- 大数据学习(67)- Flume、Sqoop、Kafka、DataX对比
viperrrrrrr
大数据学习flumekafkasqoopdatax
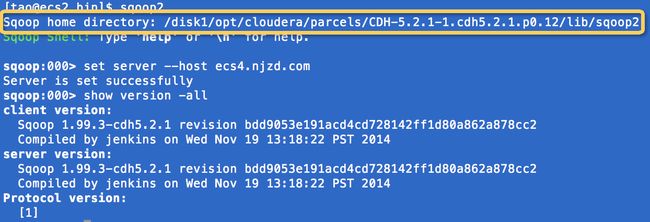
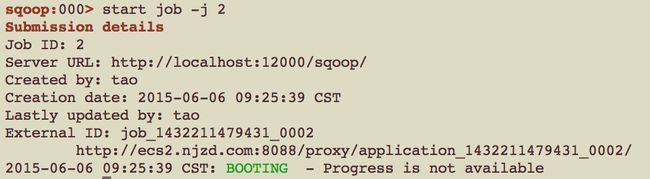
大数据学习系列专栏:哲学语录:用力所能及,改变世界。如果觉得博主的文章还不错的话,请点赞+收藏⭐️+留言支持一下博主哦工具主要作用数据流向实时性数据源/目标应用场景Flume实时日志采集与传输从数据源到存储系统实时日志文件、网络流量等→HDFS、HBase、Kafka等日志收集、实时监控、实时分析Sqoop关系型数据库与Hadoop间数据同步关系型数据库→Hadoop生态系统(HDFS、Hive、
- SpringBoot集成Flink-CDC
whiteBrocade
springflinkmysqljava-activemqkafkaelasticsearch
FlinkCDCCDC相关介绍CDC是什么?CDC是ChangeDataCapture(变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到MQ以供其他服务进行订阅及消费CDC分类CDC主要分为基于查询和基于Binlog基于查询基于Binlog开源产品Sqoop、DataXCanal、Maxwell、Debe
- jdbc连接数据库步骤oracle,jdbc连接oracle数据库的步骤
weixin_39726044
使用E-MapReduce集群sqoop组件同步云外Oracle数据库数据到集群hiveE-MapReduce集群sqoop组件可以同步数据库的数据到集群里,不同的数据库源网络配置有一些差异网络配置。最常用的场景是从rdsmysql同步数据,最近也有用户询问如何同步云外专有Oracle数据库数据到hive。云外专有数据库需要集群所有节点通过公网访问,要创建VPC网络,使用VPC网络...文章鸿初2
- 强大的ETL利器—DataFlow3.0
lixiang2114
数据分析etlflumesqoop数据库数据仓库
产品开发背景DataFlow是基于应用数据流程的一套分布式ETL系统服务组件,其前身是LogCollector2.0日志系统框架,自LogCollector3.0版本开始正式更名为DataFlow3.0。目前常用的ETL工具Flume、LogStash、Kettle、Sqoop等也可以完成数据的采集、传输、转换和存储;但这些工具都不具备事务一致性。比如Flume工具仅能应用到通信质量无障碍的局域网
- 本地Oracle数据库复制数据到Apache Hive的Linux服务器集群的分步流程
weixin_30777913
数据库大数据hive
我们已经有安装ApacheHive的Linux服务器集群,它可以连接到一个OracleRDS数据库,需要在该Linux服务器上安装配置sqoop,然后将OracleRDS数据库中所有的表数据复制到Hive。为了将本地Oracle数据库中的所有表数据复制到ApacheHiveLinux服务器集群中,您可以遵循以下详细步骤:第一步:安装和配置Sqoop1.下载并安装Sqoop您可以从ApacheSqo
- 大数据-257 离线数仓 - 数据质量监控 监控方法 Griffin架构
m0_74823705
面试学习路线阿里巴巴大数据架构
点一下关注吧!!!非常感谢!!持续更新!!!Java篇开始了!目前开始更新MyBatis,一起深入浅出!目前已经更新到了:Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis(已更完)Kafka(已更完)Spark(已更完)Flink(已更完)ClickHouse(已
- 实现MySQL数据全量迁移至Hive的简单脚本
xiaoxaoyu
数仓数据仓库
1、主要思路:编写脚本执行建表语句、sqoop命令1.1、编写建表语句脚本思路:在虚拟机下执行hive-f/脚本路径即可执行hql脚本1.2、编写shell脚本脚本内容为分为两部分执行hql建表语句脚本sqoop迁移命令2、示范案例:2.1、hive建表脚本:--示范案例dropdatabaseifexistsods_myshopscascade;createdatabaseods_myshops
