搭建高可用mongodb shard 集群以及多节点备份
mongodb通过哪些机制实现路由、分片:
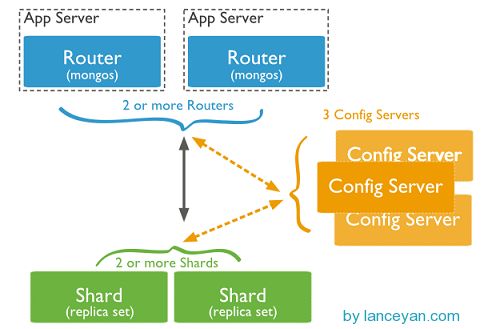
从图中可以看到有四个组件:mongos、config server、shard、replica set。
mongos,数据库集群请求的入口,所有的请求都通过mongos进行协调,不需要在应用程序添加一个路由选择器,mongos自己就是一个请求分发中心,它负责把对应的数据请求请求转发到对应的shard服务器上。在生产环境通常有多mongos作为请求的入口,防止其中一个挂掉所有的mongodb请求都没有办法操作。
config server,顾名思义为配置服务器,存储所有数据库元信息(路由、分片)的配置。mongos本身没有物理存储分片服务器和数据路由信息,只是缓存在内存里,配置服务器则实际存储这些数据。mongos第一次启动或者关掉重启就会从 config server 加载配置信息,以后如果配置服务器信息变化会通知到所有的 mongos 更新自己的状态,这样 mongos 就能继续准确路由。在生产环境通常有多个 config server 配置服务器,因为它存储了分片路由的元数据,这个可不能丢失!就算挂掉其中一台,只要还有存货, mongodb集群就不会挂掉。
shard,这就是传说中的分片了。上面提到一个机器就算能力再大也有天花板,就像军队打仗一样,一个人再厉害喝血瓶也拼不过对方的一个师。俗话说三个臭皮匠顶个诸葛亮,这个时候团队的力量就凸显出来了。在互联网也是这样,一台普通的机器做不了的多台机器来做,如下图:
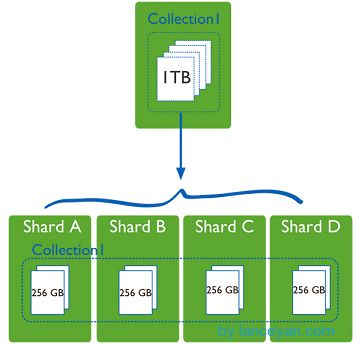
一台机器的一个数据表 Collection1 存储了 1T 数据,压力太大了!在分给4个机器后,每个机器都是256G,则分摊了集中在一台机器的压力。也许有人问一台机器硬盘加大一点不就可以了,为什么要分给四台机器呢?不要光想到存储空间,实际运行的数据库还有硬盘的读写、网络的IO、CPU和内存的瓶颈。在mongodb集群只要设置好了分片规则,通过mongos操作数据库就能自动把对应的数据操作请求转发到对应的分片机器上。在生产环境中分片的片键可要好好设置,这个影响到了怎么把数据均匀分到多个分片机器上,不要出现其中一台机器分了1T,其他机器没有分到的情况,这样还不如不分片!
replica set,上两节已经详细讲过了这个东东,怎么这里又来凑热闹!其实上图4个分片如果没有 replica set 是个不完整架构,假设其中的一个分片挂掉那四分之一的数据就丢失了,所以在高可用性的分片架构还需要对于每一个分片构建 replica set 副本集保证分片的可靠性。生产环境通常是 2个副本 + 1个仲裁。
说了这么多,还是来实战一下如何搭建高可用的mongodb集群:
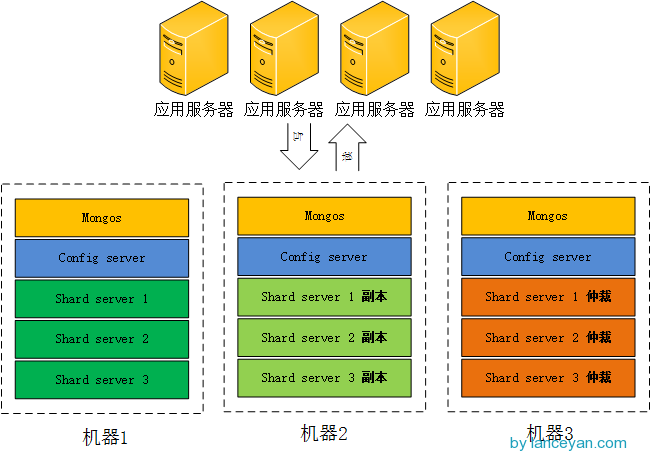
首先确定各个组件的数量,mongos 3个, config server 3个,数据分3片 shard server 3个,每个shard 有一个副本一个仲裁也就是 3 * 2 = 6 个,总共需要部署15个实例。这些实例可以部署在独立机器也可以部署在一台机器,我们这里测试资源有限,只准备了 3台机器,在同一台机器只要端口不同就可以,看一下物理部署图:
架构搭好了,安装软件!
