干货 | MSCOCO 2015 Detection 前三名
转载于 程序媛的日常
---------------------------------
今天分享一下 MS COCO 2015 Detection 比赛中获得前三名的工作。本期内容要特别感谢 WDQ 同学。他参加了 ICCV 2015,并向我推荐和分享了许多许多资料。
3
就像比赛颁奖一样,我们今天先从第三名说起。第三名的工作叫《Inside-Outside Net: Detecting Objects in Context with Skip Pooling and Recurrent Neural Networks》。
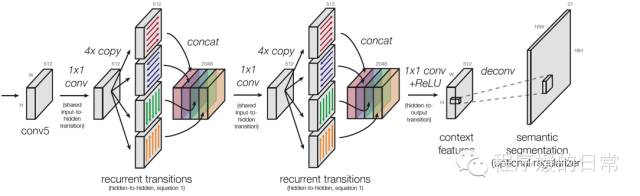
这篇文章获得了 MS COCO 2015 Detection 的 Best Student Entry 和 3rd place in total。整个工作主要拆分成两个重点,一个是 Inside 的 image representation,一个是 Outside 的 context representation。这个工作认为,理解一副图片,inside 的 image/object information 和 outside 的 global contextual information 同样重要,都不可以丢失。所以它们提出了同时去 utilize 这两方面的信息——构造了 Inside-Outside Net(ION)。其中,inside 部分它们的思想依然是 multi-scale representation,用 conv3, conv4, conv5 等层级 stacked 抽取 features,因为这样对于 small objects 就不会丢失 lower-level layer 的 high resolution information。另一方面,它们在 outside 部分的工作则更 special 一点。它们使用的是 multi-dimensional IRNN,其中 multi-dimensional 的意思是,我们常见的 RNN 最多就是 bi-directional,双向的;但是在一幅平面图里,我们有横纵两个大方向,则一共有4个小方向;而 IRNN 则是用 identity matrix 进行初始化的基于 ReLU activation 的 RNN 的别称。
 在实验结果中,它们分别用对照实验来分别验证了,why this inside/outside representation architecture matters。在 Inside 部分,它们发现,conv3, conv4, conv5 这几个网络是必须的,相反,conv2 就比较没必要。在 Outside 部分,它们对比了其他的一些 contextual representation 方法,比如我们熟悉的 global averaging or additional convolution 等等,发现确实还是它们这种 4-dir IRNN 要好。但是,这种 4-dir IRNN 也并不是那么 amazing,因为它们发现,如果它们把 4-dir IRNN 中的 weight matrix 全用 identity matrix 替代,也就是把 hidden to hidden matrix (H2H) 去掉,效果竟然几乎没有任何下降。也就是说,即使可以认为加入 context information 一定是有用的,但是更好的 contextual information representation/network architecture 应该是什么样的,却还是有待探索的。
在实验结果中,它们分别用对照实验来分别验证了,why this inside/outside representation architecture matters。在 Inside 部分,它们发现,conv3, conv4, conv5 这几个网络是必须的,相反,conv2 就比较没必要。在 Outside 部分,它们对比了其他的一些 contextual representation 方法,比如我们熟悉的 global averaging or additional convolution 等等,发现确实还是它们这种 4-dir IRNN 要好。但是,这种 4-dir IRNN 也并不是那么 amazing,因为它们发现,如果它们把 4-dir IRNN 中的 weight matrix 全用 identity matrix 替代,也就是把 hidden to hidden matrix (H2H) 去掉,效果竟然几乎没有任何下降。也就是说,即使可以认为加入 context information 一定是有用的,但是更好的 contextual information representation/network architecture 应该是什么样的,却还是有待探索的。

