LDA 两类Fisher线性判别分析及python实现
参考:《模式识别》(第三版)第4.3章-Fisher线性判别分析
机器学习中的数学(4)-线性判别分析(LDA),主成分分析(PCA):http://www.cnblogs.com/LeftNotEasy/archive/2011/01/08/lda-and-pca-machine-learning.html
线性判别分析LDA:http://www.cnblogs.com/zhangchaoyang/articles/2644095.html
LDA线性判别分析:http://blog.csdn.net/carson2005/article/details/8652586
线性分类器-基本概念:http://blog.csdn.net/u012005313/article/details/50930627
##################################################################################3
两类的线性判别问题可以看作是把所有样本都投影到一个方向上,然后在这个一维空间中确定一个分类的阈值。过这个阈值点且与投影方向垂直的超平面就是两类的分类面。
Fisher线性判别的思想就是:选择投影方向,使投影后两类相隔尽可能远,而同时每一类内部的样本又尽可能聚集。
以下部分仅讨论两类分类问题
训练样本集:![]()
![]() 类的样本:
类的样本:![]()
![]() 类的样本:
类的样本:![]()
每个样本都是一个d维列向量
目标:寻找一个投影w(w也是一个d维列向量),使得投影后的样本变成![]()
在原来的样本空间中,类均值向量为 
定义各类的类内离散度矩阵(within-class scatter matrix)为: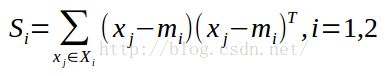
总类内离散度矩阵(pooled within-class scatter matrix)为:![]()
类间离散度矩阵(between-class scatter matrix)定义为:![]()
在投影到一维空间后,两类的均值分别为: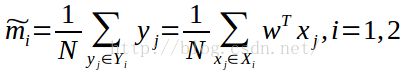
其中类内离散度不再是一个矩阵,而是一个值:
总类内离散度为:![]()
而类间离散度就成为两类均值差的平方:![]()
两类判别,就是希望寻找的投影方向使投影以后两类尽可能分开,而各类内部又尽可能聚集,这一目标可以表示成如下的准则:
这就是Fisher准则函数(Fisher's Criterion)
######################################################################3
两类线性判别的一般公式是:![]()
其中权向量w就是投影方向,在Fisher线性判别中,最优投影方向是![]()
而阈值![]() 可计算为:
可计算为: 或
或 ![]() ,
,![]() 是所有样本在投影后的均值
是所有样本在投影后的均值
所以决策规则可以写写成:![]()
如果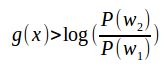 ,则测试向量x属于
,则测试向量x属于![]()
或者  ,则测试向量属于
,则测试向量属于![]()
直观的解释就是,把待决策的样本投影到Fisher判别的方向上,通过与两类均值投影的平方点相比较做出分类决策。
算法流程如下:
1.把来自两类![]() ,
, ![]() 的训练样本集X分成与
的训练样本集X分成与![]() 和
和![]() 分别对应的训练样本集
分别对应的训练样本集![]() 和
和![]()
2.计算各类样本的均值向量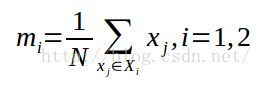
3.计算样本类内离散度矩阵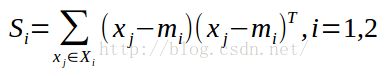
4.计算总类内离散度矩阵:![]()
5.计算![]() 的逆矩阵:
的逆矩阵:![]()
6.求解权向量:![]()
7.计算![]()
8.根据g(x)值判断测试向量属于哪一类
#########################################################################3
python实现
