QQ游戏百万人同时在线服务器架构实现
QQ游戏于前几日终于突破了百万人同时在线的关口,向着更为远大的目标迈进,这让其它众多传统的棋牌休闲游戏平台黯然失色,相比之下,联众似乎已经根本不是QQ的对手,因为QQ除了这100万的游戏在线人数外,它还拥有3亿多的注册量(当然很多是重复注册的)以及QQ聊天软件900万的同时在线率,我们已经可以预见未来由QQ构建起来的强大棋牌休闲游戏帝国。
服务器程序,其可承受的同时连接数目是有理论峰值的,通过C++中对TSocket的定义类型:word,我们可以判定这个连接理论峰值是65535,也就是说,你的单个服务器程序,最多可以承受6万多的用户同时连接。但是,在实际应用中,能达到一万人的同时连接并能保证正常的数据交换已经是很不容易了,通常这个值都在2000到5000之间,据说QQ的单台服务器同时连接数目也就是在这个值这间。
如果要实现2000到5000用户的单服务器同时在线,是不难的。在windows下,比较成熟的技术是采用IOCP--完成端口。与完成端口相关的资料在网上和CSDN论坛里有很多,感兴趣的朋友可以自己搜索一下。只要运用得当,一个完成端口服务器是完全可以达到2K到5K的同时在线量的。但,5K这样的数值离百万这样的数值实在相差太大了,所以,百万人的同时在线是单台服务器肯定无法实现的。
要实现百万人同时在线,首先要实现一个比较完善的完成端口服务器模型,这个模型要求至少可以承载2K到5K的同时在线率(当然,如果你MONEY多,你也可以只开发出最多允许100人在线的服务器)。在构建好了基本的完成端口服务器之后,就是有关服务器组的架构设计了。之所以说这是一个服务器组,是因为它绝不仅仅只是一台服务器,也绝不仅仅是只有一种类型的服务器。
简单地说,实现百万人同时在线的服务器模型应该是:登陆服务器+大厅服务器+房间服务器。当然,也可以是其它的模型,但其基本的思想是一样的。下面,我将逐一介绍这三类服务器的各自作用。
登陆服务器:一般情况下,我们会向玩家开放若干个公开的登陆服务器,就如QQ登陆时让你选择的从哪个QQ游戏服务器登陆一样,QQ登陆时让玩家选择的六个服务器入口实际上就是登陆服务器。登陆服务器主要完成负载平衡的作用。详细点说就是,在登陆服务器的背后,有N个大厅服务器,登陆服务器只是用于为当前的客户端连接选择其下一步应该连接到哪个大厅服务器,当登陆服务器为当前的客户端连接选择了一个合适的大厅服务器后,客户端开始根据登陆服务器提供的信息连接到相应的大厅上去,同时客户端断开与登陆服务器的连接,为其他玩家客户端连接登陆服务器腾出套接字资源。在设计登陆服务器时,至少应该有以下功能:N个大厅服务器的每一个大厅服务器都要与所有的登陆服务器保持连接,并实时地把本大厅服务器当前的同时在线人数通知给各个登陆服务器,这其中包括:用户进入时的同时在线人数增加信息以及用户退出时的同时在线人数减少信息。这里的各个大厅服务器同时在线人数信息就是登陆服务器为客户端选择某个大厅让其登陆的依据。举例来说,玩家A通过登陆服务器1连接到登陆服务器,登陆服务器开始为当前玩家在众多的大厅服务器中根据哪一个大厅服务器人数比较少来选择一个大厅,同时把这个大厅的连接IP和端口发给客户端,客户端收到这个IP和端口信息后,根据这个信息连接到此大厅,同时,客户端断开与登陆服务器之间的连接,这便是用户登陆过程中,在登陆服务器这一块的处理流程。
大厅服务器:大厅服务器,是普通玩家看不到的服务器,它的连接IP和端口信息是登陆服务器通知给客户端的。也就是说,在QQ游戏的本地文件中,具体的大厅服务器连接IP和端口信息是没有保存的。大厅服务器的主要作用是向玩家发送游戏房间列表信息,这些信息包括:每个游戏房间的类型,名称,在线人数,连接地址以及其它如游戏帮助文件URL的信息。从界面上看的话,大厅服务器就是我们输入用户名和密码并校验通过后进入的游戏房间列表界面。大厅服务器,主要有以下功能:一是向当前玩家广播各个游戏房间在线人数信息;二是提供游戏的版本以及下载地址信息;三是提供各个游戏房间服务器的连接IP和端口信息;四是提供游戏帮助的URL信息;五是提供其它游戏辅助功能。但在这众多的功能中,有一点是最为核心的,即:为玩家提供进入具体的游戏房间的通道,让玩家顺利进入其欲进入的游戏房间。玩家根据各个游戏房间在线人数,判定自己进入哪一个房间,然后双击服务器列表中的某个游戏房间后玩家开始进入游戏房间服务器。
游戏房间服务器:游戏房间服务器,具体地说就是如“斗地主1”,“斗地主2”这样的游戏房间。游戏房间服务器才是具体的负责执行游戏相关逻辑的服务器。这样的游戏逻辑分为两大类:一类是通用的游戏房间逻辑,如:进入房间,离开房间,进入桌子,离开桌子以及在房间内说话等;第二类是游戏桌子逻辑,这个就是各种不同类型游戏的主要区别之处了,比如斗地主中的叫地主或不叫地主的逻辑等,当然,游戏桌子逻辑里也包括有通用的各个游戏里都存在的游戏逻辑,比如在桌子内说话等。总之,游戏房间服务器才是真正负责执行游戏具体逻辑的服务器。
这里提到的三类服务器,我均采用的是完成端口模型,每个服务器最多连接数目是5000人,但是,我在游戏房间服务器上作了逻辑层的限定,最多只允许300人同时在线。其他两个服务器仍然允许最多5000人的同时在线。如果按照这样的结构来设计,那么要实现百万人的同时在线就应该是这样:首先是大厅,1000000/5000=200。也就是说,至少要200台大厅服务器,但通常情况下,考虑到实际使用时服务器的处理能力和负载情况,应该至少准备250台左右的大厅服务器程序。另外,具体的各种类型的游戏房间服务器需要多少,就要根据当前玩各种类型游戏的玩家数目分别计算了,比如斗地主最多是十万人同时在线,每台服务器最多允许300人同时在线,那么需要的斗地主服务器数目就应该不少于:100000/300=333,准备得充分一点,就要准备350台斗地主服务器。
除正常的玩家连接外,还要考虑到:
对于登陆服务器,会有250台大厅服务器连接到每个登陆服务器上,这是始终都要保持的连接;
而对于大厅服务器而言,如果仅仅有斗地主这一类的服务器,就要有350多个连接与各个大厅服务器始终保持着。所以从这一点看,我的结构在某些方面还存在着需要改进的地方,但核心思想是:尽快地提供用户登陆的速度,尽可能方便地让玩家进入游戏中。
那现在来说,稳定的中间件应该是什么样子呢?
对于客户端请求,如果发现服务停止,可以实现服务无缝转移---这叫不丢失任何服务.