虽然这篇工作中,无论是 multi-scale for inside 还是 contextual information for outside,都不是新的。但是因为这个网络的连接方式比较复杂,如何将这两类信息成功放在一起学习,是这篇工作的贡献之处。其中,Skip-Connections + L2-normalization for input-to-hidden transition 还有 multi-dimensional RNN for outside context 都是很重要的。
2
然后让我们来到第二名。第二名来自 Facebook AI Team,提交的 model 叫做 FAIRCNN,但是并没有相关的论文。FAIRCNN 主要基于两个以前的工作进行了改进,分别是 DeepMask segmentation proposals 和 Fast R-CNN object dectector。
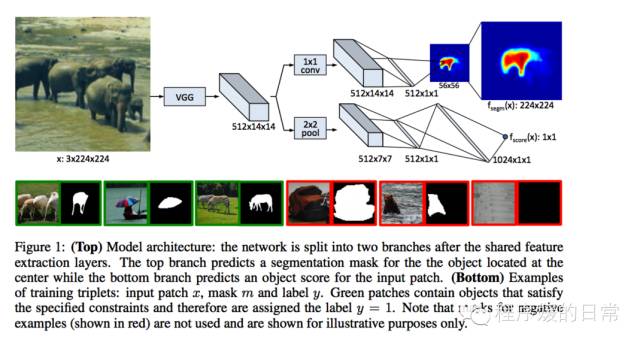
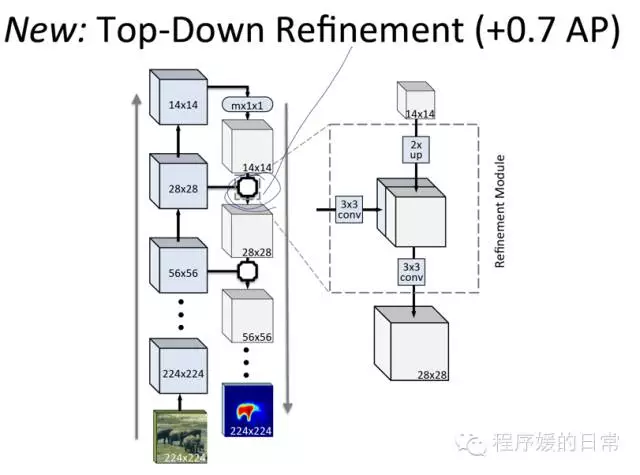
前者,DeepMask 来自 NIPS 2015 的工作《Learning to Segment Object Candidates》,它将 segmentation 分为 segment candidates 和给 candidate 打分两个步骤。原始的 DeepMask 是 single scale 的。在 FAIRCNN 这个工作中它们加入了 iterative localization 和 top-down refinement 去进一步提高 segmentation 的精准度。
与此同时,它们还把 single scale 变成了 multi scale,但是是在 classification 阶段,也就是 FAIRCNN 的第二部分,基于 Fast R-CNN 的改进。那么 Fast R-CNN 这个框架又是什么样呢?

在 object detection 的工作中,主要解决和面临的困难是:object detection 比 image classification 难在:(1)有非常多 candidate object locations(也叫 proposal),太难一一检索;(2)即使是检索到一些 location,也会比较模糊,对第二步 detection 的工作很有影响。从上面这个叙述可以可能出,以前的 object detection 工作是 pipeline 的,先找 proposal,再 detect。pipeline 的工作一个是慢,一个是 error propagation 问题严重,最终任务效果很受底层任 subtask 的表现影响。Fast R-CNN 就是在 pipeline 这件事上,有了突破,就是我又做 classification,又做 detection——不再 pipeline,而是同时输出两个结果,也就是 joint training 了。

那么是如何实现的呢,先 selective search 得到大概 2K 个 proposal(也叫 RoI,region of interests),然后用 invariant scale 得到图片金字塔,最后在全连接得到特征时,用 hierarchical sampling 的方式,共享特征(reduce computation)给两个新的全连接,最后是两个 sibling 的优化目标。第一个优化目标是分类,使用softmax,第二个优化目标是bbox regression。对比以前 MSRA Kaiming He 的 SPP-Net 工作,其实可以认为是一个 joint training 版本的 SPP-Net,把 classifier 也一起搞进来(不用再单独训练一个 SVM)。
说完了 Fast R-CNN,回到这个第二名的工作。基于 Fast R-CNN,它们从 ICCV 2015 的另一篇工作《Object detection via a multi-region & semantic segmentation-aware CNN model》得到启发,提出了 multi-scale + multi-region 结合的结构。在原始的《multi-region & semantic segmentation-aware》工作中,本来仅仅是一种 adaptive multi-region 的:
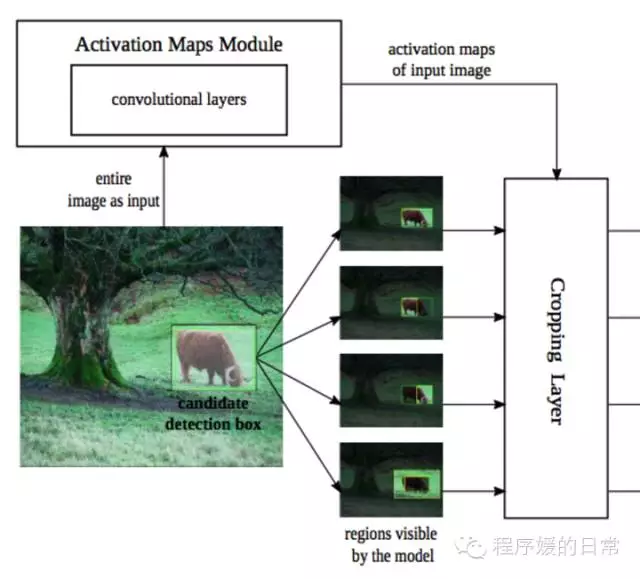
FAIRCNN 则把 region “替换”成了不同 scale 的图片:

最后,再结合上 skip connection,multi-head classifier(其实就是一种改造过的 loss function),成功摘得 MS COCO 2015 Detection 的亚军。它们这些改造其实并不能说多么新,而且都已经被“预言”过噢——就是在《Learning to Segment Object Candidates》讨论 localization 的时候,已经提出,multi-scale 和 skip connection 会对效果有帮助。
最后,当然是隆重地介绍(已经介绍过)成功摘取 ILSVRC2015 全(主要)类别第一名的工作,来自 MSRA 的 ResNet,Deep Residual Network:开创了152层 deep network。虽然 residual network 的名字很新,但其实可以把它看成是我已经介绍和推荐过无数次的 Highway Networks 的特例(Highway Networks 的介绍见下)。尽管如此,作者在解释 residual 的 motivation 时还是非常充分合理,让人不得不佩服其在背后自己的思考。

作者提出 residual network 的 motivation 其实依然是 information flow 在 deep network 中受阻。大家都可以想象到这个问题。但是这篇工作中,作者是如何“验证”这个问题的呢?他们用了两种“角度”,第一种是在 Introduction 里就提到的:当他们用 deep network 和可类比的 shallower network 横向对比(如上图),发现 deep network 的 training error 总是比 shallower network 要高。可是这在理论上是不对的。因为如果一个 shallow network 可以被训练优化求解到某一个很好的解(subspace of that of deep network),那么它对应的 deep 版本的 network 至少也可以,而不是更差。但事实并不是如此。这种 deep network 反而优化变差的事情,被作者称为“degration problem”。第二种角度是在实验部分提到的,从理论角度分析这种 degration 不应该是 gradient vanishing 那种问题,而是一种真正的优化困难。于是,为了解决这个 degration problem,作者提出了 residual network,意思是说,如果我们直接去逼近一个 desired underlying mapping (function) 不好逼近(优化困难,information flow 搞不定),我们去让一个 x 和 mapping 之间的 residual 逼近 0 应该相对容易。这就是作者给 highway networks 找的 residual 的解释。
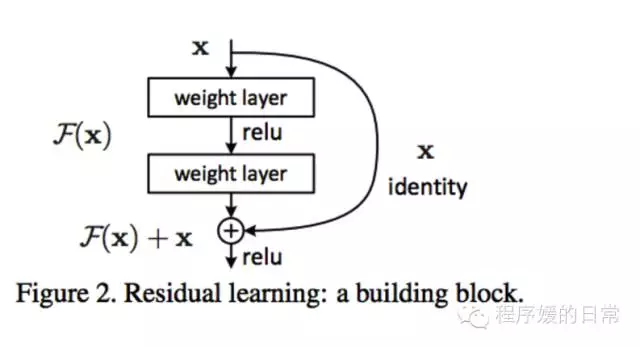
那么,在实际上,residual network block(上图)就相当于是 Highway network block 中 transform gate 和 transform function 被特例后的结果——因为是特例了,也自然 reduce 了 parameter,也算是这篇工作中作者一个卖点。
以上就是今天的全部内容。虽然工作和论文层出不穷,但是很多“法宝”都是百试不爽的:比如 multi-scale,比如 inside information (local) + contextual information (global),比如 multi-task。