R语言与机器学习学习笔记(分类算法)(6)logistic回归
写在前面的废话
2014,又到了新的一年,首先祝大家新年快乐,也感谢那些关注我的博客的人。
现在想想数据挖掘课程都是去年的事了,一直预告着,盘算着年内完工的分类算法也拖了一年了。
本来打算去年就完成分类算法,如果有人看的话也顺带提提关联分析,聚类神马的,
可是, 。
。
借着新年新气象的借口来补完这一系列的文章,
可是,这明明就是在发 。
。
尽管这个是预告里的最后一篇,但是我也没打算把这个分类算法就这么完结。尽管每一篇都很浅显,每个算法都是浅尝辄止的,在deep learning那么火的今天,掌握这些东西算起来屌丝得不能再屌丝了。考虑到一致性与完备性,最后补上两篇一样naive的:组合方法提高分类效率、几种分类方法的绩效讨论。希望读到的人喜欢。
算法六:logistic回归
由于我们在前面已经讨论过了神经网络的分类问题(参见《R语言与机器学习学习笔记(分类算法)(5)》),如今再从最优化的角度来讨论logistic回归就显得有些不合适了。Logistic回归问题的最优化问题可以表述为:寻找一个非线性函数sigmoid的最佳拟合参数,求解过程可使用最优化算法完成。它可以看做是用sigmoid函数作为二阈值分类器的感知器问题。
今天我们将从统计的角度来重新考虑logistic回归问题。
一、logistic回归及其MLE
当我们考虑解释变量为分类变量如考虑一个企业是否会被并购,一个企业是否会上市,你的能否考上研究生这些问题时,考虑线性概率模型P(yi =1)= β0 + β1xi 显然是不合适的,它至少有两个致命的缺陷:1、概率估计值可能超过1,使得模型失去了意义;(要解决这个问题并不麻烦,我们将预测超过1的部分记为1,低于0的部分记为0,就可以解决。这个解决办法就是计量里有一定历史的tobit模型)2、边际效应假定为不变,通常来说不合经济学常识。考虑一个边际效应递减的模型(假定真实值为蓝线),可以看到线性模型表现很差。
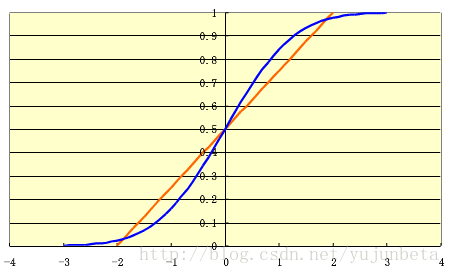
但是sigmoid函数去拟合蓝线确实十分合适的。于是我们可以考虑logistic回归模型:
![]()
假定有N个观测样本Y1,Y2,…,YN,设P(Yi=1|Xi)=π(Xi)为给定条件Xi下得到结果Yi=1的条件概率;而在同样条件下得到结果Yi=0的条件概率为P(Yi=0|Xi)=1-π(Xi),于是得到一个观测值的概率P(Yi)=π(Xi)Yi[1-π(Xi)]1-Yi假设各观测独立,对logistic回归模型来说,其对数似然函数为:
![]()
于是便可求解出logistic模型的MLE。
二、logit还是probit?