对于多个客户端请求,可以讲请求轮巡到不同的服务器上---这样叫负荷平摊,如果再做到可以根据客户端数量方面地增减服务器数量,那就能很通过简单增加服务器,实现系统效率的提升。
最牛的是,如果你再加上分布式程序设计。一个函数,根据服务器负荷平摊的特点,可以让多个服务器,同时为一个函数工作。
思考:
第一:客户端请求,实现轮巡。
知道了请求,需要轮巡。就要先知道有那些服务器---》 设计服务器注册注销机制。
还要知道请求当前,每台服务器上有那些负荷---》客户端请求计算机制。
然后根据这些,计算当前请求由那个服务器来完成任务。
第二:故障热切换
经试验验证,故障有三种情况
A)请求选择服务器前,有故障。
B)服务器选中后,准备开始要服务时,故障。
C)服务正在进行时,发生故障
为解决以上问题,我做出如下架构:
1、 在客户端,开发了安全访问机制,保证在有服务存在的情况,单次的访问异常,可以容错;同时若访问时发生故障,重新请求。
2、中间层开发了负荷平衡机制,其建立的集群,对客户端来说,是一个透明体。客户端只需要知道公布的服务集群IP地址,由负荷平衡自动分配请求;同时服务器发生故障时,自动从集群中移去,将请求切换至其它正常的服务器上。(中间层是一个无状态,多线程,分布式的应用程序服务,对任何一个请求,由哪台服务器提供服务都可以达到一致的目标)
动态应用,是相对于网站静态内容而言,是指以c/c++、php、Java、perl、.net等服务器端语言开发的网络应用软件,比如论坛、网络相册、交友、BLOG等常见应用。动态应用系统通常与数据库系统、缓存系统、分布式存储系统等密不可分。
大型动态应用系统平台主要是针对于大流量、高并发网站建立的底层系统架构。大型网站的运行需要一个可靠、安全、可扩展、易维护的应用系统平台做为支撑,以保证网站应用的平稳运行。
大型动态应用系统又可分为几个子系统:
l Web前端系统
l 负载均衡系统
l 数据库集群系统
l 缓存系统
l 分布式存储系统
l 分布式服务器管理系统
l 代码分发系统
Web前端系统
结构图:
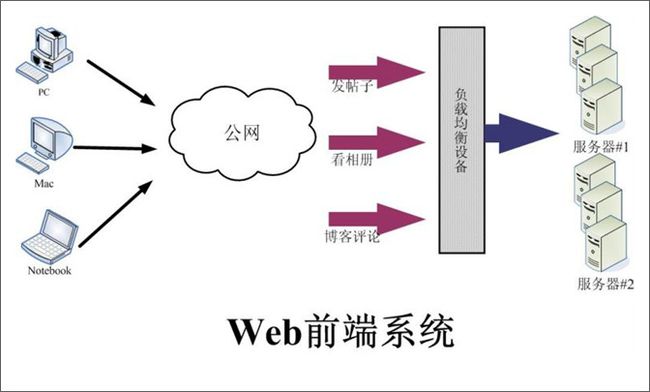
为了达到不同应用的服务器共享、避免单点故障、集中管理、统一配置等目的,不以应用划分服务器,而是将所有服务器做统一使用,每台服务器都可以对多个应用提供服务,当某些应用访问量升高时,通过增加服务器节点达到整个服务器集群的性能提高,同时使他应用也会受益。该Web前端系统基于Apache/Lighttpd/Eginx等的虚拟主机平台,提供PHP程序运行环境。服务器对开发人员是透明的,不需要开发人员介入服务器管理
负载均衡系统
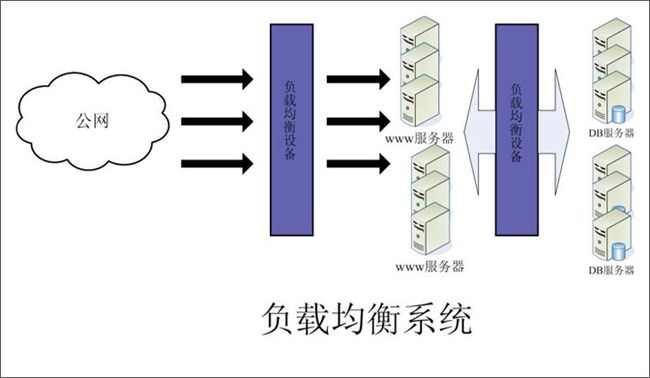
负载均衡系统分为硬件和软件两种。硬件负载均衡效率高,但是价格贵,比如F5等。软件负载均衡系统价格较低或者免费,效率较硬件负载均衡系统低,不过对于流量一般或稍大些网站来讲也足够使用,比如lvs/nginx/haproxy。大多数网站都是硬件、软件负载均衡系统并用。
数据库集群系统
结构图:
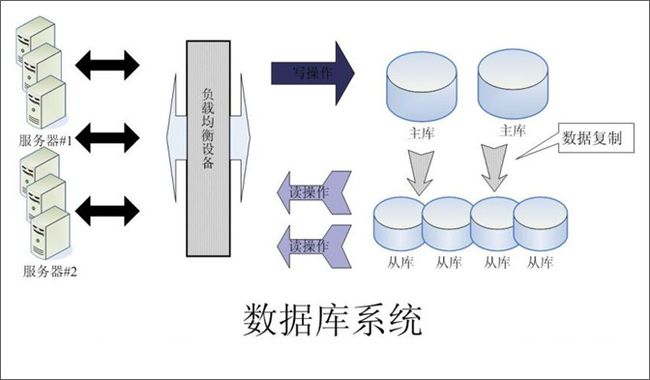
由于Web前端采用了负载均衡集群结构提高了服务的有效性和扩展性,因此数据库必须也是高可靠的才能保证整个服务体系的高可靠性,如何构建一个高可靠的、可以提供大规模并发处理的数据库体系?
我们可以采用如上图所示的方案:
1) 使用 MySQL 数据库,考虑到Web应用的数据库读多写少的特点,我们主要对读数据库做了优化,提供专用的读数据库和写数据库,在应用程序中实现读操作和写操作分别访问不同的数据库。
2) 使用 MySQL Replication 机制实现快速将主库(写库)的数据库复制到从库(读库)。一个主库对应多个从库,主库数据实时同步到从库。
3) 写数据库有多台,每台都可以提供多个应用共同使用,这样可以解决写库的性能瓶颈问题和单点故障问题。
4) 读数据库有多台,通过负载均衡设备实现负载均衡,从而达到读数据库的高性能、高可靠和高可扩展性。
5) 数据库服务器和应用服务器分离。
6) 从数据库使用BigIP做负载均衡。
缓存系统
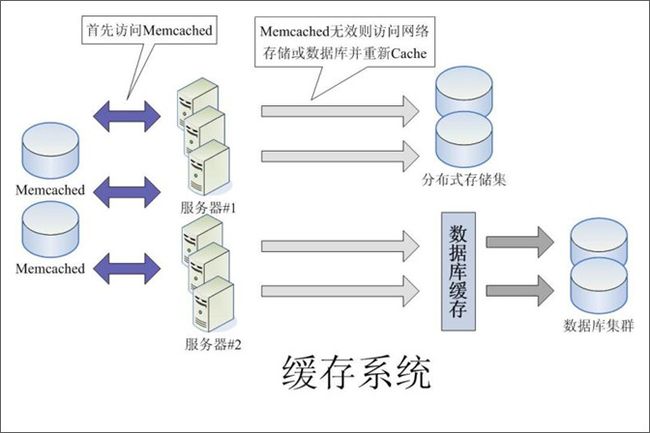
缓存分为文件缓存、内存缓存、数据库缓存。在大型Web应用中使用最多且效率最高的是内存缓存。最常用的内存缓存工具是Memcachd。使用正确的缓存系统可以达到实现以下目标:
1、 使用缓存系统可以提高访问效率,提高服务器吞吐能力,改善用户体验。
2、 减轻对数据库及存储集服务器的访问压力
3、 Memcached服务器有多台,避免单点故障,提供高可靠性和可扩展性,提高性能。
分布式存储系统
结构图:
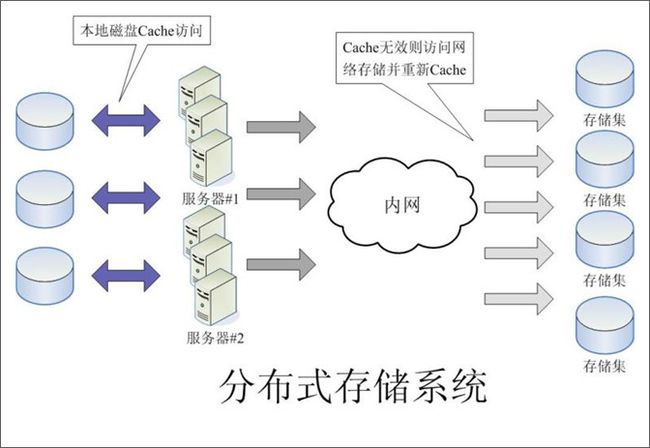
WEB系统平台中的存储需求有下面两个特点:
1) 存储量很大,经常会达到单台服务器无法提供的规模,比如相册、视频等应用。因此需要专业的大规模存储系统。
2) 负载均衡cluster中的每个节点都有可能访问任何一个数据对象,每个节点对数据的处理也能被其他节点共享,因此这些节点要操作的数据从逻辑上看只能是一个整体,不是各自独立的数据资源。
因此高性能的分布式存储系统对于大型网站应用来说是非常重要的一环。(这个地方需要加入对某个分布式存储系统的简单介绍。)
分布式服务器管理系统
结构图:
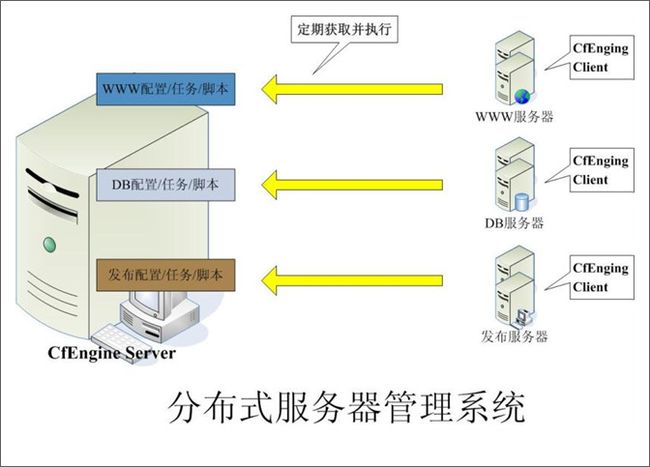
随着网站访问流量的不断增加,大多的网络服务都是以负载均衡集群的方式对外提供服务,随之集群规模的扩大,原来基于单机的服务器管理模式已经不能够满足我们的需求,新的需求必须能够集中式的、分组的、批量的、自动化的对服务器进行管理,能够批量化的执行计划任务。
在分布式服务器管理系统软件中有一些比较优秀的软件,其中比较理想的一个是 Cfengine。它可以对服务器进行分组,不同的分组可以分别定制系统配置文件、计划任务等配置。它是基于C/S 结构的,所有的服务器配置和管理脚本程序都保存在Cfengine Server上,而被管理的服务器运行着 Cfengine Client 程序,Cfengine Client通过SSL加密的连接定期的向服务器端发送请求以获取最新的配置文件和管理命令、脚本程序、补丁安装等任务。
有了Cfengine 这种集中式的服务器管理工具,我们就可以高效的实现大规模的服务器集群管理,被管理服务器和 Cfengine Server 可以分布在任何位置,只要网络可以连通就能实现快速自动化的管理。
代码发布系统
结构图:
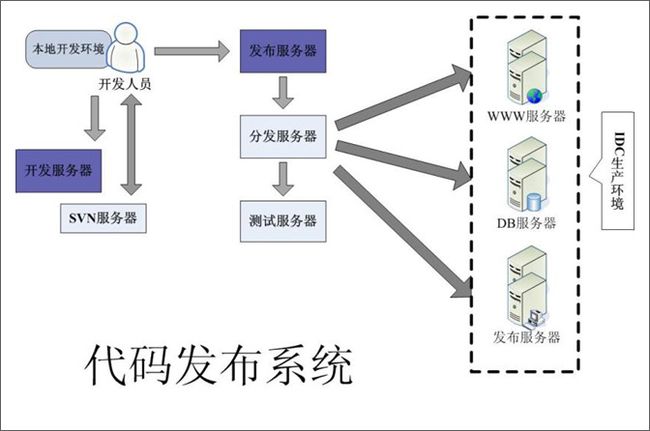
随着网站访问流量的不断增加,大多的网络服务都是以负载均衡集群的方式对外提供服务,随之集群规模的扩大,为了满足集群环境下程序代码的批量分发和更新,我们还需要一个程序代码发布系统。
这个发布系统可以帮我们实现下面的目标:
1) 生产环境的服务器以虚拟主机方式提供服务,不需要开发人员介入维护和直接操作,提供发布系统可以实现不需要登陆服务器就能把程序分发到目标服务器。
2) 我们要实现内部开发、内部测试、生产环境测试、生产环境发布的4个开发阶段的管理,发布系统可以介入各个阶段的代码发布。
3) 我们需要实现源代码管理和版本控制,SVN可以实现该需求。
这里面可以使用常用的工具Rsync,通过开发相应的脚本工具实现服务器集群间代码同步分发。
千万级的注册用户,千万级的帖子,nTB级的附件,还有巨大的日访问量,大型网站采用什么系统架构保证性能和稳定性?