- 1、准备机器,IP分别设置为: 192.168.0.136、192.168.0.137、192.168.0.138。
- 2、分别在每台机器上建立mongodb分片对应测试文件夹。
12
#存放mongodb数据文件mkdir-p/data/mongodbtest12#进入mongodb文件夹cd/data/mongodbtest - 3、下载mongodb的安装程序包
1
wget http://fastdl.mongodb.org/linux/mongodb-linux-x86_64-2.4.8.tgz12#解压下载的压缩包tarxvzf mongodb-linux-x86_64-2.4.8.tgz - 4、分别在每台机器建立mongos 、config 、 shard1 、shard2、shard3 五个目录。
因为mongos不存储数据,只需要建立日志文件目录即可。12#建立mongos目录mkdir-p/data/mongodbtest/mongos/log12#建立config server 数据文件存放目录mkdir-p/data/mongodbtest/config/data12#建立config server 日志文件存放目录mkdir-p/data/mongodbtest/config/log12#建立config server 日志文件存放目录mkdir-p/data/mongodbtest/mongos/log12#建立shard1 数据文件存放目录mkdir-p/data/mongodbtest/shard1/data12#建立shard1 日志文件存放目录mkdir-p/data/mongodbtest/shard1/log12#建立shard2 数据文件存放目录mkdir-p/data/mongodbtest/shard2/data12#建立shard2 日志文件存放目录mkdir-p/data/mongodbtest/shard2/log12#建立shard3 数据文件存放目录mkdir-p/data/mongodbtest/shard3/data12#建立shard3 日志文件存放目录mkdir-p/data/mongodbtest/shard3/log - 5、规划5个组件对应的端口号,由于一个机器需要同时部署 mongos、config server 、shard1、shard2、shard3,所以需要用端口进行区分。
这个端口可以自由定义,在本文 mongos为 20000, config server 为 21000, shard1为 22001 , shard2为22002, shard3为22003. - 6、在每一台服务器分别启动配置服务器。
1
/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongod--configsvr --dbpath/data/mongodbtest/config/data--port 21000 --logpath/data/mongodbtest/config/log/config.log --fork - 7、在每一台服务器分别启动mongos服务器。
1
/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongos--configdb 192.168.0.136:21000,192.168.0.137:21000,192.168.0.138:21000 --port 20000 --logpath/data/mongodbtest/mongos/log/mongos.log --fork - 8、配置各个分片的副本集。
12
#在每个机器里分别设置分片1服务器及副本集shard1/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongod--shardsvr --replSet shard1 --port 22001 --dbpath/data/mongodbtest/shard1/data--logpath/data/mongodbtest/shard1/log/shard1.log --fork --nojournal --oplogSize 10为了快速启动并节约测试环境存储空间,这里加上 nojournal 是为了关闭日志信息,在我们的测试环境不需要初始化这么大的redo日志。同样设置 oplogsize是为了降低 local 文件的大小,oplog是一个固定长度的 capped collection,它存在于”local”数据库中,用于记录Replica Sets操作日志。注意,这里的设置是为了测试!
