Spark Standalone完全分布模式
红字部分来源于:董的博客
目前Apache Spark支持三种分布式部署方式,分别是standalone、spark on mesos和 spark on YARN,其中,第一种类似于MapReduce 1.0所采用的模式,内部实现了容错性和资源管理,后两种则是未来发展的趋势,部分容错性和资源管理交由统一的资源管理系统完成:让Spark运行在一个通用的资源管理系统之上,这样可以与其他计算框架,比如MapReduce,公用一个集群资源,最大的好处是降低运维成本和提高资源利用率(资源按需分配)。
建议先看下这个:Spark Standalone本地模式与伪分布模式
Spark这个完全分布式搭起来还是相当简单的~
主要改两个地方
1.
guo@drguo1:~$ cd /opt/spark-1.6.1-bin-hadoop2.6/conf/ guo@drguo1:/opt/spark-1.6.1-bin-hadoop2.6/conf$ cp spark-env.sh.template spark-env.sh在spark-env.sh里加入JAVA_HOME然后把worker的cpu数,内存设置一下,你可以设置的大一点,我是在虚拟机里装的。其余默认就可以了。
JAVA_HOME=/opt/Java/jdk1.8.0_73 SPARK_WORKER_CORES=1 SPARK_WORKER_MEMORY=1g2.
guo@drguo1:/opt/spark-1.6.1-bin-hadoop2.6/conf$ cp slaves.template slaves你打算在哪几个主机上放worker就在slaves里加入它的主机名
drguo2 drguo33.把整个spark目录拷给drguo2/3
guo@drguo1:/opt$ scp -r spark-1.6.1-bin-hadoop2.6/ drguo2:/opt/ guo@drguo1:/opt$ scp -r spark-1.6.1-bin-hadoop2.6/ drguo3:/opt/4.启动master
guo@drguo1:/opt/spark-1.6.1-bin-hadoop2.6$ sbin/start-master.sh starting org.apache.spark.deploy.master.Master, logging to /opt/spark-1.6.1-bin-hadoop2.6/logs/spark-guo-org.apache.spark.deploy.master.Master-1-drguo1.out guo@drguo1:/opt/spark-1.6.1-bin-hadoop2.6$ jps 3602 Jps 3572 Master
5.启动slaves
guo@drguo1:/opt/spark-1.6.1-bin-hadoop2.6$ sbin/start-slaves.sh guo@drguo1:/opt/spark-1.6.1-bin-hadoop2.6$ ssh drguo2 Welcome to Ubuntu 15.10 (GNU/Linux 4.2.0-16-generic x86_64) * Documentation: https://help.ubuntu.com/ Last login: Sun Apr 24 14:27:05 2016 from 192.168.80.149 guo@drguo2:~$ jps 2056 Worker 2139 Jps guo@drguo2:~$ ssh drguo3 Welcome to Ubuntu 15.10 (GNU/Linux 4.2.0-16-generic x86_64) * Documentation: https://help.ubuntu.com/ Last login: Wed Apr 13 16:16:22 2016 from 192.168.80.149 guo@drguo3:~$ jps 2176 Jps 2087 Worker浏览器查看drguo1:8080
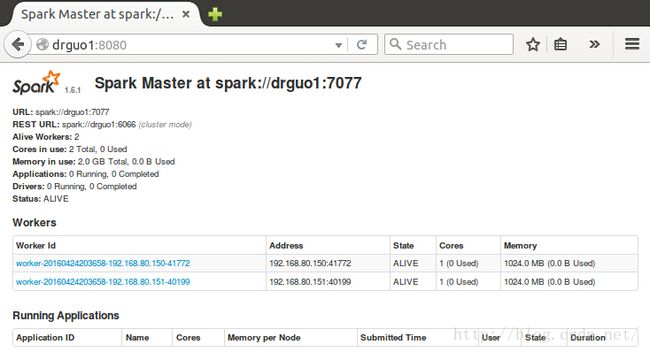
也可以直接start-all.sh
要关闭的话start改成stop就可以了
启动单个slave
- guo@guo:/opt/spark-1.6.1-bin-hadoop2.6$ sbin/start-slave.sh spark://drguo1:7077
- starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-1.6.1-bin-hadoop2.6/logs/spark-guo-org.apache.spark.deploy.worker.Worker-1-guo.out