首先讨论一下大型网站需要注意和考虑的问题。
数据库海量数据处理:负载量不大的情况下select、delete和update是响应很迅速的,最多加几个索引就可以搞定,但千万级的注册用户和一个设计不好的多对多关系将带来非常严重的性能问题。另外在高UPDATE的情况下,更新一个聚焦索引的时间基本上是不可忍受的。索引和更新是一对天生的冤家。
高并发死锁:平时我们感觉不到,但数据库死锁在高并发的情况下的出现的概率是非常高的。
文件存储的问题:大型网站有海量图片数据、视频数据、文件数据等等,他们如何存储并被有效索引?高并发的情况下IO的瓶颈问题会迅速显现。也许用RAID和专用存贮服务器能解决眼下的问题,但是还有个问题就是各地的访问问题,也许我们的服务器在北京,可能在云南或者新疆的访问速度如何解决?如果做分布式,那么我们的文件索引以及架构该如何规划。
接下来讨论大型网站的底层系统架构,来有效的解决上述问题。
毋庸置疑,对于规模稍大的网站来说,其背后必然是一个服务器集群来提供网站服务,例如,2004年eBay的服务器有2400台,估计现在更多。当然,数据库也必然要和应用服务分开,有单独的数据库服务器集群。对于像淘宝网这样规模的网站而言,就是应用也分成很多组。
下面,就从服务器操作系统与Web服务器、数据库、服务器集群与负载均衡、缓存、独立的图片服务器、其它等几个方面来分析大型网站的系统架构。
服务器操作系统与Web服务器
最底层首先是操作系统。好的操作系统能提高好的性能、稳定性和安全性,而这些对大型网站的性能、安全性和稳定性都是至关重要的。
淘宝网(阿里巴巴): Linux操作系统 + Web 服务器: Apache
新浪:FreeBSD + Web 服务器:Apache
Yahoo:FreeBSD + Web 服务器:自己的
Google: 部分Linux + Web 服务器:自己的
百度:Linux + Web 服务器: Apache
网易:Linux + Web 服务器: Apache
eBay: Windows Server 2003/8 (大量) + Web 服务器:Microsoft IIS
MySpace: Windows Server 2003/8 + Web 服务器:Microsoft IIS
由此可见,开源操作系统做Web应用是首选已经是一个既定事实。在开源操作系统中Linux和FreeBSD差不太多,很难说哪个一定比另外一个要优秀很多、能够全面的超越对手,应该是各有所长。但熟悉Linux的技术人员更多些,利于系统管理、优化等,所以Linux使用更广泛。而Windows Server和IIS虽然有的网站使用,但不开源,而且需要购买微软的一系列应用产品,限制了其使用。总之,开源操作系统,尤其是Linux做Web应用是首选已经是一个既定事实。
常用的系统架构是:
Linux + Apache + PHP + MySQL
Linux + Apache + Java (WebSphere) + Oracle
Windows Server 2003/2008 + IIS + C#/ASP.NET + 数据库
数据库
因为是千万人同时访问的网站,所以一般是有很多个数据库同时工作的,说明白一点就是数据库集群和并发控制,数据分布到地理位置不同的数据中心,以免发生断电事故。
主流的数据库有Sun的是MySQL和Oracle。
Oracle是一款优秀的、广泛采用的商业数据库管理软件。有很强大的功能和安全性,可以处理相对海量的数据。而MySQL是一款非常优秀的开源数据库管理软件,非常适合用多台PC Server组成多点的存储节点阵列(这里我所指的不是MySQL自身提供的集群功能),每单位的数据存储成本也非常的低廉。用多台PC Server安装MySQL组成一个存储节点阵列,通过MySQL自身的Replication或者应用自身的处理,可以很好的保证容错(允许部分节点失效),保证应用的健壮性和可靠性。可以这么说,在关系数据库管理系统的选择上,可以考虑应用本身的情况来决定。
MySQL数据库服务器的master-slave模式,利用数据库服务器在主从服务器间进行同步,应用只把数据写到主服务器,而读数据时则根据负载选择一台从服务器或者主服务器来读取,将数据按不同策略划分到不同的服务器(组)上,分散数据库压力。
服务器集群与负载均衡
服务器群集中每个服务结点运行一个所需服务器程序的独立拷贝,而网络负载均衡则将工作负载在这些主机间进行分配。负载均衡建立在现有网络结构之上,它提供了一种廉价有效的方法扩展服务器带宽和增加吞吐量,加强网络数据处理能力,提高网络的灵活性和可用性。它主要完成以下任务:解决网络拥塞问题,服务就近提供,实现地理位置无关性 ;为用户提供更好的访问质量;提高服务器响应速度;提高服务器及其他资源的利用效率;避免了网络关键部位出现单点失效。
常用的服务器集群和数据库集群负载均衡实现方法:
Citrix NetScaler的硬件负载均衡交换机做服务器集群的负载均衡。
MySQL Proxy做MySQL服务器集群的负载均衡并实现读写分离。其实现读写分离的基本原理是让主数据库处理事务性查询,而从数据库处理SELECT查询。数据库复制被用来把事务性查询导致的变更同步到集群中的从数据库。
CDN (Content Delivery Network): 几乎在各大网站都有使用该技术。例如,使得你的网站在各省市访问更快,其原理是采取了分布式网络缓存结构(即国际上流行的web cache技术),通过在现有的Internet中增加一层新的网络架构,将网站的内容发布到最接近用户的cache服务器内,通过DNS负载均衡的技术,判断用户来源就近访问cache服务器取得所需的内容,解决Internet网络拥塞状况,提高用户访问网站的响应速度,如同提供了多个分布在各地的加速器,以达到快速、可冗余的为多个网站加速的目的。
缓存
众所周知,使用缓存能有效应对大负载,减少数据库的压力,并显著提高多层应用程序的性能,但如何在集群环境中使多个缓存、多层缓存并保存同步是个重大问题。大型网站一般都使用缓存服务器群,并使用多层缓存。业内最常用的有:
Squid cache,Squid服务器群,把它作为web服务器端前置cache服务器缓存相关请求来提高web服务器速度。Squid将大部分静态资源(图片,js,css等)缓存起来,直接返回给访问者,减少应用服务器的负载
memcache,memcache服务器群,一款分布式缓存产品,很多大型网站在应用; 它可以应对任意多个连接,使用非阻塞的网络IO。由于它的工作机制是在内存中开辟一块空间,然后建立一个HashTable,Memcached自管理这些HashTable。
e-Accelerator,比较特殊,PHP的缓存和加速器。是一个免费开源的PHP加速、优化、编译和动态缓存的项目,它可以通过缓存PHP代码编译后的结果来提高PHP脚本的性能,使得一向很复杂和离我们很远的 PHP脚本编译问题完全得到解决。通过使用eAccelerator,可以优化你的PHP代码执行速度,降低服务器负载,可以提高PHP应用执行速度最高达10倍。
独立的图片服务器
无论从管理上,还是从性能上看,只要有可能,尽量部署独立的图片服务器。这几乎成为常识了。具备独立的图片服务器或者服务器集群后,在 Web 服务器上就可以有针对性的进行配置优化。
其他
一个互联网应用,除了服务器的操作系统,Web Server软件,应用服务器软件,数据库软件外,我们还会涉及到一些其他的系统,比如一些中间件系统、文件存储系统(图片服务器,视频服务器,管理服务器,RSS和广告服务器等等)、全文检索、搜索、等等。会在以后介绍。
架构演变第一步:物理分离webserver和数据库
最开始,由于某些想法,于是在互联网上搭建了一个网站,这个时候甚至有可能主机都是租借的,但由于这篇文章我们只关注架构的演变历程,因此就假设这个时候已经是托管了一台主机,并且有一定的带宽了,这个时候由于网站具备了一定的特色,吸引了部分人访问,逐渐你发现系统的压力越来越高,响应速度越来越慢,而这个时候比较明显的是数据库和应用互相影响,应用出问题了,数据库也很容易出现问题,而数据库出问题的时候,应用也容易出问题,于是进入了第一步演变阶段:将应用和数据库从物理上分离,变成了两台机器,这个时候技术上没有什么新的要求,但你发现确实起到效果了,系统又恢复到以前的响应速度了,并且支撑住了更高的流量,并且不会因为数据库和应用形成互相的影响。
这一步涉及到了这些知识体系:
这一步架构演变对技术上的知识体系基本没有要求。
构架构演变第二步:增加页面缓存
好景不长,随着访问的人越来越多,你发现响应速度又开始变慢了,查找原因,发现是访问数据库的操作太多,导致数据连接竞争激烈,所以响应变慢,但数据库连接又不能开太多,否则数据库机器压力会很高,因此考虑采用缓存机制来减少数据库连接资源的竞争和对数据库读的压力,这个时候首先也许会选择采用squid 等类似的机制来将系统中相对静态的页面(例如一两天才会有更新的页面)进行缓存(当然,也可以采用将页面静态化的方案),这样程序上可以不做修改,就能够 很好的减少对webserver的压力以及减少数据库连接资源的竞争,OK,于是开始采用squid来做相对静态的页面的缓存。
这一步涉及到了这些知识体系:
前端页面缓存技术,例如squid,如想用好的话还得深入掌握下squid的实现方式以及缓存的失效算法等。
架构演变第三步:增加页面片段缓存
增加了squid做缓存后,整体系统的速度确实是提升了,webserver的压力也开始下降了,但随着访问量的增加,发现系统又开始变的有些慢了,在尝 到了squid之类的动态缓存带来的好处后,开始想能不能让现在那些动态页面里相对静态的部分也缓存起来呢,因此考虑采用类似ESI之类的页面片段缓存策略,OK,于是开始采用ESI来做动态页面中相对静态的片段部分的缓存。
这一步涉及到了这些知识体系:
页面片段缓存技术,例如ESI等,想用好的话同样需要掌握ESI的实现方式等;
架构演变第四步:数据缓存
在采用ESI之类的技术再次提高了系统的缓存效果后,系统的压力确实进一步降低了,但同样,随着访问量的增加,系统还是开始变慢,经过查找,可能会发现系 统中存在一些重复获取数据信息的地方,像获取用户信息等,这个时候开始考虑是不是可以将这些数据信息也缓存起来呢,于是将这些数据缓存到本地内存,改变完毕后,完全符合预期,系统的响应速度又恢复了,数据库的压力也再度降低了不少。
这一步涉及到了这些知识体系:
缓存技术,包括像Map数据结构、缓存算法、所选用的框架本身的实现机制等。
架构演变第五步: 增加webserver
好景不长,发现随着系统访问量的再度增加,webserver机器的压力在高峰期会上升到比较高,这个时候开始考虑增加一台webserver,这也是为了同时解决可用性的问题,避免单台的webserver down机的话就没法使用了,在做了这些考虑后,决定增加一台webserver,增加一台webserver时,会碰到一些问题,典型的有:
1、如何让访问分配到这两台机器上,这个时候通常会考虑的方案是Apache自带的负载均衡方案,或LVS这类的软件负载均衡方案;
