数据挖掘方法(5):多重共线性及变量选择方法
一 概念
多重共线性: 也即使用的多个预测变量之间存在线性相关。多重共线性会导致解的不稳定,进而可能导致意外的结果。在线性代数中,基坐标必须是相互正交的,也即不相关的,此处在做多元回归预测时,必须保证预测变量之间是不相关的。
避免手段:
(1)分析之前:
a. 逐个计算预测变量之间的相关系数。
> cor(sugar$sugars,sugar$shelf) [1] 0.1004379 > cor(sugar$fiber,sugar$potass) [1] 0.9033737可以看到纤维和钾含量存在高度相关性,需要注意
b.为预测变量建立矩阵图
> #同时画多个变量的对照图需要使用 car包中的 scatterplotMatrix函数
>install.packages("car")
>library(car)
>#使用谷物数据集的 “糖”,“纤维”,“钾”三列数据
> sugar_frame<-as.data.frame(sugar[,c("糖","纤维","钾")])
>#画出对照图
> scatterplotMatrix(sugar_frame,spread=F,lty.smooth=2,var.labels=c("糖","纤维","钾"))
结果如下图:
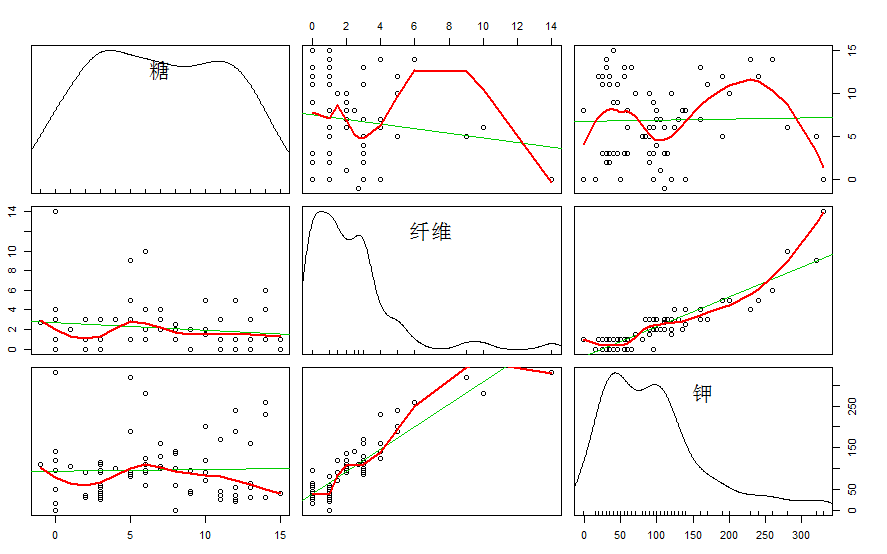
可以看到第四张和第六张是纤维和钾的相关图,可以看出他们之间有很强相关性。
(2)分析之后:方差膨胀因子(variance inflation factors,VIFs)
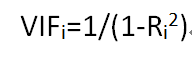
其中Ri^2表示R^2的值是通过在其他预测变量上回归分析xi得到的。假设xi和其他变量没有任何关系,那么Ri^2=0,于是可以得到VIFi=1/(1-0)=1。也即VIF最小值为1,没有最大值.
