样按照前面的方法生成名为TestReducer的Reducer类。
因为我们要按天来汇总四类行为出现的次数,因此这里我使用一个TreeMap来存储每天四种行为出现的次数。
1
Map
import java.util.Map;
import java.util.TreeMap;
public class TestReducer extends ReducerMap{
Record output;
@Override
public void setup(TaskContext context) throws IOException {
output = context.createOutputRecord();
}
@Override
public void reduce(Record key, Iterator<Record> values, TaskContext context)
throws IOException {
Map<String, Long[]> typeCounter = new TreeMap<String, Long[]>();
while (values.hasNext()) {
Record val = values.next();
String date = val.getString("visit_datetime");
int type = Integer.parseInt(val.getString("type"));
if (typeCounter.containsKey(date)) {
typeCounter.get(date)[type]++;
} else {
Long[] counter = new Long[]{0L, 0L, 0L, 0L};
counter[type]++;
typeCounter.put(date, counter);
}
}
output.set(0, key.getString("user_id"));
output.set(1, key.getString("brand_id"));
Long cumClicks = 0L;
for (String date : typeCounter.keySet()){
output.set(2, date);
output.set(3, typeCounter.get(date)[0]);
output.set(4, typeCounter.get(date)[1]);
output.set(5, typeCounter.get(date)[2]);
output.set(6, typeCounter.get(date)[3]);
cumClicks += typeCounter.get(date)[0];
output.set(7, cumClicks);
context.write(output);
}
}
}打包、上传、建表、运行
1. 在Package Explorer中你之前建立的ODPS项目下的src上右键,选择Export,然后选择Java底下的JAR file。接着设定下JAR包存放的位置与文件名。这里假设我们放在C:\TOOLS\test.jar,然后点Finish。
2. 打开odps console,新建一个resource。
odps:tianchi_1234> create resource jar C:/tools/test.jar -f
- 在实际运行之前,需要先建立一个表,作为结果输出的位置。这里我们就叫它tb_output好了。进入sql,建立表格
odps:tianchi_1234> sql
odps:sql:tianchi_1234> drop table if exists tb_output;
odps:sql:tianchi_1234> create table tb_output (user_id string, brand_id string, visit_datetime string, clicks bigint,
buy bigint, collect bigint, basket bigint, cum_clicks bigint);- 在odps console下,执行MapReduce任务
odps:tianchi_1234> jar -resources test.jar --classpath c:/tools/test.jar TestDriver t_alibaba_bigdata_user_brand_total_1 tb_output;
转自:http://beader.me/2014/05/05/odps-mapreduce/?utm_source=tuicool&utm_medium=referral