2、如何保持状态信息的同步,例如用户session等,这个时候会考虑的方案有写入数据库、写入存储、cookie或同步session信息等机制等;
3、如何保持数据缓存信息的同步,例如之前缓存的用户数据等,这个时候通常会考虑的机制有缓存同步或分布式缓存;
4、如何让上传文件这些类似的功能继续正常,这个时候通常会考虑的机制是使用共享文件系统或存储等;
在解决了这些问题后,终于是把webserver增加为了两台,系统终于是又恢复到了以往的速度。
这一步涉及到了这些知识体系:
负载均衡技术(包括但不限于硬件负载均衡、软件负载均衡、负载算法、linux转发协议、所选用的技术的实现细节等)、主备技术(包括但不限于ARP欺骗、linux heart-beat等)、状态信息或缓存同步技术(包括但不限于Cookie技术、UDP协议、状态信息广播、所选用的缓存同步技术的实现细节等)、共享文件技术(包括但不限于NFS等)、存储技术(包括但不限于存储设备等)。
架构演变第六步:分库
享受了一段时间的系统访问量高速增长的幸福后,发现系统又开始变慢了,这次又是什么状况呢,经过查找,发现数据库写入、更新的这些操作的部分数据库连接的资源竞争非常激烈,导致了系统变慢,这下怎么办呢,此时可选的方案有数据库集群和分库策略,集群方面像有些数据库支持的并不是很好,因此分库会成为比较普遍的策略,分库也就意味着要对原有程序进行修改,一通修改实现分库后,不错,目标达到了,系统恢复甚至速度比以前还快了。
这一步涉及到了这些知识体系:
这一步更多的是需要从业务上做合理的划分,以实现分库,具体技术细节上没有其他的要求;
但同时随着数据量的增大和分库的进行,在数据库的设计、调优以及维护上需要做的更好,因此对这些方面的技术还是提出了很高的要求的。
架构演变第七步:分表、DAL和分布式缓存
随着系统的不断运行,数据量开始大幅度增长,这个时候发现分库后查询仍然会有些慢,于是按照分库的思想开始做分表的工作,当然,这不可避免的会需要对程序进行一些修改,也许在这个时候就会发现应用自己要关心分库分表的规则等,还是有些复杂的,于是萌生能否增加一个通用的框架来实现分库分表的数据访问,这个在ebay的架构中对应的就是DAL,这个演变的过程相对而言需要花费较长的时间,当然,也有可能这个通用的框架会等到分表做完后才开始做,同时,在这个阶段可能会发现之前的缓存同步方案出现问题,因为数据量太大,导致现在不太可能将缓存存在本地,然后同步的方式,需要采用分布式缓存方案了,于是,又是一通考察和折磨,终于是将大量的数据缓存转移到分布式缓存上了。
这一步涉及到了这些知识体系:
分表更多的同样是业务上的划分,技术上涉及到的会有动态hash算法、consistent hash算法等;
DAL涉及到比较多的复杂技术,例如数据库连接的管理(超时、异常)、数据库操作的控制(超时、异常)、分库分表规则的封装等;
架构演变第八步:增加更多的webserver
在做完分库分表这些工作后,数据库上的压力已经降到比较低了,又开始过着每天看着访问量暴增的幸福生活了,突然有一天,发现系统的访问又开始有变慢的趋势了,这个时候首先查看数据库,压力一切正常,之后查看webserver,发现apache阻塞了很多的请求,而应用服务器对每个请求也是比较快的,看来 是请求数太高导致需要排队等待,响应速度变慢,这还好办,一般来说,这个时候也会有些钱了,于是添加一些webserver服务器,在这个添加 webserver服务器的过程,有可能会出现几种挑战:
1、Apache的软负载或LVS软负载等无法承担巨大的web访问量(请求连接数、网络流量等)的调度了,这个时候如果经费允许的话,会采取的方案是购 买硬件负载,例如F5、Netsclar、Athelon之类的,如经费不允许的话,会采取的方案是将应用从逻辑上做一定的分类,然后分散到不同的软负载集群中;
2、原有的一些状态信息同步、文件共享等方案可能会出现瓶颈,需要进行改进,也许这个时候会根据情况编写符合网站业务需求的分布式文件系统等;
在做完这些工作后,开始进入一个看似完美的无限伸缩的时代,当网站流量增加时,应对的解决方案就是不断的添加webserver。
这一步涉及到了这些知识体系:
到了这一步,随着机器数的不断增长、数据量的不断增长和对系统可用性的要求越来越高,这个时候要求对所采用的技术都要有更为深入的理解,并需要根据网站的需求来做更加定制性质的产品。
架构演变第九步:数据读写分离和廉价存储方案
突然有一天,发现这个完美的时代也要结束了,数据库的噩梦又一次出现在眼前了,由于添加的webserver太多了,导致数据库连接的资源还是不够用,而这个时候又已经分库分表了,开始分析数据库的压力状况,可能会发现数据库的读写比很高,这个时候通常会想到数据读写分离的方案,当然,这个方案要实现并不 容易,另外,可能会发现一些数据存储在数据库上有些浪费,或者说过于占用数据库资源,因此在这个阶段可能会形成的架构演变是实现数据读写分离,同时编写一些更为廉价的存储方案,例如BigTable这种。
这一步涉及到了这些知识体系:
数据读写分离要求对数据库的复制、standby等策略有深入的掌握和理解,同时会要求具备自行实现的技术;
廉价存储方案要求对OS的文件存储有深入的掌握和理解,同时要求对采用的语言在文件这块的实现有深入的掌握。
架构演变第十步:进入大型分布式应用时代和廉价服务器群梦想时代
经过上面这个漫长而痛苦的过程,终于是再度迎来了完美的时代,不断的增加webserver就可以支撑越来越高的访问量了,对于大型网站而言,人气的重要毋庸置疑,随着人气的越来越高,各种各样的功能需求也开始爆发性的增长,这个时候突然发现,原来部署在webserver上的那个web应用已经非常庞大 了,当多个团队都开始对其进行改动时,可真是相当的不方便,复用性也相当糟糕,基本是每个团队都做了或多或少重复的事情,而且部署和维护也是相当的麻烦, 因为庞大的应用包在N台机器上复制、启动都需要耗费不少的时间,出问题的时候也不是很好查,另外一个更糟糕的状况是很有可能会出现某个应用上的bug就导 致了全站都不可用,还有其他的像调优不好操作(因为机器上部署的应用什么都要做,根本就无法进行针对性的调优)等因素,根据这样的分析,开始痛下决心,将 系统根据职责进行拆分,于是一个大型的分布式应用就诞生了,通常,这个步骤需要耗费相当长的时间,因为会碰到很多的挑战:
1、拆成分布式后需要提供一个高性能、稳定的通信框架,并且需要支持多种不同的通信和远程调用方式;
2、将一个庞大的应用拆分需要耗费很长的时间,需要进行业务的整理和系统依赖关系的控制等;
3、如何运维(依赖管理、运行状况管理、错误追踪、调优、监控和报警等)好这个庞大的分布式应用。
经过这一步,差不多系统的架构进入相对稳定的阶段,同时也能开始采用大量的廉价机器来支撑着巨大的访问量和数据量,结合这套架构以及这么多次演变过程吸取的经验来采用其他各种各样的方法来支撑着越来越高的访问量。
这一步涉及到了这些知识体系:
这一步涉及的知识体系非常的多,要求对通信、远程调用、消息机制等有深入的理解和掌握,要求的都是从理论、硬件级、操作系统级以及所采用的语言的实现都有清楚的理解。
运维这块涉及的知识体系也非常的多,多数情况下需要掌握分布式并行计算、报表、监控技术以及规则策略等等。
说起来确实不怎么费力,整个网站架构的经典演变过程都和上面比较的类似,当然,每步采取的方案,演变的步骤有可能有不同,另外,由于网站的业务不同,会有不同的专业技术的需求,这篇blog更多的是从架构的角度来讲解演变的过程,当然,其中还有很多的技术也未在此提及,像数据库集群、数据挖掘、搜索等,但在真实的演变过程中还会借助像提升硬件配置、网络环境、改造操作系统、CDN镜像等来支撑更大的流量,因此在真实的发展过程中还会有很多的不同,另外一个大型网站要做到的远远不仅仅上面这些,还有像安全、运维、运营、服务、存储等,要做好一个大型的网站真的很不容易。
前言:
我们知道以往资料要放到 M 台服务器上,最简单的方法就是取余数 (de>hash_value % Mde>) 然后放到对应的服务器上,那就是当添加或移除服务器时,缓存重组的代价相当巨大。 添加服务器后,余数就会产生巨变,这样就无法获取与保存时相同的服务器, 从而影响缓存的命中率。
下面这篇文章写的非常好,结合memcached的 特点利用Consistent hasning 算法,可以打造一个非常完备的分布式缓存服务器。
我是Mixi的长野。 本次不再介绍memcached的内部结构, 开始介绍memcached的分布式。
- memcached的分布式
- memcached的分布式是什么意思?
- Cache::Memcached的分布式方法
- 根据余数计算分散
- 根据余数计算分散的缺点
- Consistent Hashing
- Consistent Hashing的简单说明
- 支持Consistent Hashing的函数库
- 总结
memcached的分布式
正如第1次中介绍的那样, memcached虽然称为“分布式”缓存服务器,但服务器端并没有“分布式”功能。 服务器端仅包括 第2次、 第3次 前坂介绍的内存存储功能,其实现非常简单。 至于memcached的分布式,则是完全由客户端程序库实现的。 这种分布式是memcached的最大特点。
memcached的分布式是什么意思?
这里多次使用了“分布式”这个词,但并未做详细解释。 现在开始简单地介绍一下其原理,各个客户端的实现基本相同。
下面假设memcached服务器有node1~node3三台, 应用程序要保存键名为“tokyo”“kanagawa”“chiba”“saitama”“gunma” 的数据。
图1 分布式简介:准备
首先向memcached中添加“tokyo”。将“tokyo”传给客户端程序库后, 客户端实现的算法就会根据“键”来决定保存数据的memcached服务器。 服务器选定后,即命令它保存“tokyo”及其值。
图2 分布式简介:添加时
同样,“kanagawa”“chiba”“saitama”“gunma”都是先选择服务器再保存。
接下来获取保存的数据。获取时也要将要获取的键“tokyo”传递给函数库。 函数库通过与数据保存时相同的算法,根据“键”选择服务器。 使用的算法相同,就能选中与保存时相同的服务器,然后发送get命令。 只要数据没有因为某些原因被删除,就能获得保存的值。
图3 分布式简介:获取时
这样,将不同的键保存到不同的服务器上,就实现了memcached的分布式。 memcached服务器增多后,键就会分散,即使一台memcached服务器发生故障 无法连接,也不会影响其他的缓存,系统依然能继续运行。
接下来介绍第1次 中提到的Perl客户端函数库Cache::Memcached实现的分布式方法。
Cache::Memcached的分布式方法
Perl的memcached客户端函数库Cache::Memcached是 memcached的作者Brad Fitzpatrick的作品,可以说是原装的函数库了。
