中科院分词系统整理笔记
NLPIR简介
一套专门针对原始文本集进行处理和加工的软件,提供了中间件处理效果的可视化展示,也可以作为小规模数据的处理加工工具。可以使用该软件对自己的数据进行处理。
NLPIR分词系统前身为2000年发布的ICTCLAS词法分析系统,从2009年开始,为了和以前工作进行大的区隔,并推广NLPIR自然语言处理与信息检索共享平台,调整命名为NLPIR分词系统,增加了十一项功能。
NLPIR 系统支持多种编码(GBK 编码、UTF8 编码、BIG5 编码)、多种操作系统(Windows, Linux, FreeBSD 等所有主流操作系统)、多种开发语言与平台(包括:C/C++/C#,Java,Python,Hadoop 等)。
新增功能
全文精准检索-JZSearch:支持多数据类型、多字段、多语言;
新词发现:挖掘新词列表
分词标注:对原始语料进行分词、自动识别人名地名机构名等未登录词、新词标注以及词性标注。并可在分析过程中,导入用户定义的词典。
统计分析与术语翻译:一元词频统计、二元词语转移概率统计,并且可以针对常用的术语,会自动给出相应的英文解释。
大数据聚类及热点分析-Cluster:自动分析出热点事件,并提供事件话题的关键特征描述。
大数据分类过滤:从海量文档中筛选出符合需求的样本。
自动摘要-Summary:能够对单篇或多篇文章,自动提炼出内容的精华,方便用户快速浏览文本内容。
关键词提取-KeyExtract:能够对单篇文章或文章集合,提取出若干个代表文章中心思想的词汇或短语,可用于精化阅读、语义查询和快速匹配等
文档去重-RedupRemover:能够快速准确地判断文件集合或数据库中是否存在相同或相似内容的记录,同时找出所有的重复记录。
HTML正文提取-HTMLPaser:自动剔除导航性质的网页,剔除网页中的HTML标签和导航、广告等干扰性文字,返回有价值的正文内容。适用于大规模互联网信息的预处理和分析。
编码自动识别与转换:自动识别文档内容的编码,并进行自动转换,目前支持Unicode/BIG5/UTF-8等编码自动转换为简体的GBK,同时将繁体BIG5和繁体GBK进行繁简转化。
相关技术
1.网络信息实时采集与正文提取
NLPIR大数据搜索与挖掘演示平台根据新浪rss摘要,利用NLPIR的精准网络采集系统实时抓取新浪最新的新闻(每次刷新均会重新抓取),NLPIR正文提取系统将网页中的导航、广告等内容去除,利用网络文本链接密度作为主要参数,采用深度神经网络模型,实现文本正文内容的自动提取。这里,也可由用户人工随意输入任意的文章。
2.基于层叠隐马模型的分词标注
NLPIR/ICTCLAS分词系统,采用层叠隐马模型(算法细节请参照:张华平,高凯,黄河燕,赵燕平,《大数据搜索与挖掘》科学出版社。2014.5 ISBN:978-7-03-040318-6),分词准确率接近98.23%,具备准确率高、速度快、可适应性强等优势。它能够真正理解中文,利用机器学习解决歧义切分与词性标注歧义问题。张博士先后倾力打造十余年,内核升级10次,全球用户突破30万。
3.基于角色标注的实体抽取
NLPIR实体抽取系统能够智能识别文本中出现的人名、地名、机构名、媒体、作者、及文章的主题关键词,所提炼出的词语不需要在词典库中事先存在,是对语言规律的深入理解和预测。NLPIR实体抽取系统采用基于角色标注算法自动识别命名实体(算法细节请参照:张华平,高凯,黄河燕,赵燕平《大数据搜索与挖掘》科学出版社2014.5ISBN:978-7-03-040318-6),可在此基础上搭建各种多样化的大数据挖掘应用。
4.基于完美双数组TRIE树的词频统计
NLPIR的词频统计算法的效率较高,采用了我们的完美双数组TRIE树的专利算法(近期有进一步的优化),是常规算法速度的十倍以上,该算法的效率不会随着待统计结果数目的剧增而指数级增长,一般是亚线性增长。建议大家调用NLPIR/ICTCLAS开放的词频统计接口。
