深度学习论文笔记-Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
转载于:http://blog.csdn.net/chenriwei2/article/details/38047119
****************************************************************************
文章:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
来源:Technicalreport
大意:通过图像金字塔来实现识别中的尺度无关性;
作者:KaimingHe,Xiangyu Zhang, Shaoqing Ren, Jian Sun ,来自微软
主要内容:
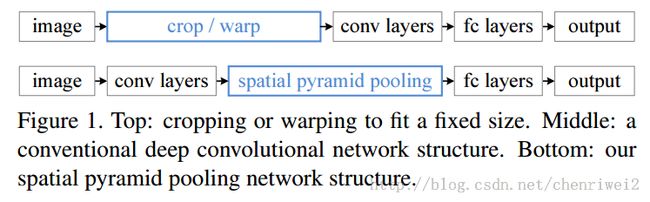
由于之前的大部分CNN模型的输入图像都是固定大小的(大小,长宽比),比如NIPS2012的大小为224X224,而不同大小的输入图像需要通过crop或者warp来生成一个固定大小的图像输入到网络中。这样子就存在问题,1.尺度的选择具有主观性,对于不同的目标,其最适合的尺寸大小可能不一样,2.对于不同的尺寸大小的图像和长宽比的图像,强制变换到固定的大小会损失信息;3.crop的图像可能不包含完整的图像,warp的图像可能导致几何形变。所以说固定输入到网络的图像的大小可能会影响到他们的识别特别是检测的准确率;
而这篇文章中,提出了利用空间金字塔池化(spatial pyramid pooling,SPP)来实现对图像大小和不同长宽比的处理,这样产生的新的网络,叫做SPP-Net,可以不论图像的大小产生相同大小长度的表示特征;这样的网络用在分类和检测上面都刷新的记录;并且速度比较快,快30-170倍,因为之前的检测方法都是采用:1.滑动窗口(慢) 2.对可能的几个目标(显著性目标窗口,可能有几千个)的每一个都进行识别然后再选出最大值作为检测到的目标;
利用这种网络,我们只需要计算完整图像的特征图(feature maps)一次,然后池化子窗口的特征,这样就产生了固定长度的表示,它可以用来训练检测器;
为什么CNN需要固定输入图像的大小,卷积部分不需要固定图像的大小(它的输出大小是跟输入图像的大小相关的),有固定输入图像大小需求的是全连接部分,由它们的定义我们可以知道,全连接部分的参数的个数是需要固定的。综上我们知道,固定大小这个限制只是发生在了网络的深层(高层)处。
文章利用了空间金字塔池化(spatial pyramidpooling(SPP))层来去除网络固定大小的限制,也就是说,将SPP层接到最后一个卷积层后面,SPP层池化特征并且产生固定大小的输出,它的输出然后再送到第一个全连接层。也就是说在卷积层和全连接层之前,我们导入了一个新的层,它可以接受不同大小的输入但是产生相同大小的输出;这样就可以避免在网络的输入口处就要求它们大小相同,也就实现了文章所说的可以接受任意输入尺度;
文章说这种形式更符合我们的大脑,我们的大脑总不会是说先对输入我们视觉的图像进行切割或者归一化同一尺寸再进行识别,而是采用先输入任意大小的图像,然后再后期进行处理。
SSP或者说是空间金字塔匹配(spatial pyramid matching or SPM)是BoW的一个扩展,它把一张图片划分为从不同的分辨率级别然后聚合这些不同分辨率的图像,在深度学习之前SPM取得了很大的成功,然是在深度学习CNN出现之后却很少被用到,SSP有一些很好的特征:1.它可以不论输入数据的大小而产生相同大小的输出,而卷积就不行 2.SPP使用多级别的空间块,也就是说它可以保留了很大一部分的分辨率无关性;3.SPP可以池化从不同尺度图像提取的特征。
对比于R-CNN,R-CNN更耗时,因为它是通过对图像的不同区域(几千个,通过显著性)提取特征表示,而在这篇文章中,只需要运行卷积层一次(整幅图像,无论大小),然后利用SPP层来提取特征,它提取的特征长度是相同的,所以说它减少了卷积的次数,所以比R-CNN快了几十倍到一百多倍的速度;
池化层(Poolinglayer)在滑动窗口的角度下,也可以看作为卷积层,卷积层的输出称之为featuremap,它表示了响应的强度和位置信息;
在利用SPP层替换最后一个卷积层后面的池化层中,
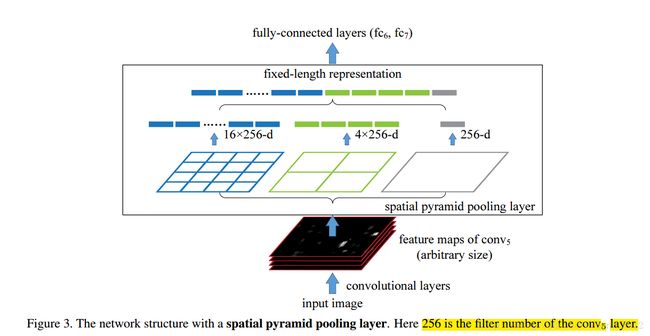
在每一个空间块(bin)中,池化每一个滤波器的响应,所以SPP层的输出为256M维度,其中256是滤波器的个数,M是bin的个数(?)(很显然,M是根据不同的图像大小计算出来的),这样不同输入图像大小的输出就可以相同了。
对于给定的输入图像大小,我们可以先计算出它所需要的空间bin块的多少,计算如下:
比如一张224*224的图像,它输入到conv5的输出为a*a(13*13),当需要n*n级别的金字塔时候,每个采样窗口为win=[a/n] (ceil操作), 步长为[a/n] (floor操作),当需要l个金字塔的时候,计算出l个这样的采样窗口和步长,然后将这些l个输出的bin连接起来作为第一个全连接层的输出;