【机器学习】KNN(K-Nearest Neighbor)
KNN简介
KNN算法又称为K最近邻分类(K-nearest neighbor classification)算法,是一种非常简单的机器学习分类算法。
KNN算法的原理十分简单:对于待分类的样本,计算其到所有训练样本的距离,从中选取K个距离最近的训练样本,统计这K个距离最近的训练样本所属的类别,按照少数服从多数的原理,将待分类的样本归入k个训练样本所属数目最多的类别。更加通俗地说,就是看待分类样本的K个最相似(即距离最近)的训练样本中属于哪个类别的样本最多,则该待分类的样本就属于哪一个类别。
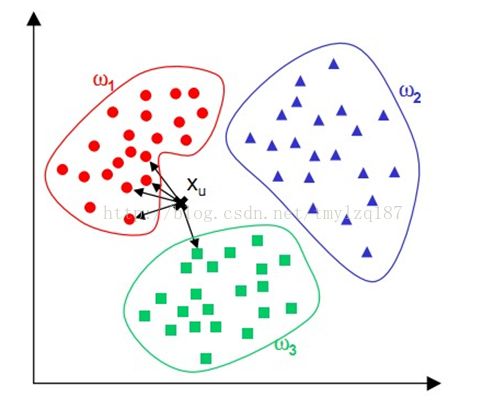
通过上面这张图片便可以清楚地理解KNN算法是干什么的了:假设有三个不同的类别ω1、ω2、ω3,每个类别中都已经有若干已经训练好的样本,当一个新样本Xu到来,则计算Xu与每个类别中每个训练样本的距离,然后取出其中k个(图中k=5)距离最近的训练样本,在这k个距离最近的样本中,有4个属于ω1,1个属于ω3,则Xu应该归入ω1类中。
KNN算法涉及三个主要的因素:训练集、距离或相似的衡量、k的大小。距离或相似的衡量可以采用欧几里得距离、曼哈坦距离或明考斯基距离。这几种距离的计算公式如下:
(1)欧几里得距离
欧几里得距离又称为欧氏距离,由对应元素间的差值平方和的平方根来表示。设有a、b两个n维向量Xa(Xa1,Xa2,…,Xan)和Xb(Xb1,Xb2,…,Xbn),则有:
![]()
(2)曼哈坦距离
曼哈坦距离用对应元素间差值绝对值的和来表示,即:
![]()
(3)明考斯基距离
明考斯基距离是欧几里得距离和曼哈坦距离的概化:
![]()
其中p是一个正整数。当p=1时,它表示曼哈坦距离;当p=2时,它表示欧几里得距离。
(4)加权的明考斯基距离
如果对每一个变量根据其重要性赋予一个权重,就得到加权的明考斯基距离:
![]()
KNN算法原理简单,实现比较容易,但也有比较显著的缺点。当训练样本容量不平衡时,例如一个类别的训练样本容量很大,其他类的训练样本容量很小时,就有可能导致输入一个新样本时,该样本的k个最近邻居中大容量类的训练样本居多,可能产生较大误差。除此之外,KNN算法的计算量过大,每次输入新样本时,都需要计算这个待分类样本到全体已知样本的距离,才能得到它的k个最近邻点。
KNN的实现
KNN算法步骤如下:
(1)初始化k个最近邻距离为最大值。
(2)计算未知样本和每个训练样本的距离dist。
(3)得到目前k个最邻近样本中的最大距离maxdist。
(4)如果未知样本与该训练样本的距离dist小于目前k个最邻近样本中的最大距离maxdist,则将该训练样本作为k最近邻样本替换掉原来k个最近邻样本中距离最大的样本。
(5)重复步骤(2)、(3)、(4),直到计算完未知样本与所有训练样本的距离,最终得到k个最近邻样本。
(6)统计k个最近邻样本中每个类标号出现的次数。
(7)选择出现频率最大的类标号作为未知样本的类标号。
代码清单
“编程中最没有用的是源代码,最有用的是算法和数据结构”,所以下面仅粘贴出部分实现KNN基本功能的C++代码,测试部分代码省略。
#include<stdio.h>
#include<stdlib.h>
#include<memory.h>
#include<string.h>
#include<math.h>
#include<iostream>
#include<fstream>
using namespace std;
#define ATTR_NUM 4 //属性的数目
#define MAX_SIZE_OF_TRAINING_SET 1000 //训练集的大小
#define MAX_SIZE_OF_TEST_SET 100 //测试集的大小
#define MAX_VALUE 10000.0 //属性的最大值
#define k 7 //选择近邻的个数
typedef struct dataVector
{
int ID; //ID号
char classLabel[15]; //分类标号
double attributes[ATTR_NUM]; //属性
}dataVector;
typedef struct distanceStruct
{
int ID; //ID号
double distance; //距离
char classLabel[15]; //分类标号
}distanceStruct;
dataVector gTrainingSet[MAX_SIZE_OF_TRAINING_SET]; //训练数据集
dataVector gTestSet[MAX_SIZE_OF_TEST_SET]; //测试数据集
distanceStruct gNearestDistance[k]; //k个最近邻距离
/************求vector1=(x1,x2,...,xn)和vector2(y1,y2,...,yn)的欧几里得距离************/
double Distance(dataVector vector1,dataVector vector2)//可以看做是求ATTR_NUM维的欧几里得距离
{
double dist,sum=0.0;
for(int i=0;i<ATTR_NUM;i++)
sum+=(vector1.attributes[i]-vector2.attributes[i])*(vector1.attributes[i]-vector2.attributes[i]);
dist=sqrt(sum);
return dist;
}
/*************得到gNearestDistance中的最大距离,返回下标***************/
int GetMaxDistance()
{
int maxNo=0;
for(int i=1;i<k;i++)
{
if(gNearestDistance[i].distance>gNearestDistance[maxNo].distance)
maxNo=i;
}
return maxNo;
}
/**************对未知样本sample进行分类*******************/
char* Classify(dataVector sample)
{
double dist=0;
int maxID=0,freq[k],tmpfreq=1;
char* curClassLabel=gNearestDistance[0].classLabel;
memset(freq,1,sizeof(freq));
//step1:初始化k个最近邻距离为最大值
for(int i=0;i<k;i++)
gNearestDistance[i].distance=MAX_VALUE;
//step2:计算k最近邻距离
for(int i=0;i<curTrainingSetSize;i++)
{
//step2.1:计算未知样本和每个训练样本的距离
dist=Distance(gTrainingSet[i],sample);
//step2.2:得到gNearstDistance中的最大距离
maxID=GetMaxDistance();
//step2.3:如果距离小于当前gNearestDistance中的最大距离,则将该样本作为K最近邻样本,替换掉之前的最大距离样本
if(dist<gNearestDistance[maxID].distance)
{
gNearestDistance[maxID].ID=gTrainingSet[i].ID;
gNearestDistance[maxID].distance=dist;
strcpy(gNearestDistance[maxID].classLabel,gTrainingSet[i].classLabel);
}
}//这一步结束后得到了k个最近邻样本保存在gNearestDistance[k]中
//step3:统计每个类出现的次数
for(int i=0;i<k;i++)
for(int j=0;j<k;j++)
if((i!=j)&&(strcmp(gNearestDistance[i].classLabel,gNearestDistance[j].classLabel)==0))
freq[i]++;
//step4:选择出现频率最大的类标号返回
for(int i=0;i<k;i++)
if(freq[i]>tmpfreq)
{
tmpfreq=freq[i];
curClassLabel=gNearestDistance[i].classLabel;
}
return curClassLabel;
}
int main()
{
//程序测试(略)
return 0;
}