- Cache::Memcached - search.cpan.org
该函数库实现了分布式功能,是memcached标准的分布式方法。
根据余数计算分散
Cache::Memcached的分布式方法简单来说,就是“根据服务器台数的余数进行分散”。 求得键的整数哈希值,再除以服务器台数,根据其余数来选择服务器。
下面将Cache::Memcached简化成以下的Perl脚本来进行说明。
use warnings ;
use String::CRC32 ;
my @nodes = (’node1′,’node2′,’node3′);
my @keys = (’tokyo’, ‘kanagawa’, ‘chiba’, ’saitama’, ‘gunma’);
foreach my $key (@keys) {
my $crc = crc32($key); # CRC値
my $mod = $crc % ( $#nodes + 1 );
my $server = $nodes[ $mod ]; # 根据余数选择服务器
printf “%s => %s\n”, $key, $server;
}
Cache::Memcached在求哈希值时使用了CRC。
- String::CRC32 - search.cpan.org
首先求得字符串的CRC值,根据该值除以服务器节点数目得到的余数决定服务器。 上面的代码执行后输入以下结果:
tokyo => node2 kanagawa => node3 chiba => node2 saitama => node1 gunma => node1
根据该结果,“tokyo”分散到node2,“kanagawa”分散到node3等。 多说一句,当选择的服务器无法连接时,Cache::Memcached会将连接次数 添加到键之后,再次计算哈希值并尝试连接。这个动作称为rehash。 不希望rehash时可以在生成Cache::Memcached对象时指定“rehash => 0”选项。
根据余数计算分散的缺点
余数计算的方法简单,数据的分散性也相当优秀,但也有其缺点。 那就是当添加或移除服务器时,缓存重组的代价相当巨大。 添加服务器后,余数就会产生巨变,这样就无法获取与保存时相同的服务器, 从而影响缓存的命中率。用Perl写段代码来验证其代价。
use warnings ;
use String::CRC32 ;
my @nodes = @ARGV;
my @keys = (’a’..’z');
my %nodes;
foreach my $key ( @keys ) {
my $hash = crc32($key);
my $mod = $hash % ( $#nodes + 1 );
my $server = $nodes[ $mod ];
push @{ $nodes{ $server } }, $key;
}
foreach my $node ( sort keys %nodes ) {
printf “%s: %s\n”, $node, join “,”, @{ $nodes{$node} };
}
这段Perl脚本演示了将“a”到“z”的键保存到memcached并访问的情况。 将其保存为mod.pl并执行。
首先,当服务器只有三台时:
node1 : a , c , d , e , h , j , n , u , w , x
node2 : g , i , k , l , p , r , s , y
node3 : b , f , m , o ,q, t, v , z
结果如上,node1保存a、c、d、e……,node2保存g、i、k……, 每台服务器都保存了8个到10个数据。
接下来增加一台memcached服务器。
node1 : d , f , m , o , t , v
node2 : b , i , k , p , r , y
node3 : e , g , l , n , u , w
node4 : a , c , h , j ,q, s, x , z
添加了node4。可见,只有d、i、k、p、r、y命中了。像这样,添加节点后 键分散到的服务器会发生巨大变化。26个键中只有六个在访问原来的服务器, 其他的全都移到了其他服务器。命中率降低到23%。在Web应用程序中使用memcached时, 在添加memcached服务器的瞬间缓存效率会大幅度下降,负载会集中到数据库服务器上, 有可能会发生无法提供正常服务的情况。
mixi的Web应用程序运用中也有这个问题,导致无法添加memcached服务器。 但由于使用了新的分布式方法,现在可以轻而易举地添加memcached服务器了。 这种分布式方法称为 Consistent Hashing。
Consistent Hashing
关于Consistent Hashing的思想,mixi株式会社的开发blog等许多地方都介绍过, 这里只简单地说明一下。
- mixi Engineers’ Blog - スマートな分散で快適キャッシュライフ
- ConsistentHashing - コンシステント ハッシュ法
Consistent Hashing的简单说明
Consistent Hashing如下所示:首先求出memcached服务器(节点)的哈希值, 并将其配置到0~232的圆(continuum)上。 然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。 然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。 如果超过232仍然找不到服务器,就会保存到第一台memcached服务器上。
图4 Consistent Hashing:基本原理
从上图的状态中添加一台memcached服务器。余数分布式算法由于保存键的服务器会发生巨大变化 而影响缓存的命中率,但Consistent Hashing中,只有在continuum上增加服务器的地点逆时针方向的 第一台服务器上的键会受到影响。
图5 Consistent Hashing:添加服务器
因此,Consistent Hashing最大限度地抑制了键的重新分布。 而且,有的Consistent Hashing的实现方法还采用了虚拟节点的思想。 使用一般的hash函数的话,服务器的映射地点的分布非常不均匀。 因此,使用虚拟节点的思想,为每个物理节点(服务器) 在continuum上分配100~200个点。这样就能抑制分布不均匀, 最大限度地减小服务器增减时的缓存重新分布。
通过下文中介绍的使用Consistent Hashing算法的memcached客户端函数库进行测试的结果是, 由服务器台数(n)和增加的服务器台数(m)计算增加服务器后的命中率计算公式如下:
(1 - n/(n+m)) * 100
支持Consistent Hashing的函数库
本连载中多次介绍的Cache::Memcached虽然不支持Consistent Hashing, 但已有几个客户端函数库支持了这种新的分布式算法。 第一个支持Consistent Hashing和虚拟节点的memcached客户端函数库是 名为libketama的PHP库,由last.fm开发。
- libketama - a consistent hashing algo for memcache clients – RJ ブログ - Users at Last.fm
至于Perl客户端,连载的第1次 中介绍过的Cache::Memcached::Fast和Cache::Memcached::libmemcached支持 Consistent Hashing。
- Cache::Memcached::Fast - search.cpan.org
- Cache::Memcached::libmemcached - search.cpan.org
两者的接口都与Cache::Memcached几乎相同,如果正在使用Cache::Memcached, 那么就可以方便地替换过来。Cache::Memcached::Fast重新实现了libketama, 使用Consistent Hashing创建对象时可以指定ketama_points选项。
my $memcached = Cache::Memcached::Fast->new({ servers => ["192.168.0.1:11211","192.168.0.2:11211"], ketama_points => 150 });
另外,Cache::Memcached::libmemcached 是一个使用了Brain Aker开发的C函数库libmemcached的Perl模块。 libmemcached本身支持几种分布式算法,也支持Consistent Hashing, 其Perl绑定也支持Consistent Hashing。
- Tangent Software: libmemcached
总结
本次介绍了memcached的分布式算法,主要有memcached的分布式是由客户端函数库实现, 以及高效率地分散数据的Consistent Hashing算法。下次将介绍mixi在memcached应用方面的一些经验, 和相关的兼容应用程序。
FastDFS是一个开源的轻量级分布式文件系统,她对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、视频网站等等。
FastDFS服务端有两个角色:跟踪器(tracker)和存储节点(storage)。跟踪器主要做调度工作,在访问上起负载均衡的作用。
存储节点存储文件,完成文件管理的所有功能:存储、同步和提供存取接口,FastDFS同时对文件的metadata进行管理。所谓文件的meta data就是文件的相关属性,以键值对(key valuepair)方式表示,如:width=1024,其中的key为width,value为1024。文件metadata是文件属性列表,可以包含多个键值对。
FastDFS系统结构如下图所示:
跟踪器和存储节点都可以由一台多台服务器构成。跟踪器和存储节点中的服务器均可以随时增加或下线而不会影响线上服务。其中跟踪器中的所有服务器都是对等的,可以根据服务器的压力情况随时增加或减少。
为了支持大容量,存储节点(服务器)采用了分卷(或分组)的组织方式。存储系统由一个或多个卷组成,卷与卷之间的文件是相互独立的,所有卷的文件容量累加就是整个存储系统中的文件容量。一个卷可以由一台或多台存储服务器组成,一个卷下的存储服务器中的文件都是相同的,卷中的多台存储服务器起到了冗余备份和负载均衡的作用。
在卷中增加服务器时,同步已有的文件由系统自动完成,同步完成后,系统自动将新增服务器切换到线上提供服务。
当存储空间不足或即将耗尽时,可以动态添加卷。只需要增加一台或多台服务器,并将它们配置为一个新的卷,这样就扩大了存储系统的容量。
FastDFS中的文件标识分为两个部分:卷名和文件名,二者缺一不可。