- 5. clickhouse 单节点多实例部署
Toroidals
大数据组件安装部署教程clickhouse单节点多实例伪分布安装部署
环境说明:主机名:cmc01为例操作系统:centos7安装部署软件版本部署方式centos7zookeeperzookeeper-3.4.10伪分布式hadoophadoop-3.1.3伪分布式hivehive-3.1.3-bin伪分布式clickhouse21.11.10.1-2单节点多实例dolphinscheduler3.0.0单节点kettlepdi-ce-9.3.0.0单节点sqoop
- 大数据-267 实时数仓 - ODS Lambda架构 Kappa架构 核心思想
m0_74823336
面试学习路线阿里巴巴大数据架构
点一下关注吧!!!非常感谢!!持续更新!!!Java篇开始了!MyBatis更新完毕目前开始更新Spring,一起深入浅出!目前已经更新到了:Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis(已更完)Kafka(已更完)Spark(已更完)Flink(已更完)Cl
- sqoop导出orc数据至mysql,将Sqoop导入为OrC文件
终有尽头
IsthereanyoptioninsqooptoimportdatafromRDMSandstoreitasORCfileformatinHDFS?Alternativestried:importedastextformatandusedatemptabletoreadinputastextfileandwritetohdfsasorcinhive解决方案AtleastinSqoop1.4.5t
- sqoop从orc文件到oracle,Sqoop import as OrC file
余革革
问题IsthereanyoptioninsqooptoimportdatafromRDMSandstoreitasORCfileformatinHDFS?Alternativestried:importedastextformatandusedatemptabletoreadinputastextfileandwritetohdfsasorcinhive回答1:AtleastinSqoop1.4.
- Hadoop---(6)Sqoop(数据传输)
Mr Cao
sqoop大数据
6.SqoopSqoop是一个用于hadoop数据和结构化数据之间转换的工具。全称SQL-TO-HADOOP.它可以把hadoop数据,包括hive和hbase存储的数据转化为结构化数据也就是数据库的数据,也可以把关系型数据库数据转化为hadoop数据这些转换操作全是通过Hadoop的MapTask来完成的,并不会涉及到Reduce操作。这是因为我们只是进行数据的拷贝,并不会对数据进行处理或者计算
- Sqoop 支持 ORC 文件格式
吃鱼的羊
sqoop
ORC介绍ORC文件格式是Hive0.11.0版本引入的一种文件格式。ORC的引入是为了解决其他Hive文件格式的局限性。使用ORC文件格式提升Hive读取、写入及处理数据的性能。与RCFile对比,ORC文件格式有很多优点:每个Task只输出一个文件,降低NameNode的负载。Hive数据类型支持,包括:datetime、decimal以及复杂数据类型(struct、list、map、unio
- 本地Apache Hive的Linux服务器集群复制数据到SQL Server数据库的分步流程
weixin_30777913
数据库数据仓库hivesqlserver
我们已经有安装ApacheHive的Linux服务器集群,它可以连接到一个SQLServerRDS数据库,需要在该Linux服务器上安装配置sqoop,然后将Hive中所有的表数据复制到SQLServerRDS数据库。以下是分步指南,用于在Linux服务器上安装配置Sqoop并将Hive表数据迁移至SQLServerRDS:1.安装Sqoop步骤:下载Sqoop前往ApacheSqoop下载页面,
- 大数据开发的底层逻辑是什么?
