KMP模式匹配
在开发中经常遇到需要查看一个字符串t是否在字符串s中存在,并找到其第一次出现的位置,也就是在字符串s中查找子串t,我们平常都是怎么实现那?我们最起码有三个方法可以用,CString和string中的find函数,以及string.h中的strstr函数,用起来既简单又快捷,CString是MFC中的东西,string是C++标准库的东西,strstr是C中string.h中的东西,貌似我们没必要非要自己实现定位查找功能……但是如果我偏要想自己实现那?我们能不能模仿MFC中的CString或者C++中的string和string.h中的strstr来自己实现一个函数那?下面我们慢慢来找一找,看看能不能实现。
1. 朴素模式匹配
假如s=”ababcababcac”,t=”abcac”,在s中查找t;我们可以最直接想到的办法就是直接拿t中每一个字符和s中的每一个字符一一进行比较,如下:
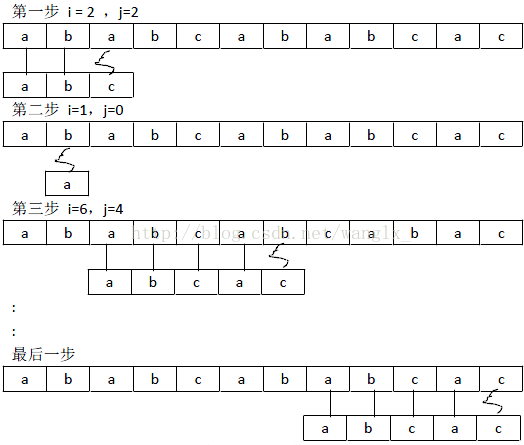
从比较过程中我们可以发现每次比较失败后,i和j都会回溯;不停得回溯不停得比较,时间复杂度、为O(mn);算法十分简单,也很容易实现,代码如下:
int BFMatcher(const char* strMain,const char* strSub)
{
int n = strlen(strMain);
int m = strlen(strSub);
int j = 0;
int i=0;
while ( i<n )
{
while( j<m && strSub[j] == strMain[i] )
{
if ( j == m-1 )
return i-j;
j++;
i++;
}
i = i-j+1;//回溯
j = 0;
}
return -1;
}
2. KMP算法
根据上面的步骤我们仔细看第一步和第二步会发现,我们在第一步中比较s中的a和t中的c失败后,第二步直接从第一步中已经比较的过的s中的b开始与t中的第一位a比较,我们通过第一步已经知道s中的第二个是b,不可能与t中的第一位a相等,这一步比较完全是多余的,咱们实现的上面的简单方法完全没有利用第一次比较过得结果,这叫什么,叫没吸取经验,在第二步比较时我们应该利用第一步的比较结果,如果我们利用了比较结果,完全就可以跳过第二步,明显的节省了时间,第一步和第二步的比较应该为下面这样:
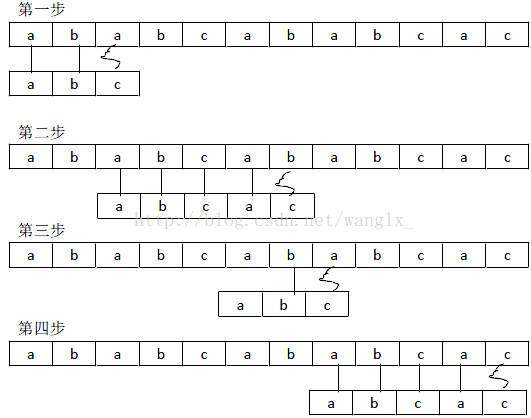
按照这个方法来的话,我们这个比较四步也就成功找到t在s中的位置,避免了i和j的重复回溯,比上面的方法不知道快了多少倍。可是这个例子看起来简单,可是怎么编程实现那?怎么让它一般化那?我们先来看第二步是如何到达第三步的:
第二步比较开始时i为s中第三个字符a的位置,即i=2;t中j=0;当比较到i=7,j=4时不相等了,比较失败,在第三步时我们发现s中起始比较的位置仍然为i=7不变,t中j的位置变成了1,在第二步中我们发现,”abca”成功在s中找到了位置,我们比较s[6]与t发现,s[6]=t[3],同时s[6]=t[0];所以在第三步中s[6]和t[0]就无需进行比较,我们通过观察”abca”和t[0]t[3]可以发现,t[0]和t[3]分别是”abca”的真前缀和真后缀,t[0]=t[3],那么是不是说我们只要找到已经在s匹配成功的t中的串t[0…q]中的相等的真前缀和真后缀的长度,我们就可以知道,下次比较t中j的起始位置那?比如刚刚在第二步中得到的”abca”的真前缀的长度为1,那么下次比较j的位置就为1。由此可知,比较失败后,s中的i不用动,只需要获取下一个j就行,并且这个j的只与s没有关系。
那么我们来总结下,假设s串长度为n,t串长度为m,m<=n,在s中查找t,t[1…q] =s[i+1…i+q] 0<q<m(注:在上面的例子中第二步中,i=2,q=4,这里的t[1…q]表示的是从t[0]到t[q-1]的元素),且t[1…q+1]!= s[i+1…i+q+1];并且有t[1…k]=s[i`+1…i`+k]1<k<q i+1 <i`<i+q,其中i`=i+q-k;那么我们后面的匹配测试中就会变得十分的简单。由此可知我们主要求出这个k值就可以了,也就是求出t[1…q]中的最大真前缀的长度就行,这个长度的值就是下一个j的值。
下面的问题就是获取失败后的下一个j,也就是怎么找t[1…q]中的最大真前缀。
可以看到1<q<m,所以我们需要获取t[1…1]到t[1…m]中所有串的最大的真前缀,所以可以直接把这些最大真前缀的长度提前求出放到一个数组next[]中,以供使用。
有了这个next数组之后就可以写出查找函数如下:
int KMP_Matcher(const char* strMain,const char* strSub)
{
if ( NULL == strMain || NULL == strSub )
return -1;
int n = strlen(strMain);
int m = strlen(strSub);
int next[MAX_STRING_LEN] = {0};
GetNext(strSub,next);
int q = 0;
for ( int i=0 ; i<n ; i++ )
{
while ( q>0 && strSub[q]!=strMain[i] )