5。基于深度机器学习的文本分类
NLPIR采用了深度神经网络对分类体系进行了综合训练,目前训练的类别只是厂家的政治、经济、军事等。我们内置的算法支持类别自定义训练,该算法对常规文本的分类准确率较高,综合开放测试的F值接近86%。NLPIR深度文本分类,可以用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等诸多应用。此外还可以实现文本过滤,能够从大量文本中快速识别和过滤出符合特殊要求的信息,可应用于品牌报道监测、垃圾信息屏蔽、敏感信息审查等领域。
6。基于深度神经网络的文本情感分析
NLPIR情感分析提供两种模式:全文的情感判别(左图)与指定对象的情感判别(右图)。情感分析主要采用了两种技术:1.情感词的自动识别与权重自动计算,利用共现关系,采用Bootstrapping的策略,反复迭代,生成新的情感词及权重;2.情感判别的深度神经网络:基于深度神经网络对情感词进行扩展计算,综合为最终的结果。
7。基于上下文条件熵的关键词提取
NLPIR关键词提取能够在全面把握文章的中心思想的基础上,提取出若干个代表文章语义内容的词汇或短语,相关结果可用于精化阅读、语义查询和快速匹配等。NLPIR主要采用交叉信息熵计算每个候选词的上下文条件熵,所处理的文档不受行业领域限制,且能够识别出最新出现的新词语,所输出的词语可以配以权重。
8.基于POS-CBOW的word2vec语义扩展
POS-CBOW方法综合了词性、词的分布特点,采用word2vector改进模型,对5GB的新闻语料进行训练,自动提取出了语义关联关系。如果训练文本调整为专业领域的生语料,该模型同样可以产生专业领域的本体关联关系。
9.基于全局结构预测模型的转移依存句法分析
NLPIR提出使用Yamada算法的结构化转移依存句法分析模型,在Yamada算法的基础上,加入全局的训练以及预测,优化了特征集合。该模型的精度(85.5%)接近于目前转移依存句法最好结果(86.0%),并且在所有精度85%以上的依存句法模型中,达到了最快的分析速度。
10.简繁转化
NLPIR根据中文简繁词库,对照抽取互译。
11.基于隐马模型的自动注音
NLPIR可根据词库,基于语意理解,对字词自动进行语音标注。准确率99%
12.基于关键词提取的自动摘要
自动文本摘要中间件能够实现文本内容的精简提炼,从长篇文章中自动提取关键句和关键段落,构成摘要内容,方便用户快速浏览文本内容,提高工作效率。
自动摘要中间件不仅可以针对一篇文档生成连贯流程的摘要,还能够将具有相同主题的多篇文档去除冗余、并生成一篇简明扼要的摘要;用户可以自由设定摘要的长度、百分比等参数;处理速度达到每秒钟20篇。
下载地址
NLPIR的下载地址:http://ictclas.nlpir.org/downloads
GitHub的地址:https://github.com/NLPIR-team/NLPIR
导入工程
官网版:
(1)新建一个工程导入sample下java工程目录JnaTest_NLPIR,导入后的情形如下:
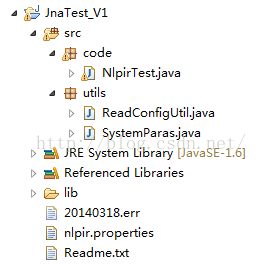
(2)code目录下的NlpirTest.java文件就可以测试。
有两个地方需要配置参数值:
第一:加载库文件

第二:初始化时需要的参数

“XXXX”为解压后的包路径。
Github上下载的代码:
(1)找到NLPIR SDK目录的NLPIR-ICTCLAS导入工程,结果如下:
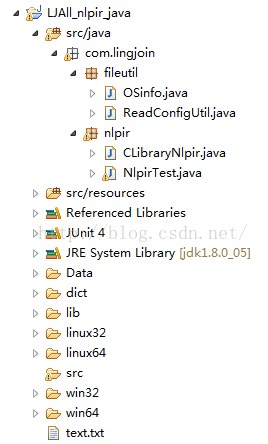
(2)使用nlpir下的NlpirTest.java进行测试。
注意:这个文件是单元测试,只需要在要测试的方法上右击,选择“JUint Test”即可;
可能会有license问题,将License文件夹下的所有.user文件抽出来放到Dada目录下即可。
至此,两种方式都可以跑起来了。