瑰茵
大数据
大数据开发的底层逻辑主要围绕数据的生命周期进行,包括数据的采集、存储、处理、分析和可视化等环节。以下是大数据开发的一些关键底层逻辑:数据采集:目的:从不同的数据源(如日志文件、数据库、传感器等)收集数据。方法:使用数据采集工具(如ApacheFlume、ApacheKafka、ApacheSqoop)来捕获和传输数据。数据存储:目的:将收集到的数据存储在可靠且可扩展的存储系统中。方法:使用分布式文
- Sqoop数据导出 第3关:Hive数据导出至MySQL中
是草莓熊吖
sqoopEducoderhivehadoop数据仓库sqoop
为了完成本关任务,你需要掌握:Hive数据导出至MySQL中。Hive数据导入MySQL中MySQL建表因为之前已经创建过数据库了,我们直接使用之前的数据库hdfsdb,在数据库中建表project,表结构如下:名类状态pro_noint主键,序号pro_namevarchar(20)课程名pro_teachervarchar(20)课程老师#首先进入MySQLmysql-uroot-p12312
- 把hive中的数据导出到mysql
樱浅沐冰
笔记hadoophivemysql
注意事项!!!!1.hive中的表的字段和类型必须和mysql表中的字段和类型一样不如hive中的stnamevarchar(50),那么mysql中的字段和类型也必须为stnamestring2.sqoopexport--connectjdbc:mysql://localhost:3306/xiandian--usernameroot--passwordbigdata--tablem1--hca
- Hive数据仓库中的数据导出到MySQL的数据表不成功
sin2201
出错问题数据仓库hivemysql
可能的原因:(1)没有下载flume和sqoop(2)权限问题:因为MySQL数据库拒绝了root用户从hadoop3主机的连接请求,root用户没有从hadoop3主机进行连接的权限解决:通过MySQL的授权命令来授予权限mysql>GRANTALLPRIVILEGESONsqoop_weblog.*TO'root'@'hadoop3'IDENTIFIEDBY'2020';QueryOK,0ro
- 基于飞腾平台的Sqoop的安装配置
【写在前面】飞腾开发者平台是基于飞腾自身强大的技术基础和开放能力,聚合行业内优秀资源而打造的。该平台覆盖了操作系统、算法、数据库、安全、平台工具、虚拟化、存储、网络、固件等多个前沿技术领域,包含了应用使能套件、软件仓库、软件支持、软件适配认证四大板块,旨在共享尖端技术,为开发者提供一个涵盖多领域的开发平台和工具套件。点击这里开始你的技术升级之旅吧本文分享至飞腾开发者平台《飞腾平台Sqoop1.99
- SeaTunnel 与 DataX 、Sqoop、Flume、Flink CDC 对比
不二人生
#数据集成工具SeaTunnel
文章目录SeaTunnel与DataX、Sqoop、Flume、FlinkCDC对比同类产品横向对比2.1、高可用、健壮的容错机制2.2、部署难度和运行模式2.3、支持的数据源丰富度2.4、内存资源占用2.5、数据库连接占用2.6、自动建表2.7、整库同步2.8、断点续传2.9、多引擎支持2.10、数据转换算子2.11、性能2.12、离线同步2.13、增量同步&实时同步2.14、CDC同步2.15
- 大数据-257 离线数仓 - 数据质量监控 监控方法 Griffin架构
武子康
大数据离线数仓大数据数据仓库java后端hadoophive
点一下关注吧!!!非常感谢!!持续更新!!!Java篇开始了!目前开始更新MyBatis,一起深入浅出!目前已经更新到了:Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis(已更完)Kafka(已更完)Spark(已更完)Flink(已更完)ClickHouse(已
- hive学习笔记之五:分桶
程序员欣宸
欢迎访问我的GitHubhttps://github.com/zq2599/blog_demos内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;《hive学习笔记》系列导航基本数据类型复杂数据类型内部表和外部表分区表分桶HiveQL基础内置函数Sqoop基础UDF用户自定义聚合函数(UDAF)UDTF本篇概览本文是《hive学习笔记》的第五篇
- 学习大数据DAY43 Sqoop 安装,配置环境和使用
工科小石头
大数据培训学习大数据sqoophivehadoop