虽说sigmoid函数对边际递减的模型拟合良好,但是我们也要知道S型函数并非仅sigmoid函数一个,绝大多数的累积分布函数都是S型的。于是考虑F-1(P)(F为标准正态分布的累积分布函数)也不失为一个很好的选择。像这样的,对概率P做一点变换,让变换后的取值范围变得合理,且变换后我们能够有办法进行参数估计的,就涉及到广义线性模型理论中的连接函数。在广义线性模型中我们把log(P/(1-P))称为logit,F-1(P)(F为标准正态分布的累积分布函数)称为probit。那么这里就涉及到一个选择的问题:连接函数选logit还是probit?logistic回归认为二分类变量服从伯努利分布,应当选择logit,而且从解释的角度说,p/(1-p)就是我们常说的odds ratio,也就是软件报告中出现的OR值。
但是probit也有它合理的一面,首先,中心极限定理告诉我们,伯努利分布在样本够多的时候就是近似正态分布的;其次,从不确定性的角度考虑,probit认为我们的线性概率模型服从正态分布,这也是更为合理的。
我们来看一下经过变换后,自变量和P的关系是什么样子的:
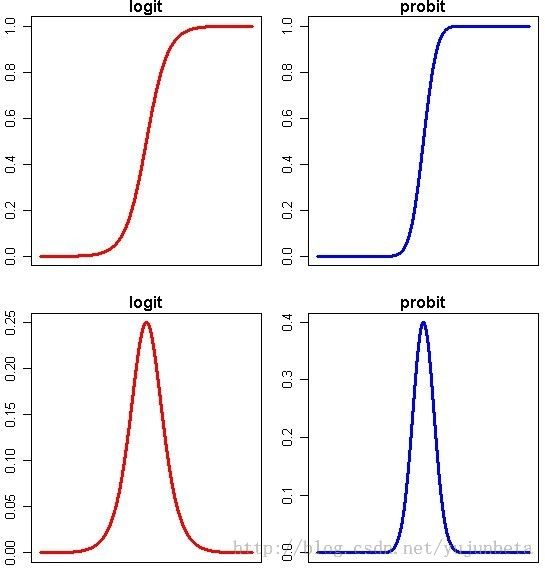
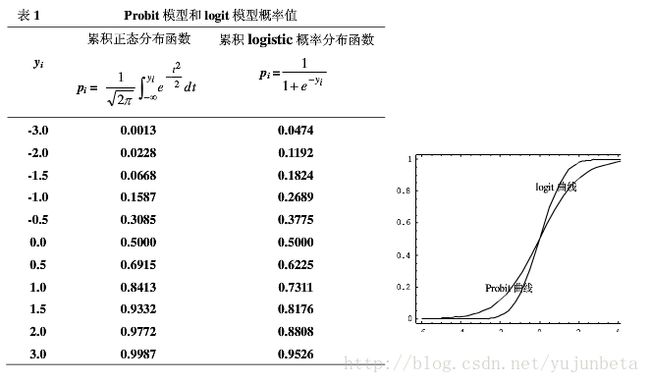
如果你确实想知道到底你的数据用哪一个方法好,也不是没有办法,你可以看一下你的残差到底是符合logit函数呢还是符合probit函数,当然,凭肉眼肯定是看不出来的,因为这两个函数本来就很接近,你可以通过函数的假定,用拟合优度检验一下。但通常,估计不会有人非要这么较真,因为没有必要。但是有一点是要注意的,logit模型较probit模型而言具有厚尾的特征,这也是为什么经济学论文爱用logit的原因。
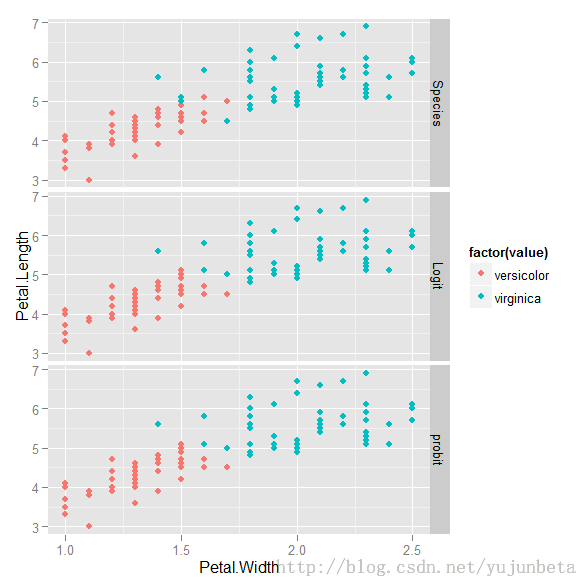
我们以鸢尾花数据中的virginica,versicolor两类数据分类为例,看看两种办法分类有无差别。
probit.predictions
versicolor virginica
versicolor 47 3
virginica 3 47
logit.predictions
versicolor virginica
versicolor 47 3
virginica 3 47
从上图与比较表格均可以看出,两者差别不大。
三、多项式logit与order logit
对于二项分类模型的一个自然而然的推广便是多项分类模型。
我们借鉴神经网络里提到的异或模型,有:
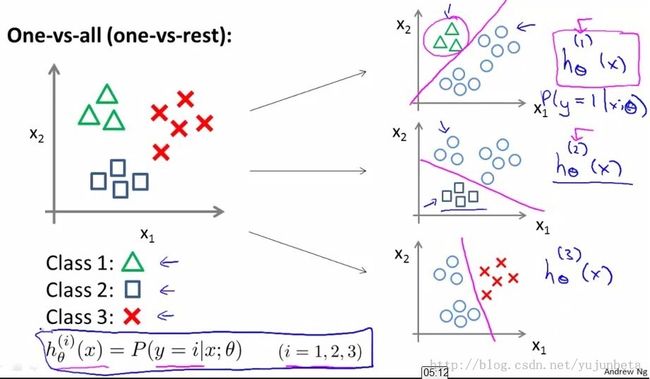
按照上面这种方法,给定一个输入向量x,获得最大hθ(x)的类就是x所分到的类。