VIFi的变化对第i个系数的变化率Sbi如何产生影响,有如下公式:
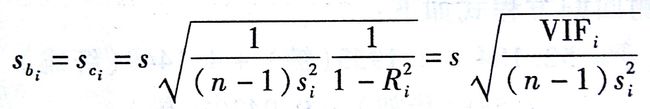
如果xi与其他预测变量不想管,那么VIFi=1,而且相关系数的标准差Sbi没有增大。然而如果xi与其他变量相关,那么较大的VIFi值会使得相关系数的标准差Sbi过度膨胀。因此,方差估计的膨胀会导致估计精度的下降。粗略的经验法则如下:
VIF>=5 模型有中度的多重共线性(相当于R^2=0.08)
VIF>=10 模型中有严重多重共线性(相当于R^2=0.90)
下面来查看谷物数据集中 糖、纤维、钾的膨胀因子
> #回归拟合
> fit<-lm(data=sugar,rating~sugars+fiber+potass)
>#注意,我们只是用了sugar数据集中包含“糖”,“纤维”,“钾”三列数据的sugar_frame
>#进行膨胀因子计算时,需要使用gvlma包中的vif函数,因此需要先安装
> install.packages("gvlma")
> library(gvlma)
Warning message:
程辑包‘gvlma’是用R版本3.0.2 来建造的
>#线性模型的综合验证
> gvlma(fit)
Call:
lm(formula = rating ~ sugars + fiber + potass, data = sugar)
Coefficients:
(Intercept) sugars fiber potass
52.6762 -2.0510 4.3701 -0.0543
ASSESSMENT OF THE LINEAR MODEL ASSUMPTIONS
USING THE GLOBAL TEST ON 4 DEGREES-OF-FREEDOM:
Level of Significance = 0.05
Call:
gvlma(x = fit)
Value p-value Decision
Global Stat 7.24415 0.12353 Assumptions acceptable.
Skewness 5.61716 0.01779 Assumptions NOT satisfied!
Kurtosis 0.02125 0.88411 Assumptions acceptable.
Link Function 0.40164 0.52624 Assumptions acceptable.
Heteroscedasticity 1.20410 0.27250 Assumptions acceptable.
>#查看膨胀因子 vif
> vif(fit)
sugars fiber potass
1.164237 6.327286 6.204047
二. 变量选择方法