FastDFS file upload
上传文件交互过程:
1. client询问tracker上传到的storage,不需要附加参数;
2. tracker返回一台可用的storage;
3. client直接和storage通讯完成文件上传。
FastDFS file download
下载文件交互过程:
1. client询问tracker下载文件的storage,参数为文件标识(卷名和文件名);
2. tracker返回一台可用的storage;
3. client直接和storage通讯完成文件下载。
需要说明的是,client为使用FastDFS服务的调用方,client也应该是一台服务器,它对tracker和storage的调用均为服务器间的调用。
google code地址:http://code.google.com/p/fastdfs/
google code下载地址:http://code.google.com/p/fastdfs/downloads/list
MogileFS一个开源的分布式文件系统
1.应用层——没有特殊的组件要求
2.无单点失败——MogileFS启动的三个组件(存储节点、跟踪器、跟踪用的数据库),均可运行在多个 机器上,因此没有单点失败。(你也可以将跟踪器和存储节点运行在同一台机器上,这样你就没有必要用4台机器)推荐至少两台机器。
3.自动的文件复制——文件是基于他们的“类”,文件可以自动的在多个存储节点上复制,这是为了尽量少的复制,才使用“类”的。加入你有的图片站点有 三份JPEG图片的拷贝,但实际只有1or2份拷贝,那么Mogile可以重新建立遗失的拷贝数。用这种办法,MogileFS(不做RAID)可以节约 在磁盘,否则你将存储同样的拷贝多份,完全没有必要。
4.“比RAID好多了”——在一个非存储区域网络的RAID(non-SAN RAID)的建立中,磁盘是冗余的,但主机不是,如果你整个机器坏了,那么文件也将不能访问。 MogileFS在不同的机器之间进行文件复制,因此文件始终是可用的。
5.传输中立,无特殊协议——MogileFS客户端可以通过NFS或HTTP来和MogileFS的存储节点来通信,但首先需要告知跟踪器一下。
6.简单的命名空间——文件通过一个给定的key来确定,是一个全局的命名空间。你可以自己生成多个命名空间,只要你愿意,但是这样可能在同一MogileFS中,会造成冲突key。
7.不用共享任何东西——MogileFS不需要依靠昂贵的SAN来共享磁盘,每个机器只用维护好自己的磁盘。
8.不需要RAID——在MogileFS中的磁盘可以是做了RAID的也可以是没有,如果是为了安全性着想的话RAID没有必要买了,因为MogileFS已经提供了。
9.不会碰到文件系统本身的不可知情况——在MogileFS中的存储节点的磁盘可以被格式化成多种格(ext3,reiserFS等等)。MogilesFS会做自己内部目录的哈希,所以它不会碰到文件系统本身的一些限制,比如一个目录中的最大文件数。你可以放心的使用。
FastFDS和MogileFS的对比
FastDFS设计时借鉴了MogileFS的一些思路。FastDFS是一个完善的分布式文件存储系统,通过客户端API对文件进行读写。可以说,MogileFS的所有功能特性FastDFS都具备,MogileFS网址:http://www.danga.com/mogilefs/。
另外,相对于MogileFS,FastDFS具有如下特点和优势:
1. FastDFS完善程度较高,不需要二次开发即可直接使用;
2. 和MogileFS相比,FastDFS裁减了跟踪用的数据库,只有两个角色:tracker和storage。FastDFS的架构既简化了系统,同时也消除了性能瓶颈;
3. 在系统中增加任何角色的服务器都很容易:增加tracker服务器时,只需要修改storage和client的配置文件(增加一行tracker配置);增加storage服务器时,通常不需要修改任何配置文件,系统会自动将该卷中已有文件复制到该服务器;
4. FastDFS比MogileFS更高效。表现在如下几个方面:
1)参见上面的第2点,FastDFS和MogileFS相比,没有文件索引数据库,FastDFS整体性能更高;
2)从采用的开发语言上看,FastDFS比MogileFS更底层、更高效。FastDFS用C语言编写,代码量不到2万行,没有依赖其他开源软件或程序包,安装和部署特别简洁;而MogileFS用perl编写;
3)FastDFS直接使用socket通信方式,相对于MogileFS的HTTP方式,效率更高。并且FastDFS使用sendfile传输文件,采用了内存零拷贝,系统开销更小,文件传输效率更高。
5. FastDFS有着详细的设计和使用文档,而MogileFS的文档相对比较缺乏。
6. FastDFS的日志记录非常详细,系统运行时发生的任何错误信息都会记录到日志文件中,当出现问题时方便管理员定位错误所在。
7. FastDFS还对文件附加属性(即meta data,如文件大小、图片宽度、高度等)进行存取,应用不需要使用数据库来存储这些信息。
8. FastDFS从V1.14开始支持相同文件内容只保存一份,这样可以节省存储空间,提高文件访问性能。
BinaryFormatter
Book类
using System;
using System.Collections;
using System.Text;
namespace SerializableTest
{
[Serializable]
public class Book
{
public Book()
{
alBookReader = new ArrayList();
}
public string strBookName;
[NonSerialized]
public string strBookPwd;
private string _bookID;
public string BookID
{
get { return _bookID; }
set { _bookID = value; }
}
public ArrayList alBookReader;
private string _bookPrice;
public void SetBookPrice(string price)
{
_bookPrice = price;
}
public void Write()
{
Console.WriteLine("Book ID:" + BookID);
Console.WriteLine("Book Name:" + strBookName);
Console.WriteLine("Book Password:" + strBookPwd);
Console.WriteLine("Book Price:" + _bookPrice);
Console.WriteLine("Book Reader:");
for (int i = 0; i < alBookReader.Count; i++)
{
Console.WriteLine(alBookReader[i]);
}
}
}
}
这个类比较简单,就是定义了一些public字段和一个可读写的属性,一个private字段,一个标记为[NonSerialized]的字段,具体会在下面的例子中体现出来
一、BinaryFormatter序列化方式
1、序列化,就是给Book类赋值,然后进行序列化到一个文件中
Book book = new Book();
book.BookID = "1";
book.alBookReader.Add("gspring");
book.alBookReader.Add("永春");
book.strBookName = "C#强化";
book.strBookPwd = "*****";
book.SetBookPrice("50.00");
BinarySerialize serialize = new BinarySerialize();
serialize.Serialize(book);2、反序列化
BinarySerialize serialize = new BinarySerialize();
Book book = serialize.DeSerialize();
book.Write();3、测试用的
BinarySerialize类
using System;
using System.Collections.Generic;
using System.Text;
using System.IO;
using System.Runtime.Serialization.Formatters.Binary;
namespace SerializableTest
{
public class BinarySerialize
{
string strFile = "c:\\book.data";
public void Serialize(Book book)
{
using (FileStream fs = new FileStream(strFile, FileMode.Create))
{
BinaryFormatter formatter = new BinaryFormatter();
formatter.Serialize(fs, book);
}
}
public Book DeSerialize()
{
Book book;
using (FileStream fs = new FileStream(strFile, FileMode.Open))
{
BinaryFormatter formatter = new BinaryFormatter();
book = (Book)formatter.Deserialize(fs);
}
return book;
}
}
}
主要就是调用System.Runtime.Serialization.Formatters.Binary空间下的BinaryFormatter类进行序列化和反序列化,以缩略型二进制格式写到一个文件中去,速度比较快,而且写入后的文件已二进制保存有一定的保密效果。
调用反序列化后的截图如下:
也就是说除了标记为NonSerialized的其他所有成员都能序列化
二、SoapFormatter序列化方式
调用序列化和反序列化的方法和上面比较类似,我就不列出来了,主要就看看SoapSerialize类
SoapSerialize类
using System;
using System.Collections.Generic;
using System.Text;
using System.IO;
using System.Runtime.Serialization.Formatters.Soap;
namespace SerializableTest
{
public class SoapSerialize
{