目录sqoop安装配置mysqlsqoop安装sqoop指令集sqoop使用sqoop创建hive表sqoop全量导入表sqoop增量导入表sqoop全量导出表sqoop分区表导入表sqoop分区表导出表上机练习sqoop安装配置mysqlcreatedatabasetestDEFAULTCHARACTERSETutf8DEFAULTCOLLATEutf8_general_ci;--创建数据库sh
- python读取hive数据库_利用pyhive将hive查询数据导入到mysql
weixin_39939668
python读取hive数据库
在大数据工作中经常碰到需要将hive查询数据导入到mysql的需求,常见的方法主要有两种,一是sqoop,另一种则是pyhive。本文主要讲的就是python的pyhive库的安装与使用。pyhive作用远程连接hive数据库,运行hivesql,而不需要登录到安装有hive的服务器上去可以更方便处理更多连续命令,可以封装一些经常需要复用的命令脚本化,不需要编译,随时改,随时执行看结果方便对hiv
- 大数据毕业设计hadoop+spark+hive微博舆情情感分析 知识图谱微博推荐系统
qq_79856539
javaweb大数据hadoop课程设计
(一)Selenium自动化Python爬虫工具采集新浪微博评论、热搜、文章等约10万条存入.csv文件作为数据集;(二)使用pandas+numpy或MapReduce对数据进行数据清洗,生成最终的.csv文件并上传到hdfs;(三)使用hive数仓技术建表建库,导入.csv数据集;(四)离线分析采用hive_sql完成,实时分析利用Spark之Scala完成;(五)统计指标使用sqoop导入m
- 从零到一建设数据中台 - 关键技术汇总
我码玄黄
数据中台数据挖掘数据分析大数据
一、数据中台关键技术汇总语言框架:Java、Maven、SpringBoot数据分布式采集:Flume、Sqoop、kettle数据分布式存储:HadoopHDFS离线批处理计算:MapReduce、Spark、Flink实时流式计算:Storm/SparkStreaming、Flink批处理消息队列:Kafka查询分析:Hbase、Hive、ClickHouse、Presto搜索引擎:Elast
- Sqoop一些常用命令及参数
大数据小同学
常用命令列举这里给大家列出来了一部分Sqoop操作时的常用参数,以供参考,需要深入学习的可以参看对应类的源代码。命令类说明importImportTool将数据导入到集群exportExportTool将集群数据导出codegenCodeGenTool获取数据库中某张表数据生成Java并打包Jarcreate-hive-tableCreateHiveTableTool创建Hive表evalEval
- hive学习笔记之九:基础UDF
程序员欣宸
欢迎访问我的GitHubhttps://github.com/zq2599/blog_demos内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;《hive学习笔记》系列导航基本数据类型复杂数据类型内部表和外部表分区表分桶HiveQL基础内置函数Sqoop基础UDF用户自定义聚合函数(UDAF)UDTF本篇概览本文是《hive学习笔记》的第九篇
- Hadoop生态圈
陈超Terry的技术屋
生态圈1.HBase的数据存储在HDFS里2.MapReduce可以计算HBase里的数据,也可以计算HDFS里的数据3.Hive是数据分析数据引擎,也是MapReduce模型,支持SQL4.Pig也是一个数据分析引擎,不支持SQL,有自己的PigLatin数据5.Sqoop是数据采集工具,针对关系数据库6.Flume是针对文件等数据的采集7.Hadoop的HA通过Zookeeper来实现8.HU
- hive学习笔记之三:内部表和外部表
程序员欣宸
欢迎访问我的GitHubhttps://github.com/zq2599/blog_demos内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;《hive学习笔记》系列导航基本数据类型复杂数据类型内部表和外部表分区表分桶HiveQL基础内置函数Sqoop基础UDF用户自定义聚合函数(UDAF)UDTF本篇概览本文是《hive学习笔记》系列的第
- 安装数据库首次应用
Array_06
javaoraclesql
可是为什么再一次失败之后就变成直接跳过那个要求
enter full pathname of java.exe的界面
这个java.exe是你的Oracle 11g安装目录中例如:【F:\app\chen\product\11.2.0\dbhome_1\jdk\jre\bin】下的java.exe 。不是你的电脑安装的java jdk下的java.exe!