12#在每个机器里分别设置分片2服务器及副本集shard2/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongod--shardsvr --replSet shard2 --port 22002 --dbpath/data/mongodbtest/shard2/data--logpath/data/mongodbtest/shard2/log/shard2.log --fork --nojournal --oplogSize 1012#在每个机器里分别设置分片3服务器及副本集shard3/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongod--shardsvr --replSet shard3 --port 22003 --dbpath/data/mongodbtest/shard3/data--logpath/data/mongodbtest/shard3/log/shard3.log --fork --nojournal --oplogSize 10分别对每个分片配置副本集,深入了解副本集参考本系列前几篇文章。
任意登陆一个机器,比如登陆192.168.0.136,连接mongodb
12#设置第一个分片副本集/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongo127.0.0.1:2200112#使用admin数据库use admin1234567#定义副本集配置config = { _id:"shard1", members:[{_id:0,host:"192.168.0.136:22001"},{_id:1,host:"192.168.0.137:22001"},{_id:2,host:"192.168.0.138:22001",arbiterOnly:true}]}12#初始化副本集配置rs.initiate(config);12#设置第二个分片副本集/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongo127.0.0.1:2200212#使用admin数据库use admin1234567#定义副本集配置config = { _id:"shard2", members:[{_id:0,host:"192.168.0.136:22002"},{_id:1,host:"192.168.0.137:22002"},{_id:2,host:"192.168.0.138:22002",arbiterOnly:true}]}12#初始化副本集配置rs.initiate(config);12#设置第三个分片副本集/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongo127.0.0.1:2200312#使用admin数据库use admin1234567#定义副本集配置config = { _id:"shard3", members:[{_id:0,host:"192.168.0.136:22003"},{_id:1,host:"192.168.0.137:22003"},{_id:2,host:"192.168.0.138:22003",arbiterOnly:true}]}12#初始化副本集配置rs.initiate(config); - 9、目前搭建了mongodb配置服务器、路由服务器,各个分片服务器,不过应用程序连接到 mongos 路由服务器并不能使用分片机制,还需要在程序里设置分片配置,让分片生效。
12
#连接到mongos/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongo127.0.0.1:2000012#使用admin数据库user admin12#串联路由服务器与分配副本集1db.runCommand( { addshard :"shard1/192.168.0.136:22001,192.168.0.137:22001,192.168.0.138:22001"});如里shard是单台服务器,用 db.runCommand( { addshard : “[: ]” } )这样的命令加入,如果shard是副本集,用db.runCommand( { addshard : “replicaSetName/[:port][,serverhostname2[:port],…]” });这样的格式表示 。
12#串联路由服务器与分配副本集2db.runCommand( { addshard :"shard2/192.168.0.136:22002,192.168.0.137:22002,192.168.0.138:22002"});12#串联路由服务器与分配副本集3db.runCommand( { addshard :"shard3/192.168.0.136:22003,192.168.0.137:22003,192.168.0.138:22003"});12#查看分片服务器的配置db.runCommand( { listshards : 1 } );#内容输出
1234567891011121314151617{"shards" : [{"_id" : "shard1","host" : "shard1/192.168.0.136:22001,192.168.0.137:22001"},{"_id" : "shard2","host" : "shard2/192.168.0.136:22002,192.168.0.137:22002"},{"_id" : "shard3","host" : "shard3/192.168.0.136:22003,192.168.0.137:22003"}],"ok" : 1}因为192.168.0.138是每个分片副本集的仲裁节点,所以在上面结果没有列出来。
- 10、目前配置服务、路由服务、分片服务、副本集服务都已经串联起来了,但我们的目的是希望插入数据,数据能够自动分片,就差那么一点点,一点点。。。
连接在mongos上,准备让指定的数据库、指定的集合分片生效。
12#指定testdb分片生效db.runCommand( { enablesharding :"testdb"});12#指定数据库里需要分片的集合和片键db.runCommand( { shardcollection :"testdb.table1",key : {id: 1} } )我们设置testdb的 table1 表需要分片,根据 id 自动分片到 shard1 ,shard2,shard3 上面去。要这样设置是因为不是所有mongodb 的数据库和表 都需要分片!