q = next[q];
if ( strSub[q] == strMain[i] )
q = q+1;
if ( q==m-1 )
return i-q+1;
}
return -1;
}
现在我们就只需要想办法怎么实现这个GetNext函数填充next数组:
我们可以知道next[1]=0,因为t[1…1]没有真前缀,由此可以考虑用递归的方式来实现对next数组的求解。对于q>1,假设已知next[1],next[2],next[3],next[4]……next[q-1]中所有串的最大真前缀的长度,那么next[q]那?设next[q-1]=k,那么t[1…k]是t[1…q-1]中的最大真前缀,因此我们对t[q]假设两种情况:
1. t[k+1]=t[q],那么这就简单了,这样说明串t[1…k]的后一位与t[1…q-1]的后一位是相等的,已知next[q-1]=k,那么next[q]=k+1。
2. t[k+1]!=t[q],那么就找t[1…q-1]的第二大真前缀,因为t[1…k]是t[1…q-1]的最大真前缀,所以t[1…k]的最大真前缀就是t[1…q-1]的第二大真前缀,所以此时不相等就是求t[1…k]的最大真前缀,即next[ next[q-1] ] = next[k];这是就变成了k=next[k],比较t[next[k]+1]和t[q],若还不相等,则重复此步骤,直到next[k]=0;j的值回溯到0从头开始匹配。
通过上面两步便可求出next数组。代码实现如下:
void GetNext(const char* str,int* next)//abcac
{
next[0] = 0;
int m = strlen(str);
int k = -1;
for ( int q=1 ; q<m ; q++ )
{
while( k>0 && str[k+1] != str[q] )
k = next[k];
if( str[k+1] == str[q] )
next[q] = ++k;
else
next[q] = 0;
}
}通过上面代码我们可以发现,可以通过对k的初始值调整,得到更加简短的实现,如下:
void GetNext(const char* str,int* next)
{
next[0] = 0;
int m = strlen(str);
int k = 0;
for ( int q= 1; q<m ; q++ )
{
while( k>0 && str[k] != str[q] )
k = next[k];
if ( str[k] == str[q] )
k = k+1;
next[q] = k;
}
}
3. KMP时间复杂度计算
要计算KMP_Matcher的时间复杂度,首先要计算GetNext的时间复杂度,由代码可知,GetNext中的for循环的时间复杂度为m,而for中的while循环那??可以看到,while循环受k>0限制,k由大于next[k],也就是说while循环中的操作是以至少1的速度减小k的值,而k的值又是受for中k=k+1限制,k值为零while循环不会做任何操作,所以while循环受for循环约束,while循环内减小k值后,若k值不增加,while循环就不会做任何操作,所以GetNext的时间复杂度为O(m),同可以推出KMP_Matcher的时间复杂度为O(m+n)。
最终完整的代码如下:
#include <stdio.h>
#include <string.h>
#define MAX_STRING_LEN 255
void GetNext(const char* str,int* next)
{
next[0] = 0;
int m = strlen(str);
int k = 0;
for ( int q= 1; q<m ; q++ )
{
while( k>0 && str[k] != str[q] )
k = next[k];
if ( str[k] == str[q] )
k = k+1;
next[q] = k;
}
}
int KMP_Matcher(const char* strMain,const char* strSub)
{
if ( NULL == strMain || NULL == strSub )
return -1;
int n = strlen(strMain);
int m = strlen(strSub);
int next[MAX_STRING_LEN] = {0};
GetNext(strSub,next);
int q = 0;
for ( int i=0 ; i<n ; i++ )
{
while ( q>0 && strSub[q]!=strMain[i] )
q = next[q];
if ( strSub[q] == strMain[i] )
q = q+1;
if ( q==m-1 )
return i-q+1;
}
return -1;
}
int main(int argc, char* argv[])
{
int nIndex = KMP_Matcher("aaababcacabcac","abcacab");
printf("nIndex=%d",nIndex);
getchar();
return 0;
}
参考:《算法与数据结构》 傅清祥、王晓东