string strFile = "c:\\book.soap";
public void Serialize(Book book)
{
using (FileStream fs = new FileStream(strFile, FileMode.Create))
{
SoapFormatter formatter = new SoapFormatter();
formatter.Serialize(fs, book);
}
}
public Book DeSerialize()
{
Book book;
using (FileStream fs = new FileStream(strFile, FileMode.Open))
{
SoapFormatter formatter = new SoapFormatter();
book = (Book)formatter.Deserialize(fs);
}
return book;
}
}
}
主要就是调用System.Runtime.Serialization.Formatters.Soap空间下的SoapFormatter类进行序列化和反序列化,使用之前需要应用System.Runtime.Serialization.Formatters.Soap.dll(.net自带的)
序列化之后的文件是Soap格式的文件(简单对象访问协议(Simple Object Access Protocol,SOAP),是一种轻量的、简单的、基于XML的协议,它被设计成在WEB上交换结构化的和固化的信息。 SOAP 可以和现存的许多因特网协议和格式结合使用,包括超文本传输协议(HTTP),简单邮件传输协议(SMTP),多用途网际邮件扩充协议(MIME)。它还支持从消息系统到远程过程调用(RPC)等大量的应用程序。SOAP使用基于XML的数据结构和超文本传输协议(HTTP)的组合定义了一个标准的方法来使用Internet上各种不同操作环境中的分布式对象。)
调用反序列化之后的结果和方法一相同
XML序列化方式
调用序列化和反序列化的方法和上面比较类似,我就不列出来了,主要就看看XmlSerialize类
XmlSerialize类
using System;
using System.Collections.Generic;
using System.Text;
using System.IO;
using System.Xml.Serialization;
namespace SerializableTest
{
public class XmlSerialize
{
string strFile = "c:\\book.xml";
public void Serialize(Book book)
{
using (FileStream fs = new FileStream(strFile, FileMode.Create))
{
XmlSerializer formatter = new XmlSerializer(typeof(Book));
formatter.Serialize(fs, book);
}
}
public Book DeSerialize()
{
Book book;
using (FileStream fs = new FileStream(strFile, FileMode.Open))
{
XmlSerializer formatter = new XmlSerializer(typeof(Book));
book = (Book)formatter.Deserialize(fs);
}
return book;
}
}
}
从这三个测试类我们可以看出来其实三种方法的调用方式都差不多,只是具体使用的类不同
xml序列化之后的文件就是一般的一个xml文件:
book.xml
< ?xml version="1.0"?>
< Book xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
< strBookName>C#强化</strBookName>
< strBookPwd>*****</strBookPwd>
< alBookReader>
<anyType xsi:type="xsd:string">gspring</anyType>
<anyType xsi:type="xsd:string">永春</anyType>
< /alBookReader>
< BookID>1</BookID>
< /Book>输出截图如下:
也就是说采用xml序列化的方式只能保存public的字段和可读写的属性,对于private等类型的字段不能进行序列化
关于循环引用:
比如在上面的例子Book类中加入如下一个属性:
public Book relationBook;
在调用序列化时使用如下方法:
Book book = new Book();
book.BookID = "1";
book.alBookReader.Add("gspring");
book.alBookReader.Add("永春");
book.strBookName = "C#强化";
book.strBookPwd = "*****";
book.SetBookPrice("50.00");
Book book2 = new Book();
book2.BookID = "2";
book2.alBookReader.Add("gspring");
book2.alBookReader.Add("永春");
book2.strBookName = ".NET强化";
book2.strBookPwd = "*****";
book2.SetBookPrice("40.00");
book.relationBook = book2;
book2.relationBook = book;
BinarySerialize serialize = new BinarySerialize();
serialize.Serialize(book);这样就会出现循环引用的情况,对于BinarySerialize和SoapSerialize可以正常序列化(.NET内部进行处理了),对于XmlSerialize出现这种情况会报错:"序列化类型 SerializableTest.Book 的对象时检测到循环引用。"
# cd libevent-1.1a
# ./configure --prefix=/usr
# make
# make install
# cd ..
# tar -xzf memcached-1.1.12.tar.gz
# cd memcached-1.1.12
# ./configure --prefix=/usr
# make
# make install
-m 设置 memcached 可以使用的内存大小,单位为 M;
-l 设置监听的 IP 地址,如果是本机的话,通常可以不设置此参数;
-p 设置监听的端口,默认为 11211,所以也可以不设置此参数;
-u 指定用户,如果当前为 root 的话,需要使用此参数指定用户。
往 memcached 中写入对象,$key 是对象的唯一标识符,$val 是写入的对象数据,$exp 为过期时间,单位为秒,默认为不限时间;
从 memcached 中获取对象数据,通过对象的唯一标识符 $key 获取;
使用 $value 替换 memcached 中标识符为 $key 的对象内容,参数与 add() 方法一样,只有 $key 对象存在的情况下才会起作用;
删除 memcached 中标识符为 $key 的对象,$time 为可选参数,表示删除之前需要等待多长时间。
// 包含 memcached 类文件
require_on ce('memcached-client.php');
// 选项设置
$options = array(
'servers' => array('192.168.1.1:11211'), //memcached 服务的地址、端口,可用多个数组元素表示多个 memcached 服务
'debug' => true, //是否打开 debug
'compress_threshold' => 10240, //超过多少字节的数据时进行压缩
'persistant' => false //是否使用持久连接
);
// 创建 memcached 对象实例
$mc = new memcached($options);
// 设置此脚本使用的唯一标识符
$key = 'mykey';
// 往 memcached 中写入对象
$mc->add($key, 'some random strings');
$val = $mc->get($key);
echo "n".str_pad('$mc->add() ', 60, '_')."n";
var_dump($val);
// 替换已写入的对象数据值
$mc->replace($key, array('some'=>'haha', 'array'=>'xxx'));
$val = $mc->get($key);
echo "n".str_pad('$mc->replace() ', 60, '_')."n";
var_dump($val);
// 删除 memcached 中的对象
$mc->delete($key);
$val = $mc->get($key);
echo "n".str_pad('$mc->delete() ', 60, '_')."n";
var_dump($val);
?>
$sql = 'SELECT * FROM users';
$key = md5($sql); //memcached 对象标识符
{
// 在 memcached 中未获取到缓存数据,则使用数据库查询获取记录集。
echo "n".str_pad('Read datas from MySQL.', 60, '_')."n";
$conn = mysql_connect('localhost', 'test', 'test');
mysql_select_db('test');
$result = mysql_query($sql);
while ($row = mysql_fetch_object($result))
$datas[] = $row;
// 将数据库中获取到的结果集数据保存到 memcached 中,以供下次访问时使用。
$mc->add($key, $datas);
{
echo "n".str_pad('Read datas from memcached.', 60, '_')."n";
}
var_dump($datas);
?>
用 Collection / Object 时经常想用一个物件(Object)去生成另一个物件并保留原有数据(如 DataTable.Copy()),最没头没脑的做法是:
view plaincopy to clipboardprint?