- 11、测试分片配置结果。
12
#连接mongos服务器/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongo127.0.0.1:2000012#使用testdbuse testdb;123#插入测试数据for(var i = 1; i <= 100000; i++)db.table1.save({id:i,"test1":"testval1"});12#查看分片情况如下,部分无关信息省掉了db.table1.stats();12345678910111213141516171819202122232425262728293031323334353637383940{"sharded":true,"ns":"testdb.table1","count":100000,"numExtents":13,"size":5600000,"storageSize":22372352,"totalIndexSize":6213760,"indexSizes": {"_id_":3335808,"id_1":2877952},"avgObjSize":56,"nindexes":2,"nchunks":3,"shards": {"shard1": {"ns":"testdb.table1","count":42183,"size":0,..."ok":1},"shard2": {"ns":"testdb.table1","count":38937,"size":2180472,..."ok":1},"shard3": {"ns":"testdb.table1","count":18880,"size":3419528,..."ok":1}},"ok":1}可以看到数据分到3个分片,各自分片数量为: shard1 “count” : 42183,shard2 “count” : 38937,shard3 “count” : 18880。已经成功了!不过分的好像不是很均匀,所以这个分片还是很有讲究的,后续再深入讨论。
- 12、java程序调用分片集群,因为我们配置了三个mongos作为入口,就算其中哪个入口挂掉了都没关系,使用集群客户端程序如下:
1234567891011121314151617181920212223242526272829
publicclassTestMongoDBShards {publicstaticvoidmain(String[] args) {try{List<ServerAddress> addresses =newArrayList<ServerAddress>();ServerAddress address1 =newServerAddress("192.168.0.136",20000);ServerAddress address2 =newServerAddress("192.168.0.137",20000);ServerAddress address3 =newServerAddress("192.168.0.138",20000);addresses.add(address1);addresses.add(address2);addresses.add(address3);MongoClient client =newMongoClient(addresses);DB db = client.getDB("testdb");DBCollection coll = db.getCollection("table1");BasicDBObject object =newBasicDBObject();object.append("id",1);DBObject dbObject = coll.findOne(object);System. out .println(dbObject);}catch(Exception e) {e.printStackTrace();}}}
整个分片集群搭建完了,思考一下我们这个架构是不是足够好呢?其实还有很多地方需要优化,比如我们把所有的仲裁节点放在一台机器,其余两台机器承担了全部读写操作,但是作为仲裁的192.168.0.138相当空闲。让机器3 192.168.0.138多分担点责任吧!架构可以这样调整,把机器的负载分的更加均衡一点,每个机器既可以作为主节点、副本节点、仲裁节点,这样压力就会均衡很多了,如图:
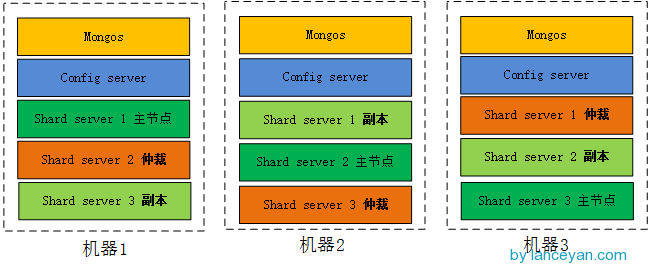
当然生产环境的数据远远大于当前的测试数据,大规模数据应用情况下我们不可能把全部的节点像这样部署,硬件瓶颈是硬伤,只能扩展机器。要用好mongodb还有很多机制需要调整,不过通过这个东东我们可以快速实现高可用性、高扩展性,所以它还是一个非常不错的Nosql组件。
再看看我们使用的mongodb java 驱动客户端 MongoClient(addresses),这个可以传入多个mongos 的地址作为mongodb集群的入口,并且可以实现自动故障转移,但是负载均衡做的好不好呢?打开源代码查看:
![]()
它的机制是选择一个ping 最快的机器来作为所有请求的入口,如果这台机器挂掉会使用下一台机器。那这样。。。。肯定是不行的!万一出现双十一这样的情况所有请求集中发送到这一台机器,这台机器很有可能挂掉。一但挂掉了,按照它的机制会转移请求到下台机器,但是这个压力总量还是没有减少啊!下一台还是可能崩溃,所以这个架构还有漏洞!不过这个文章已经太长了,后续解决吧。