为帮助数据分析人员确定在多元回归模型中应该包含哪些变量,下面是几种变量选择方法:向前选择、向后排除、逐步选择和最优子集。注意四种选择方法所使用的数据集都是 “谷物数据集”
2.1 向前选择程序
(1)对于第一个加入模型的变量,选择与回应变量相关度最高的预测变量(假设为x1)如果所有变量对模型都不重要,则停止,否则执行(2)。
(2)对其余的每个变量,F统计序列式F(x2|x1),F(x3|x1),F(x4|x1).第二次通过此算法时是,F(x3|x1,x2),F(x4|x1,x2)。选择具有最大F统计序列的变量
(3)对(2)选择出来的变量,进行F统计序列的显著性检验。如果结果模型没有重大意义,则停止,否咋将从(2)得到的变量加入到模型中,然后返回(2)。
初始:模型中没有变量
过程:把与回应变量(营养级别) 密切相关的变量选出来,如果是显著的就加入到模型中。变量糖在所有预测变量中与营养级别有最高的相关系数(r=0.762)。然后进行序列F检验,例如F(纤维|糖)和F(钠|糖)等,然后看到,F(纤维|糖)显著性检验具有最高的F统计序列值,这样变量纤维作为第二个变量加入到模型中。再进行一次序列F检验,比如F(钠|糖,纤维)和F(脂肪|糖,纤维),等等。F(钠|糖,纤维)具有最高的序列F统计值。因而钠作为第三个变量加入到模型中
结束:一次按照第二步进行,得到如下变量加入顺序:脂肪,蛋白质,碳水化合物,卡里路,维生素和钾。此时再也找不到其他显著的变量加入模型中才中断,此时的多元回归模型如下:
y=b0+b1(糖)+b2(纤维)+b3(钠)+b4(脂肪)+b5(蛋白质)+b6(碳水化合物)+b7(卡里路)+b8(钾)+e
下图显示了一个顺序选择的模型概览:
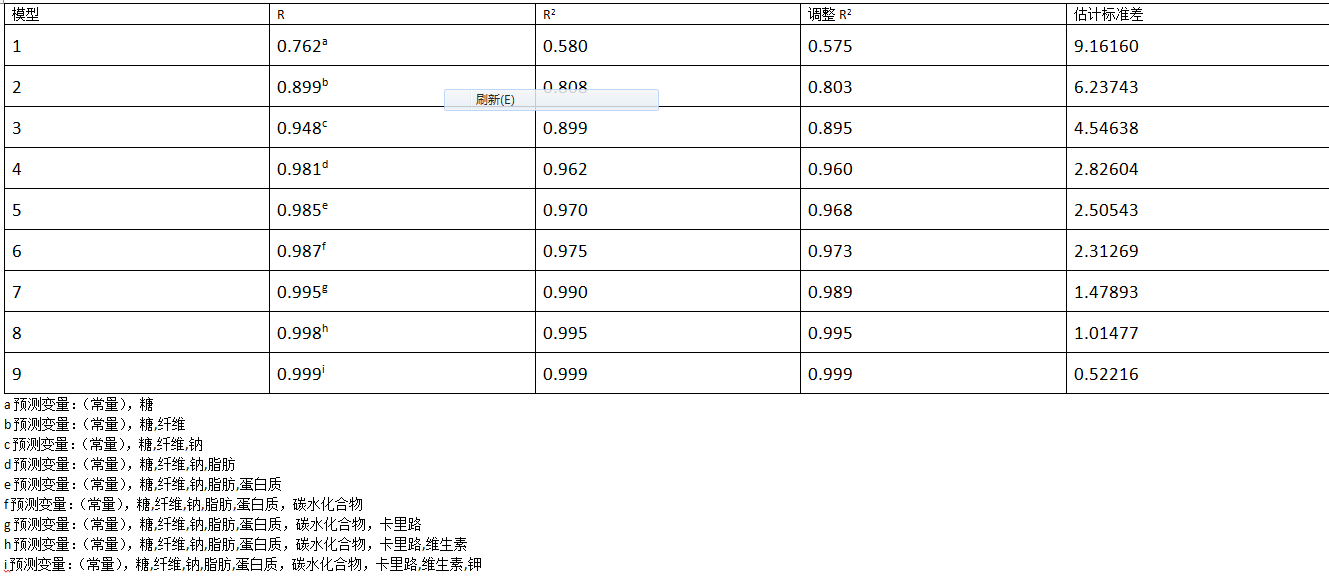
2.2 向后排除程序
向后排除程序是从模型中所有变量或者所有用户自定义变量集开始的。步骤如下:
(1)在全模型中执行向后排除,即使用所有变量的模型。例如,可能全模型中有4个变量x1,x2,x3,x4
(2)对于当前模型中的每个变量,计算出它的偏F统计量。第一次是:F(x1,x2,x3,x4)、F(x2|x1,x3,x4)、F(x3|x1,x2,x4)和F(x4|x1,x2,x3)。选择具有最小偏F统计量的比那辆,其值用Fmin表示
(3)检验Fmin的显著性。如果Fmin不显著,从模型中删除与Fmin对应的变量,然后返回执行(2),如果Fmin显著,停止这个过程。
实例:
起始时模型包含了所有变量,然后计算该模型中每个变量的偏F统计量。例如,这些统计量分别是F(重量|糖,纤维,....杯子),F(杯子|糖,纤维,.....重量|)。找到最小偏F统计量(Fmin)对应的变量。第一次是重量,此时Fmin不显著,因而从模型中去掉,接下来变量具有最小偏F统计是杯子,也是不显著的,因而需要被剔除。第三次具有最小偏F统计量的是货架2的指标变量,但是Fmin对应的p值并没有大道可以从模型中剔除,因而保留并中断。得到的模型为:
y=b0+b1(糖)+b2(纤维)+b3(钠)+b4(脂肪)+b5(蛋白质)+b6(碳水化合物)+b7(卡里路)
+b8(维生素)+b9(钾)+b10(货架2)+e
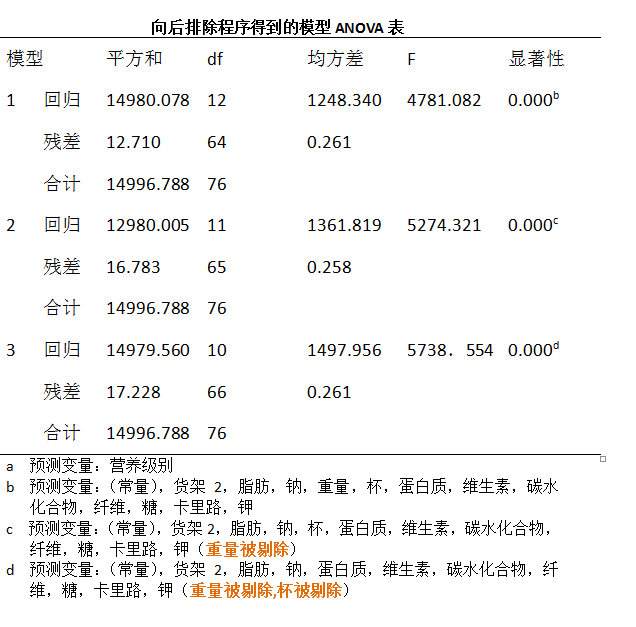
模型1表示包含所有预测变量,模型2中剔除了重量之外所有预测变量,于是有:
SS重量|所有其他变量=SS所有变量-SS重量以外所有变量=12980.078-14980.005=0.073
上表信息中显示,偏F统计量的结果为:
F(重量|所有其他变量)=SS重量|所有其他变量/MSE所有变量=0.073/0.261=.0280
F统计量的值0.28 落在F1,n-p-2=F1,72分布的40%点处,对应的p值是0.60,因而重量不应该包含在模型中。
2.3 逐步选择程序
逐步选择程序是向前选择方法的一种改进。在向前选择中会出现这种情况,当新加入的变量加入到模型时,向前选择过程中已经加入的变量可能就显得不重要了,这在向前选择方法中是没有考虑的。逐步选择过程可以检验这种情况,方法是每一步在现有变量的基础上计算每个变量的部分平方和,执行偏F检验。如果模型中有一个变量不再是显著的,这个含有最小偏F统计的变狼就会被移出模型。当不再有变量加入或者移出模型时,结束过程并得到最终模型。
2.4 最优子集程序
对于预测变量集不是太大的数据集,最优子集是一种较好方法。但是如果预测变量超过30个,最优子集方法就会产生组合爆炸,难以控制。步骤如下:
(1)分析人员需要指定需要多少个(假设为m)供筛选的模型,以及在一个模型中含有最大预测变量个数(假设 为n)
(2)对于含有一个预测变量的所有模型,例如:y=b0+b1(糖),y=b0+b1(纤维),....等。计算对应的R^2,修正R^2 和S值都计算出来,最优的m个模型是基于这些统计值得到。
(3)对于含有两个...........最优的m个模型是基于这些统计值得到。
(4)重复以上,直到达到最大的预测变量(n)个数,然后分析人员把预测变量个数为1,2,,..n的最优模型罗 列,以选择最佳总体模型。
实例,下图是最优子集程序用于谷物数据集的省略概览
(注意,整个过程比下图要复杂,例如变量数为1时,本应该有12行结果,下图中只简要用了两行,其他的也是)
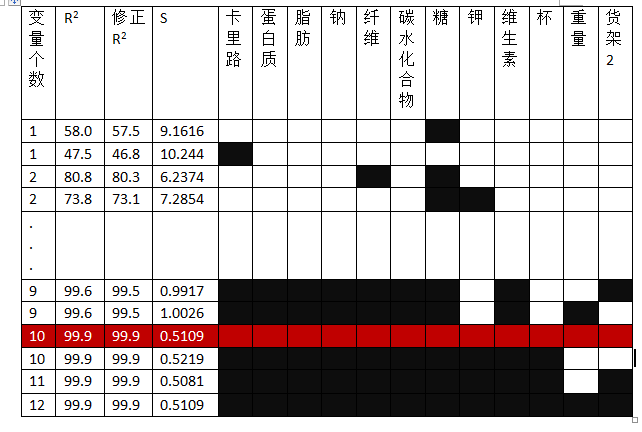
图中,每一行代表一个不同的模型,某模型中包含了哪个变量,该变量对应的方格被涂成黑色。如,第一个模型(第一行)仅包含了变量糖;第四个模型(第四行)包含了糖和钾。其中的最优模型子集被红色覆盖的那个模型(也即那一行)。