注意第一次,使用SQL D
- Weblogic Server Console密码修改和遗忘解决方法
bijian1013
Welogic
在工作中一同事将Weblogic的console的密码忘记了,通过网上查询资料解决,实践整理了一下。
一.修改Console密码
打开weblogic控制台,安全领域 --> myrealm -->&n
- IllegalStateException: Cannot forward a response that is already committed
Cwind
javaServlets
对于初学者来说,一个常见的误解是:当调用 forward() 或者 sendRedirect() 时控制流将会自动跳出原函数。标题所示错误通常是基于此误解而引起的。 示例代码:
protected void doPost() {
if (someCondition) {
sendRedirect();
}
forward(); // Thi
- 基于流的装饰设计模式
木zi_鸣
设计模式
当想要对已有类的对象进行功能增强时,可以定义一个类,将已有对象传入,基于已有的功能,并提供加强功能。
自定义的类成为装饰类
模仿BufferedReader,对Reader进行包装,体现装饰设计模式
装饰类通常会通过构造方法接受被装饰的对象,并基于被装饰的对象功能,提供更强的功能。
装饰模式比继承灵活,避免继承臃肿,降低了类与类之间的关系
装饰类因为增强已有对象,具备的功能该
- Linux中的uniq命令
被触发
linux
Linux命令uniq的作用是过滤重复部分显示文件内容,这个命令读取输入文件,并比较相邻的行。在正常情 况下,第二个及以后更多个重复行将被删去,行比较是根据所用字符集的排序序列进行的。该命令加工后的结果写到输出文件中。输入文件和输出文件必须不同。如 果输入文件用“- ”表示,则从标准输入读取。
AD:
uniq [选项] 文件
说明:这个命令读取输入文件,并比较相邻的行。在正常情况下,第二个
- 正则表达式Pattern
肆无忌惮_
Pattern
正则表达式是符合一定规则的表达式,用来专门操作字符串,对字符创进行匹配,切割,替换,获取。
例如,我们需要对QQ号码格式进行检验
规则是长度6~12位 不能0开头 只能是数字,我们可以一位一位进行比较,利用parseLong进行判断,或者是用正则表达式来匹配[1-9][0-9]{4,14} 或者 [1-9]\d{4,14}
&nbs
- Oracle高级查询之OVER (PARTITION BY ..)
知了ing
oraclesql
一、rank()/dense_rank() over(partition by ...order by ...)
现在客户有这样一个需求,查询每个部门工资最高的雇员的信息,相信有一定oracle应用知识的同学都能写出下面的SQL语句:
select e.ename, e.job, e.sal, e.deptno
from scott.emp e,
(se
- Python调试
矮蛋蛋
pythonpdb
原文地址:
http://blog.csdn.net/xuyuefei1988/article/details/19399137
1、下面网上收罗的资料初学者应该够用了,但对比IBM的Python 代码调试技巧:
IBM:包括 pdb 模块、利用 PyDev 和 Eclipse 集成进行调试、PyCharm 以及 Debug 日志进行调试:
http://www.ibm.com/d
- webservice传递自定义对象时函数为空,以及boolean不对应的问题
alleni123
webservice
今天在客户端调用方法
NodeStatus status=iservice.getNodeStatus().