选择最大的 hθ(x)十分好理解:在类别选择问题中,不论要选的类别是什么,每一个类别对做选择的经济个体来说都有或多或少的效用(没有效用的类别当然不会被考虑) ,一个类别的脱颖而出必然是因为该类别能产生出最高的效用。
我们将多项logit模型的数学表述叙述如下:
假定对于第i个观测,因变量Yi有M个取值:1,2,…,M,自变量为Xi,则多项logit模型为:
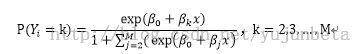
与logistic回归的似然估计类似,我们可以很容易写出多项logit的对数似然函数:
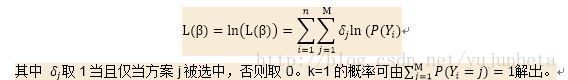
多项 Logit模型虽然好用,但从上面的叙述可以看出,多项 Logit 模型最大的限制在于各个类别必须是对等的,因此在可供选择的类别中,不可有主要类别和次要类别混杂在一起的情形。例如在研究旅游交通工具的选择时,可将交通工具的类别粗分为航空、火车、公用汽车、自用汽车四大类,但若将航空类别再依三家航空公司细分出三类而得到总共六个类别,则多项 Logit 模型就不适用,因为航空、火车、公用汽车、自用汽车均属同一等级的主要类别,而航空公司的区别则很明显的是较次要的类别,不应该混杂在一起。在这个例子中,主要类别和次要类别很容易分辨,但在其他的研究中可能就不是那么容易,若不慎将不同层级的类别混在一起,则由多项 Logit 模型所得到的实证结果就会有误差。
对于分类模型,我们还会遇到被解释变量中有分类变量的情形。对于连续变量解释离散变量,且被解释的离散变量是有顺序的(这个是和多项logit最大的区别)的情形,我们就需要考虑到order logit模型。
其数学模型叙述如下:
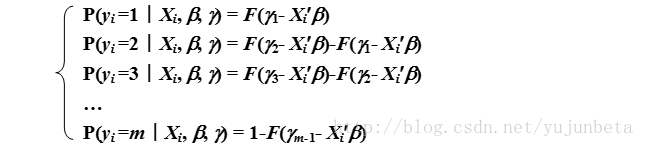
其中,F(.)表示累积分布函数,当F表示正态分布的分布函数时,对应的是order probit;F表示logistic分布时,变对应order logit。
与logistic分布类似,我们可以很容易写出其对数似然函数:

四、dummy variable
五、广义线性模型的R实现
R语言提供了广义线性模型的拟合函数glm(),其调用格式如下:
glm(formula, family = gaussian, data,weights, subset,
na.action, start = NULL, etastart, mustart, offset,
control= list(...), model = TRUE, method = "glm.fit",
x =FALSE, y = TRUE, contrasts = NULL, ...)