public MyObject Copy()
{
MyObject oNewObject = new MyObject();
oNewObject.Value1 = this.Value1;
oNewObject.Value2 = this.Value2;
oNewObject.Value3 = this.Value3;
return oNewObject;
}
public bool Compare(MyObject oNewObject)
{
return (oNewObject.Value1 == this.Value1
&& oNewObject.Value2 == this.Value2
&& oNewObject.Value3 == this.Value3);
}
public MyObject Copy()
{
MyObject oNewObject = new MyObject();
oNewObject.Value1 = this.Value1;
oNewObject.Value2 = this.Value2;
oNewObject.Value3 = this.Value3;
return oNewObject;
}
public bool Compare(MyObject oNewObject)
{
return (oNewObject.Value1 == this.Value1
&& oNewObject.Value2 == this.Value2
&& oNewObject.Value3 == this.Value3);
}
如果每个物件(Object )只有十多个属性(Properties)的话这样只是小菜一碟,但当你有数十个物件...每个物件有数十个属性的话,那就有够脑残了...
以下是用Reflection的PropertyInfo去提取物件属性的例子:
view plaincopy to clipboardprint?
using System.Reflection;
.
.
.
for(int i = 0; i < oOldObject.GetType().GetProperties().Length; i ++)
{
//根据索引提取个别属性
PropertyInfo oOldObjectProperty = (PropertyInfo) oOldObject.GetType().GetProperties().GetValue(i);
//得到该属性的数据
Object oOldObjectValue = oOldObjectProperty.GetValue(oOldObject, null);
if (oOldObjectProperty.CanRead)
{
Console.WriteLine(oOldObjectProperty.Name + " = " + oOldObjectValue.ToString());
}
}
using System.Reflection;
.
.
.
for(int i = 0; i < oOldObject.GetType().GetProperties().Length; i ++)
{
//根据索引提取个别属性
PropertyInfo oOldObjectProperty = (PropertyInfo) oOldObject.GetType().GetProperties().GetValue(i);
//得到该属性的数据
Object oOldObjectValue = oOldObjectProperty.GetValue(oOldObject, null);
if (oOldObjectProperty.CanRead)
{
Console.WriteLine(oOldObjectProperty.Name + " = " + oOldObjectValue.ToString());
}
}
如此便能列出物件中的所有属性,用同样的方法应该就能轻松复制/比较两个物件了:
view plaincopy to clipboardprint?
using System.Reflection;
.
.
.
public MyObject Copy()
{
MyObject oNewObject = new MyObject();
for(int i = 0; i < this.GetType().GetProperties().Length; i ++)
{
PropertyInfo oOldObjectProperty = (PropertyInfo) this.GetType().GetProperties().GetValue(i);
Object oOldObjectValue = oOldObjectProperty.GetValue(this, null);
PropertyInfo oNewObjectProperty = (PropertyInfo) oNewObject.GetType().GetProperties().GetValue(i);
if (oOldObjectProperty.CanRead)
{
//设定oNewObject的当前属性的值为oOldObjectValue(数据类型必须(必定)一致)
oNewObjectProperty.SetValue(oNewObject, oOldObjectValue, null);
}
}
return oNewObject;
}
public bool Compare(MyObject oNewObject)
{
bool bResult = true;
for(int i = 0; i < this.GetType().GetProperties().Length; i ++)
{
PropertyInfo oOldObjectProperty = (PropertyInfo) this.GetType().GetProperties().GetValue(i);
Object oOldObjectValue = oOldObjectProperty.GetValue(this, null);
PropertyInfo oNewObjectProperty = (PropertyInfo) oNewObject.GetType().GetProperties().GetValue(i);
Object oNewObjectValue = oNewObjectProperty.GetValue(oNewObject, null);
//防止属性是NULL
if (oOldObjectValue != null && oNewObjectValue != null)
{
switch(oOldObjectProperty.PropertyType.ToString())
{
case "System.Double":
//Double 会有机会变成如2.49999999...的无限小数, 变成String才准确
bResult = (((double)oOldObjectValue).ToString("0.000000") == ((double)oNewObjectValue).ToString("0.000000"));
break;
case "System.DateTime":
//量度到秒就够了
bResult = (((DateTime)oOldObjectValue).ToString("yyyy/MM/dd HH:mm:ss") == ((DateTime)oNewObjectValue).ToString("yyyy/MM/dd HH:mm:ss"));
break;
case "System.Boolean":
bResult = (((bool)oOldObjectValue) == ((bool)oNewObjectValue));
break;
default:
bResult = (oOldObjectValue.ToString() == oNewObjectValue.ToString());
break;
}
}
else
{
//验证个别属性是NULL
if (!(oOldObjectValue == null && oOldObjectValue == null))
{
bResult = false;
}
}
//如发现有不同就不用再比对了
if (!bResult)
{
break;
}
}
return bResult;
}
1.NameValueCollection类集合是基于 NameObjectCollectionBase 类。
但与 NameObjectCollectionBase 不同,该类在一个键下存储多个字符串值(就是键相同,值就连接起来如下例子)。该类可用于标头、查询字符串和窗体数据。
每个元素都是一个键/值对。NameValueCollection 的容量是 NameValueCollection 可以保存的元素数。
NameValueCollection 的默认初始容量为零。随着向 NameValueCollection 中添加元素,容量通过重新分配按需自动增加。
如下例子:
NameValueCollection myCol = new NameValueCollection();
myCol.Add("red", "rojo");//如果键值red相同结果合并 rojo,rouge
myCol.Add("green", "verde");
myCol.Add("blue", "azul");
myCol.Add("red", "rouge");
2.NameValueCollection与Hashtable的区别
a.引用区别
hashtable:using System.Collections;
NameValueCollection:using System.Collections.Specialized;
b.键是否重复
NameValueCollection:允许重复.
HashTable是键-值集合,但键不能出现重复.
Hashtable ht = new Hashtable();
ht.Add("key","value");
ht.Add("key", "value1"); //出错
ht["key"] = "value1"; //正确
3.初始化NameValueCollection
初始化NameValueCollection需引用using System.Collections.Specialized;
完整例子源码:
using System; using System.Collections;
using System.Collections.Specialized;
namespace SamplesNameValueCollection
{
class Program
{
public static void Main()
{
//初始化NameValueCollection需引用using System.Collections.Specialized;
NameValueCollection myCol = new NameValueCollection();
myCol.Add("red", "rojo");//如果键值red相同结果合并 rojo,rouge
myCol.Add("green", "verde");
myCol.Add("blue", "azul");
myCol.Add("red", "rouge");
// Displays the values in the NameValueCollection in two different ways.
//显示键,值
Console.WriteLine("Displays the elements using the AllKeys property and the Item (indexer) property:");
PrintKeysAndValues(myCol);
Console.WriteLine("Displays the elements using GetKey and Get:");
PrintKeysAndValues2(myCol);
// Gets a value either by index or by key.
//按索引或值获取
Console.WriteLine("Index 1 contains the value {0}.", myCol[1]);//索引1的值
Console.WriteLine("Key \"red\" has the value {0}.", myCol["red"]);//键为red的对应值rouge
Console.WriteLine();
// Copies the values to a string array and displays the string array.
String[] myStrArr = new String[myCol.Count];
myCol.CopyTo(myStrArr, 0);
Console.WriteLine("The string array contains:");
foreach (String s in myStrArr)
Console.WriteLine(" {0}", s);
Console.WriteLine();
//查找green键值然后删除
myCol.Remove("green");
Console.WriteLine("The collection contains the following elements after removing \"green\":");
PrintKeysAndValues(myCol);
//清空集合
myCol.Clear();
Console.WriteLine("The collection contains the following elements after it is cleared:");
PrintKeysAndValues(myCol);
}
//显示键,值
public static void PrintKeysAndValues(NameValueCollection myCol)
{
IEnumerator myEnumerator = myCol.GetEnumerator();
Console.WriteLine(" KEY VALUE");
foreach (String s in myCol.AllKeys)
Console.WriteLine(" {0,-10} {1}", s, myCol[s]);
Console.WriteLine();
}
//显示索引, 键,值
public static void PrintKeysAndValues2(NameValueCollection myCol)
{
Console.WriteLine(" [INDEX] KEY VALUE");
for (int i = 0; i < myCol.Count; i++)
Console.WriteLine(" [{0}] {1,-10} {2}", i, myCol.GetKey(i), myCol.Get(i));
Console.WriteLine();
}
}
}
4.NameValueCollection遍历
与Hashtable相似:
NameValueCollection myCol = new NameValueCollection();
myCol.Add("red", "rojo");//如果键值red相同结果合并 rojo,rouge
myCol.Add("green", "verde");
myCol.Add("blue", "azul");
myCol["red"] = "dd";
foreach (string key in myCol.Keys)
{
Console.WriteLine("{0}:{1}", key, myCol[key]);
}
Console.ReadLine();