结果NodeStatus的属性都是null。
进行debug之后,发现服务器端返回的确实是有值的对象。
后来发现原来是因为在客户端,NodeStatus的setter全部被我删除了。
本来是因为逻辑上不需要在客户端使用setter, 结果改了之后竟然不能获取带属性值的
- java如何干掉指针,又如何巧妙的通过引用来操作指针————>说的就是java指针
百合不是茶
C语言的强大在于可以直接操作指针的地址,通过改变指针的地址指向来达到更改地址的目的,又是由于c语言的指针过于强大,初学者很难掌握, java的出现解决了c,c++中指针的问题 java将指针封装在底层,开发人员是不能够去操作指针的地址,但是可以通过引用来间接的操作:
定义一个指针p来指向a的地址(&是地址符号):
- Eclipse打不开,提示“An error has occurred.See the log file ***/.log”
bijian1013
eclipse
打开eclipse工作目录的\.metadata\.log文件,发现如下错误:
!ENTRY org.eclipse.osgi 4 0 2012-09-10 09:28:57.139
!MESSAGE Application error
!STACK 1
java.lang.NoClassDefFoundError: org/eclipse/core/resources/IContai
- spring aop实例annotation方法实现
bijian1013
javaspringAOPannotation
在spring aop实例中我们通过配置xml文件来实现AOP,这里学习使用annotation来实现,使用annotation其实就是指明具体的aspect,pointcut和advice。1.申明一个切面(用一个类来实现)在这个切面里,包括了advice和pointcut
AdviceMethods.jav
- [Velocity一]Velocity语法基础入门
bit1129
velocity
用户和开发人员参考文档
http://velocity.apache.org/engine/releases/velocity-1.7/developer-guide.html
注释
1.行级注释##
2.多行注释#* *#
变量定义
使用$开头的字符串是变量定义,例如$var1, $var2,
赋值
使用#set为变量赋值,例
- 【Kafka十一】关于Kafka的副本管理
bit1129
kafka
1. 关于request.required.acks
request.required.acks控制者Producer写请求的什么时候可以确认写成功,默认是0,
0表示即不进行确认即返回。
1表示Leader写成功即返回,此时还没有进行写数据同步到其它Follower Partition中
-1表示根据指定的最少Partition确认后才返回,这个在
Th
- lua统计nginx内部变量数据
ronin47
lua nginx 统计
server {
listen 80;
server_name photo.domain.com;
location /{set $str $uri;
content_by_lua '
local url = ngx.var.uri
local res = ngx.location.capture(
- java-11.二叉树中节点的最大距离
bylijinnan
java
import java.util.ArrayList;
import java.util.List;
public class MaxLenInBinTree {
/*
a. 1
/ \
2 3
/ \ / \
4 5 6 7
max=4 pass "root"
- Netty源码学习-ReadTimeoutHandler
bylijinnan
javanetty
ReadTimeoutHandler的实现思路:
开启一个定时任务,如果在指定时间内没有接收到消息,则抛出ReadTimeoutException
这个异常的捕获,在开发中,交给跟在ReadTimeoutHandler后面的ChannelHandler,例如
private final ChannelHandler timeoutHandler =
new ReadTim
- jquery验证上传文件样式及大小(好用)
cngolon
文件上传jquery验证
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<script src="jquery1.8/jquery-1.8.0.
- 浏览器兼容【转】
cuishikuan
css浏览器IE
浏览器兼容问题一:不同浏览器的标签默认的外补丁和内补丁不同
问题症状:随便写几个标签,不加样式控制的情况下,各自的margin 和padding差异较大。
碰到频率:100%
解决方案:CSS里 *{margin:0;padding:0;}
备注:这个是最常见的也是最易解决的一个浏览器兼容性问题,几乎所有的CSS文件开头都会用通配符*来设
- Shell特殊变量:Shell $0, $#, $*, $@, $?, $$和命令行参数
daizj
shell$#$?特殊变量
前面已经讲到,变量名只能包含数字、字母和下划线,因为某些包含其他字符的变量有特殊含义,这样的变量被称为特殊变量。例如,$ 表示当前Shell进程的ID,即pid,看下面的代码:
$echo $$
运行结果
29949
特殊变量列表 变量 含义 $0 当前脚本的文件名 $n 传递给脚本或函数的参数。n 是一个数字,表示第几个参数。例如,第一个
- 程序设计KISS 原则-------KEEP IT SIMPLE, STUPID!