参数说明:
Formula:回归形式,与lm()函数的formula参数用法一致
Family:设置广义线性模型连接函数的典则分布族,glm()提供正态、指数、gamma、逆高斯、Poisson、二项分布。我们的logistic回归使用的是二项分布族binomial。Binomial族默认连接函数为logit,可设置为probit。
Data:数据集
鸢尾花例子使用的R代码:
logit.fit <- glm(Species~Petal.Width+Petal.Length, family = binomial(link = 'logit'), data = iris[51:150,]) logit.predictions <- ifelse(predict(logit.fit) > 0,'virginica', 'versicolor') table(iris[51:150,5],logit.predictions) probit.fit <- glm(Species~Petal.Width+Petal.Length, family = quasibinomial(link = 'probit'), data = iris[51:150,]) probit.predictions <- ifelse(predict(probit.fit) >0,'virginica', 'versicolor') table(iris[51:150,5],probit.predictions)
程序包mlogit提供了多项logit的模型拟合函数:
mlogit(formula, data, subset, weights,na.action, start = NULL,
alt.subset = NULL, reflevel = NULL,
nests = NULL, un.nest.el = FALSE, unscaled = FALSE,
heterosc = FALSE, rpar = NULL, probit = FALSE,
R = 40, correlation = FALSE, halton = NULL,
random.nb = NULL, panel = FALSE, estimate = TRUE,
seed = 10, ...)
mlogit.data(data, choice, shape = c("wide","long"), varying = NULL,
sep=".",alt.var = NULL, chid.var = NULL, alt.levels = NULL,id.var = NULL, opposite = NULL, drop.index = FALSE,
ranked = FALSE, ...)
参数说明:
formula:mlogit提供了条件logit,多项logit,混合logit多种模型,对于多项logit的估计模型应写为:因变量~0|自变量,如:mode ~ 0 | income
data:使用mlogit.data函数使得数据结构符合mlogit函数要求。
Choice:确定分类变量是什么
Shape:如果每一行是一个观测,我们选择wide,如果每一行是表示一个选择,那么就应该选择long。
alt.var:对于shape为long的数据,需要标明所有的选择名称
选择wide的数据示例:
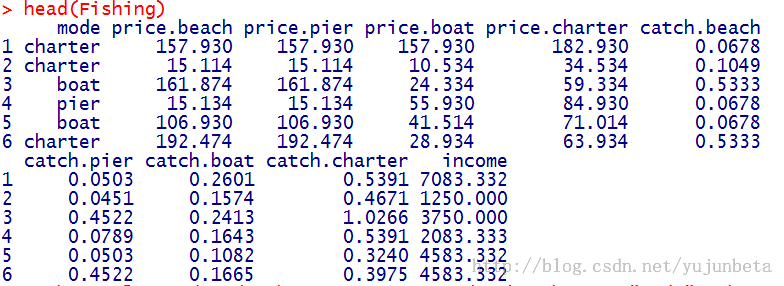
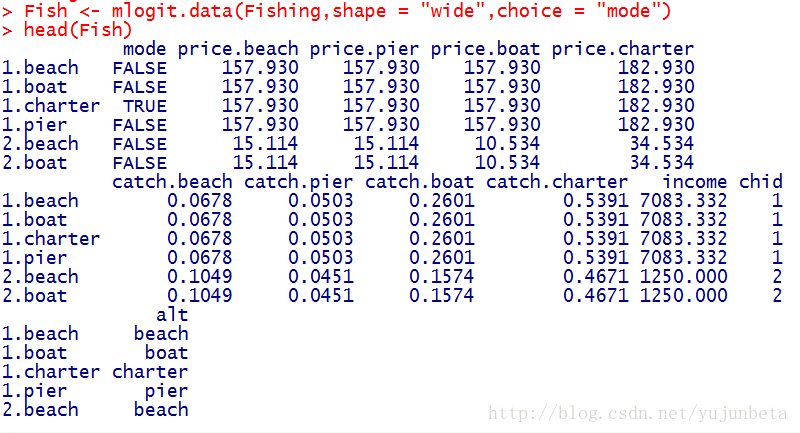
选择long的数据示例:
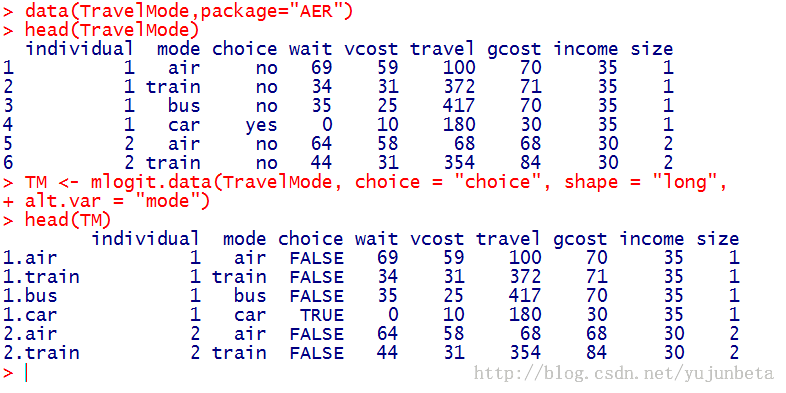
以fishing数据为例,来说明如何使用mlogit。
library(mlogit)
data("Fishing", package = "mlogit")
Fish <- mlogit.data(Fishing,shape = "wide",choice = "mode")
summary(mlogit(mode ~ 0 | income, data = Fish)) 这个输出的结果与nnet包中的multinom()函数一致。由于mlogit包可以做的logit模型更多,所以这里就不在对nnet包的multinom作介绍了,可以参见《根据Econometrics in R一书,将回归方法总结一下》一文。
程序包MASS提供polr()函数可以进行ordered logit或probit回归。用法如下:
polr(formula, data, weights, start, ..., subset, na.action,
contrasts = NULL, Hess = FALSE, model = TRUE,
method = c("logistic", "probit", "cloglog", "cauchit"))
参数说明:
Formula:回归形式,与lm()函数的formula参数用法一致
Data:数据集
Method:默认为order logit,选择probit时变为order probit模型。
以housing数据为例说明函数用法:
house.plr <- polr(Sat ~ Infl + Type + Cont, weights = Freq, data = housing) house.plr summary(house.plr, digits = 3)
这些结果十分直观,易于解读,所以我们在这里省略所有的输出结果。
再看手写数字案例:
最后,我们回到最开始的那个手写数字的案例,我们试着利用多项logit重做这个案例。(这个案例的描述与数据参见《kNN算法》一章)
特征的选择可参见《神经网络》一章。
由于手写数字的特征选取很容易导致回归系数矩阵是降秩的,所以我们使用nnet包的multinom()函数代替mlogit()。
运行下列代码:
setwd("D:/R/data/digits/trainingDigits") names<-list.files("D:/R/data/digits/trainingDigits") data<-paste("train",1:1934,sep="") for(i in 1:length(names)) assign(data[i],as.matrix(read.fwf(names[i],widths=rep(1,32)))) label<-factor(rep(0:9,c(189,198,195,199,186,187,195,201,180,204))) feature<-matrix(rep(0,length(names)*25),length(names),25) for(i in 1:length(names)){ feature[i,1]<-sum(get(data[i])[,16]) feature[i,2]<-sum(get(data[i])[,8]) feature[i,3]<-sum(get(data[i])[,24]) feature[i,4]<-sum(get(data[i])[16,]) feature[i,5]<-sum(get(data[i])[11,]) feature[i,6]<-sum(get(data[i])[21,]) feature[i,7]<-sum(diag(get(data[i]))) feature[i,8]<-sum(diag(get(data[i])[,32:1])) feature[i,9]<-sum((get(data[i])[17:32,17:32])) feature[i,10]<-sum((get(data[i])[1:8,1:8])) feature[i,11]<-sum((get(data[i])[9:16,1:8])) feature[i,12]<-sum((get(data[i])[17:24,1:8])) feature[i,13]<-sum((get(data[i])[25:32,1:8])) feature[i,14]<-sum((get(data[i])[1:8,9:16])) feature[i,15]<-sum((get(data[i])[9:16,9:16])) feature[i,16]<-sum((get(data[i])[17:24,9:16])) feature[i,17]<-sum((get(data[i])[25:32,9:16])) feature[i,18]<-sum((get(data[i])[1:8,17:24])) feature[i,19]<-sum((get(data[i])[9:16,17:24])) feature[i,20]<-sum((get(data[i])[17:24,17:24])) feature[i,21]<-sum((get(data[i])[25:32,17:24])) feature[i,22]<-sum((get(data[i])[1:8,25:32])) feature[i,23]<-sum((get(data[i])[9:16,25:32])) feature[i,24]<-sum((get(data[i])[17:24,25:32])) feature[i,25]<-sum((get(data[i])[25:32,25:32])) } data1 <- data.frame(feature,label) #降秩时mlogit不可用 #data10<- mlogit.data(data1,shape = "wide",choice = "label") #m1<-mlogit(label~0|X1+X2+X3+X4+X5+X6+X7+X8+X9+X10+X11+X12+X13+X14+X15+X16+X17+X18+X19+X20+X21+X22+X23+X24+X25,data=data10) library(nnet) m1<-multinom(label ~ ., data = data1) pred<-predict(m1,data1) table(pred,label) sum(diag(table(pred,label)))/length(names) setwd("D:/R/data/digits/testDigits") name<-list.files("D:/R/data/digits/testDigits") data1<-paste("train",1:1934,sep="") for(i in 1:length(name)) assign(data1[i],as.matrix(read.fwf(name[i],widths=rep(1,32)))) feature<-matrix(rep(0,length(name)*25),length(name),25) for(i in 1:length(name)){ feature[i,1]<-sum(get(data1[i])[,16]) feature[i,2]<-sum(get(data1[i])[,8]) feature[i,3]<-sum(get(data1[i])[,24]) feature[i,4]<-sum(get(data1[i])[16,]) feature[i,5]<-sum(get(data1[i])[11,]) feature[i,6]<-sum(get(data1[i])[21,]) feature[i,7]<-sum(diag(get(data1[i]))) feature[i,8]<-sum(diag(get(data1[i])[,32:1])) feature[i,9]<-sum((get(data1[i])[17:32,17:32])) feature[i,10]<-sum((get(data1[i])[1:8,1:8])) feature[i,11]<-sum((get(data1[i])[9:16,1:8])) feature[i,12]<-sum((get(data1[i])[17:24,1:8])) feature[i,13]<-sum((get(data1[i])[25:32,1:8])) feature[i,14]<-sum((get(data1[i])[1:8,9:16])) feature[i,15]<-sum((get(data1[i])[9:16,9:16])) feature[i,16]<-sum((get(data1[i])[17:24,9:16])) feature[i,17]<-sum((get(data1[i])[25:32,9:16])) feature[i,18]<-sum((get(data1[i])[1:8,17:24])) feature[i,19]<-sum((get(data1[i])[9:16,17:24])) feature[i,20]<-sum((get(data1[i])[17:24,17:24])) feature[i,21]<-sum((get(data1[i])[25:32,17:24])) feature[i,22]<-sum((get(data1[i])[1:8,25:32])) feature[i,23]<-sum((get(data1[i])[9:16,25:32])) feature[i,24]<-sum((get(data1[i])[17:24,25:32])) feature[i,25]<-sum((get(data1[i])[25:32,25:32])) } labeltest<-factor(rep(0:9,c(87,97,92,85,114,108,87,96,91,89))) data2<-data.frame(feature,labeltest) pred1<-predict(m1,data2) table(pred1,labeltest) sum(diag(table(pred1,labeltest)))/length(name)
经整理,输出结果如下:(左边为训练集,右边为测试集)
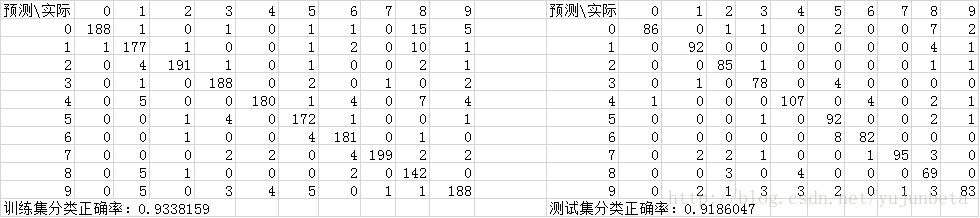
Tips: oddsratio=p/1-p 相对风险指数
贝努力模型中 P是发生A事件的概率,1-p是不发生A事件的概率
所以p/1-p是 发生与不发生的相对风险。
OR值等于1,表示该因素对A事件发生不起作用;
OR值大于1,表示A事件发生的可能性大于不发生的可能性;
OR值小于1,表示A事件不发生的可能性大于发生的可能性。
Further reading:
Yves Croissant:Estimation of multinomial logit models in R : The mlogit Packages
预告:
本文之后待写的文章有:
- 算法提升:组合方法提高分类效率
- 算法评价:几种分类方法的绩效讨论