#!/usr/bin/env python #-*- coding: utf-8 -*- ''' LDA算法实现 ''' __author__='zj' import os import sys import numpy as np from numpy import * import operator import matplotlib import matplotlib.pyplot as plt def createDataSet(): #group=array([[1.0,1.1], [1.0,1.0], [0,0], [0,0.1], [1.1, 1.2], [0.1, 0.2]]) #labels=['A','A','B','B'] #group1=mat([[x for x in range(1,6)], [x for x in range(1,6)]]) #group2=mat([[x for x in range(10,15)], [x for x in range(15, 20)]]) group1=mat(random.random((2,8))*5+20) group2=mat(random.random((2,8))*5+2) return group1, group2 #end of createDataSet def draw(group): fig=plt.figure() plt.ylim(0, 30) plt.xlim(0, 30) ax=fig.add_subplot(111) ax.scatter(group[0,:], group[1,:]) plt.show() #end of draw #计算样本均值 #参数samples为nxm维矩阵,其中n表示维数,m表示样本个数 def compute_mean(samples): mean_mat=mean(samples, axis=1) return mean_mat #end of compute_mean #计算样本类内离散度 #参数samples表示样本向量矩阵,大小为nxm,其中n表示维数,m表示样本个数 #参数mean表示均值向量,大小为1xd,d表示维数,大小与样本维数相同,即d=m def compute_withinclass_scatter(samples, mean): #获取样本维数,样本个数 dimens,nums=samples.shape[:2] #将所有样本向量减去均值向量 samples_mean=samples-mean #初始化类内离散度矩阵 s_in=0 for i in range(nums): x=samples_mean[:,i] s_in+=dot(x,x.T) #endfor return s_in #end of compute_mean if __name__=='__main__': group1,group2=createDataSet() print "group1 :\n",group1 print "group2 :\n",group2 draw(hstack((group1, group2))) mean1=compute_mean(group1) print "mean1 :\n",mean1 mean2=compute_mean(group2) print "mean2 :\n",mean2 s_in1=compute_withinclass_scatter(group1, mean1) print "s_in1 :\n",s_in1 s_in2=compute_withinclass_scatter(group2, mean2) print "s_in2 :\n",s_in2 #求总类内离散度矩阵 s=s_in1+s_in2 print "s :\n",s #求s的逆矩阵 s_t=s.I print "s_t :\n",s_t #求解权向量 w=dot(s_t, mean1-mean2) print "w :\n",w #判断(2,3)是在哪一类 test1=mat([1,1]) g=dot(w.T, test1.T-0.5*(mean1-mean2)) print "g(x) :",g #判断(4,5)是在哪一类 test2=mat([10,10]) g=dot(w.T, test2.T-0.5*(mean1-mean2)) print "g(x) :",g #endif
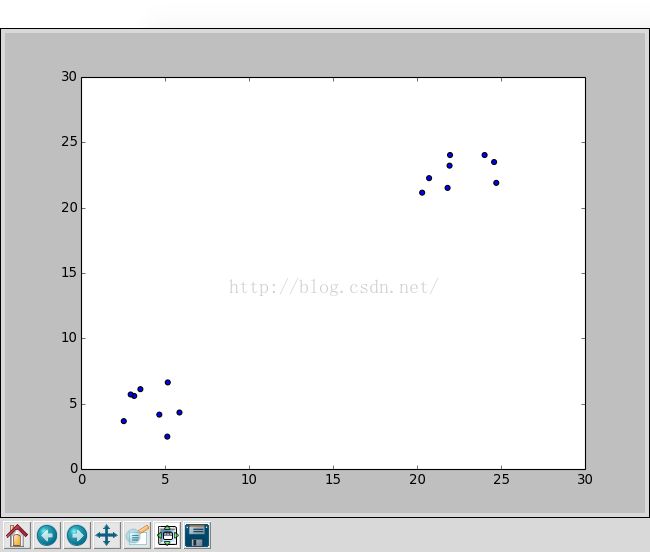
![]()
#####################################################################
用到的一些python函数解释:
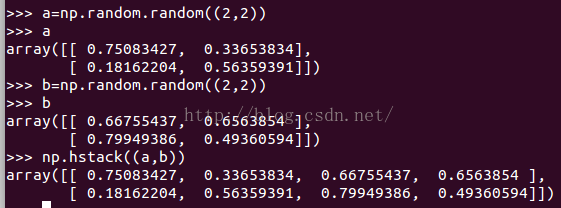
numpy.hstack:

函数功能:连接多个数组,每个数组大小一致,按行连接
######################################################################
some problems:
1.类内离散度矩阵![]() 必须是非奇异的(样本数大于维数时通常是非奇异的,非奇异表示矩阵行列式不为0,为可逆矩阵)
必须是非奇异的(样本数大于维数时通常是非奇异的,非奇异表示矩阵行列式不为0,为可逆矩阵)
2.LDA是监督算法(supervised algorithm),降维后的维数和类别数c相关,维数最多到c-1类。比如,2类分类问题,则降维后最多1维