dcj3sjt126com
unix
翻到一本书,讲到编程一般原则是kiss:Keep It Simple, Stupid.对这个原则深有体会,其实不仅编程如此,而且系统架构也是如此。
KEEP IT SIMPLE, STUPID! 编写只做一件事情,并且要做好的程序;编写可以在一起工作的程序,编写处理文本流的程序,因为这是通用的接口。这就是UNIX哲学.所有的哲学真 正的浓缩为一个铁一样的定律,高明的工程师的神圣的“KISS 原
- android Activity间List传值
dcj3sjt126com
Activity
第一个Activity:
import java.util.ArrayList;import java.util.HashMap;import java.util.List;import java.util.Map;import android.app.Activity;import android.content.Intent;import android.os.Bundle;import a
- tomcat 设置java虚拟机内存
eksliang
tomcat 内存设置
转载请出自出处:http://eksliang.iteye.com/blog/2117772
http://eksliang.iteye.com/
常见的内存溢出有以下两种:
java.lang.OutOfMemoryError: PermGen space
java.lang.OutOfMemoryError: Java heap space
------------
- Android 数据库事务处理
gqdy365
android
使用SQLiteDatabase的beginTransaction()方法可以开启一个事务,程序执行到endTransaction() 方法时会检查事务的标志是否为成功,如果程序执行到endTransaction()之前调用了setTransactionSuccessful() 方法设置事务的标志为成功则提交事务,如果没有调用setTransactionSuccessful() 方法则回滚事务。事
- Java 打开浏览器
hw1287789687
打开网址open浏览器open browser打开url打开浏览器
使用java 语言如何打开浏览器呢?
我们先研究下在cmd窗口中,如何打开网址
使用IE 打开
D:\software\bin>cmd /c start iexplore http://hw1287789687.iteye.com/blog/2153709
使用火狐打开
D:\software\bin>cmd /c start firefox http://hw1287789
- ReplaceGoogleCDN:将 Google CDN 替换为国内的 Chrome 插件
justjavac
chromeGooglegoogle apichrome插件
Chrome Web Store 安装地址: https://chrome.google.com/webstore/detail/replace-google-cdn/kpampjmfiopfpkkepbllemkibefkiice
由于众所周知的原因,只需替换一个域名就可以继续使用Google提供的前端公共库了。 同样,通过script标记引用这些资源,让网站访问速度瞬间提速吧
- 进程VS.线程
m635674608
线程
资料来源:
http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/001397567993007df355a3394da48f0bf14960f0c78753f000 1、Apache最早就是采用多进程模式 2、IIS服务器默认采用多线程模式 3、多进程优缺点 优点:
多进程模式最大
- Linux下安装MemCached
字符串
memcached
前提准备:1. MemCached目前最新版本为:1.4.22,可以从官网下载到。2. MemCached依赖libevent,因此在安装MemCached之前需要先安装libevent。2.1 运行下面命令,查看系统是否已安装libevent。[root@SecurityCheck ~]# rpm -qa|grep libevent libevent-headers-1.4.13-4.el6.n
- java设计模式之--jdk动态代理(实现aop编程)
Supanccy2013
javaDAO设计模式AOP
与静态代理类对照的是动态代理类,动态代理类的字节码在程序运行时由Java反射机制动态生成,无需程序员手工编写它的源代码。动态代理类不仅简化了编程工作,而且提高了软件系统的可扩展性,因为Java 反射机制可以生成任意类型的动态代理类。java.lang.reflect 包中的Proxy类和InvocationHandler 接口提供了生成动态代理类的能力。
&
- Spring 4.2新特性-对java8默认方法(default method)定义Bean的支持
wiselyman
spring 4
2.1 默认方法(default method)
java8引入了一个default medthod;
用来扩展已有的接口,在对已有接口的使用不产生任何影响的情况下,添加扩展
使用default关键字
Spring 4.2支持加载在默认方法里声明的bean
2.2
将要被声明成bean的类
public class DemoService {