孤立词语音识别之MFCC特征提取
倒谱(cepstrum)就是一种信号的傅里叶变换经对数运算后再进行傅里叶反变换得到的谱。它的计算过程如下:


Mel频率分析就是基于人类听觉感知实验的。实验观测发现人耳就像一个滤波器组一样,它只关注某些特定的频率分量(人的听觉对频率是有选择性的)。也就说,它只让某些频率的信号通过,而压根就直接无视它不想感知的某些频率信号。但是这些滤波器在频率坐标轴上却不是统一分布的,在低频区域有很多的滤波器,他们分布比较密集,但在高频区域,滤波器的数目就变得比较少,分布很稀疏。梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient, MFCC)考虑到了人类的听觉特征,先将线性频谱映射到基于听觉感知的Mel非线性频谱中,然后转换到倒谱上。将普通频率转化到Mel频率的公式是:
![]()

下面简单的介绍一下求解MFCC的过程。
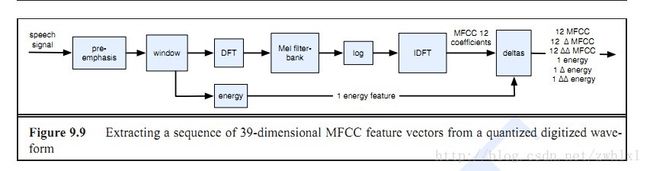
1. 预强调(Pre-emphasis):
将语音讯号 x(n) 通过一个高通滤波器。
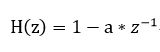
这个滤波器有+6dB/oct高频增强的特性。语音信号通过这个高通滤波器的结果,会得到
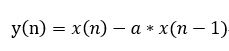
其中系数a 介于 0.9 和 1.0 之间。
这个目的就是为了消除发声过程中声带和嘴唇的效应,来补偿语音信号受到发音系统所压抑的高频部分。(另一种说法则是要突显在高频的共振峰。)我们听到的声音,其实是类似经过一个低通滤波器,信号做了-6dB/oct的高频衰减,故语音信号的的高频成分被压抑了。加一个高频增强为6dB/oct的高通滤波器,就可以补偿这个高频衰减。

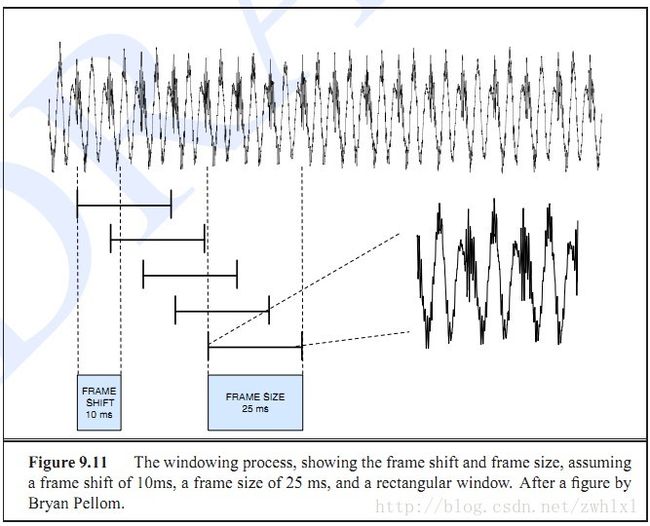
2.音框化(Frame blocking):
先将 N 个取样点集合成一个观测单位,称为音框(Frame),通常 N 的值是 256 或 512,涵盖的时间约为 20~30 ms 左右。为了避免相邻两音框的变化过大,所以我们会让两相邻因框之间有一段重迭区域,此重迭区域包含了 M 个取样点,通常 M 的值约是 N 的一半或 1/3。通常语音辨识所用的音讯的取样频率为 8 KHz或 16 KHz,以 8 KHz 来说,若音框长度为 256 个取样点,则对应的时间长度是256/8000*1000 = 32 ms。
就是前后两帧的重叠量,即前一帧尾部与后一帧头部的重叠量,一般默认为一半。至于什么要有帧移呢?答:帧移后的每一帧信号都有上一帧的成分,防止两帧之间的不连续。语音信号虽然短时可以认为平稳,但是由于人说话并不是间断的,每帧之间都是相关的,加上帧移可以更好地与实际的语音相接近。
3.汉明窗(Hammingwindow):
将每一个音框(frame)乘上汉明窗,以增加音框左端和右端的连续性(请见下一个步骤的说明)。假设音框化的讯号为 x(n),n = 0,…N-1。N为frame的大小,那么乘上汉明窗后为 x'(n) = x(n)*w(n),此 w(n)形式如下:

为什么加(汉明窗) 加窗的目的就是想窗内的信号的两边缓慢减小,在边界上不造成明显的不连续现象。
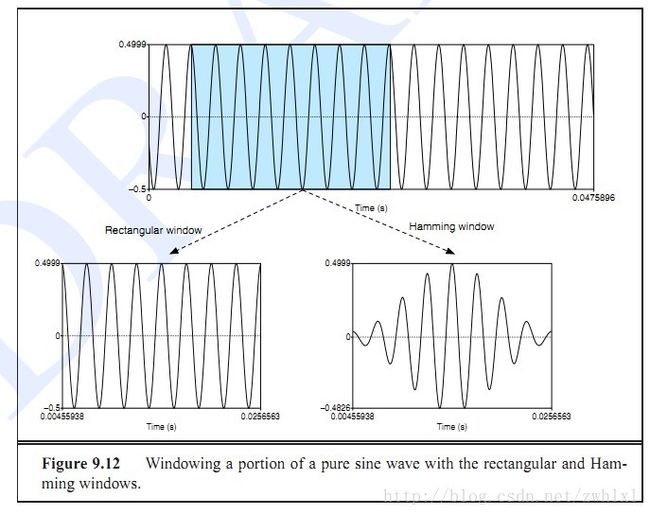
4.快速傅利叶转换(FastFourier Transform, or FFT):
由于讯号在时域(Time domain)上的变化通常很难看出讯号的特性,所以通常将它转换成频域(Frequency domain)上的能量分布来观察,不同的能量分布,就能代表不同语音的特性。所以在乘上汉明窗后,每个音框还必需再经过 FFT 以得到在频谱上的能量分布。
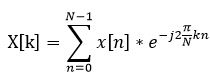
5.三角带通滤波器(TriangularBandpass Filters):
人耳在频域的感知,并非是全频域有相同的敏感度。正常情况下对低频有较高的敏感度,也就是说在低频时可以分辨较小的频率差异。在1kHz以下的临界频带宽度约为100hz,1kHz以上的临界频带宽度成指数增加。配合人耳听觉特性,在频域中以梅尔量度划分频带,将属于一个频带的频率成分,合在一起看成一个能量强度,然后将这些频带强度,再经过离散余弦变换DCT,转换成倒频谱,这就是梅尔频率倒频谱(Mel-frequency cepstrum)。
设计一组梅尔频率的带通滤波器组—三角带通滤波器组
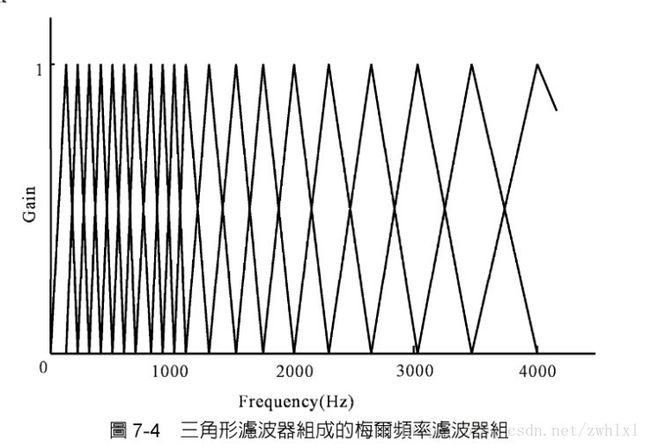
三角带通滤波器组的中心频率 1kHz以下为等间隔,1kHz以上为对数间隔,如果在4kHz范围内设计20个频带,其中心频率可设定为:100 200 300 400 500 600 700 800 900 1000 11481318 1514 1737 1995 2291 2630 3020 3467 4000hz 数学式表示第m个滤波器组的函数式为
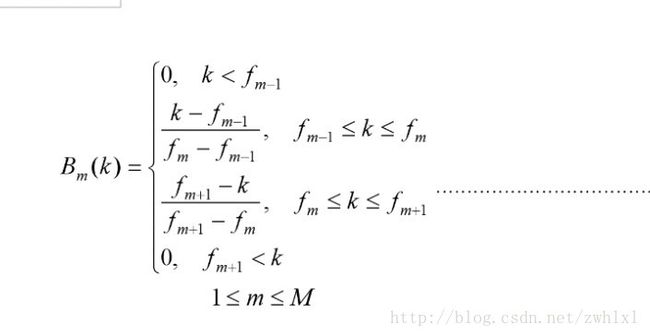
Bm(k)表示第m个频带的三角滤波器,fm是第m个频带的中心频率,M是频带总数。
将各频率的能量乘上上述的三角滤波器,然后累加起来,就是通过这个滤波器的能量,取对数值得到:

三角带通滤波器有两个主要目的:
对频谱进行平滑化,并消除谐波的作用,突显原先语音的共振峰。(因此一段语音的音调或音高,是不会呈现在 MFCC 参数内,换句话说,以 MFCC 为特征的语音辨识系统,并不会受到输入语音的音调不同而有所影响。) 降低资料量。
为了避免频率越高的滤波器宽度越大,造成高频带的能量被放大,有一种设计是让三角形的高度随着宽度增加而减小,维持三角形的面积不变,这是正则化的梅尔频率滤波器组。滤波器三角形的高度估算如下,
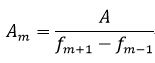
下图是正则化的三角形滤波器,这里A=200

6.离散余弦转换(Discretecosine transform, or DCT):

对全部M个滤波器输出的对数能量做DCT,求出 L 阶的 Mel- scale Cepstrum 参数,这里 L 通常取 12。转换公式如下
![]()
就是信号x(n)的梅尔频率倒谱系数。其中 Y(m) 是由前一个步骤所算出来的三角滤波器和频谱能量的内积值,这里M 是三角滤波器的个数。由于之前作了 FFT,所以采用 DCT 转换是期望能转回类似Time Domain 的情况来看,又称 Quefrency Domain,其实也就是 Cepstrum(倒谱)。又因为之前采用Mel- Frequency 来转换至梅尔频率,所以才称之Mel-scale Cepstrum。
7.对数能量(Logenergy):
一个音框的音量(即能量),也是语音的重要特征,而且非常容易计算。因此我们通常再加上一个音框的对数能量(定义为一个音框内讯号的平方和,再取以 10 为底的对数值,再乘以10),使得每一个音框基本的语音特征就有 13 维,包含了 1 个对数能量和 12 个倒频谱参数。(若要加入其它语音特征以测试辨识率,也可以在此阶段加入,这些常用的其它语音特征,包含音高、过零率、共振峰等。)
8.差量倒频谱参数(Deltacepstrum):
虽然已经求出 13 个特征参数,然而在实际应用于语音辨识时,我们通常会再加上差量倒频谱参数,以显示倒频谱参数对时间的变化。它的意义为倒频谱参数相对于时间的斜率,也就是代表倒频谱参数在时间上的动态变化,公式如下
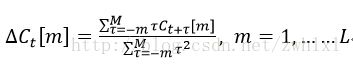
其中
![]() 为第t+tao个语音帧所求得的倒频谱系数,这里 M 的值一般是取 2 或 3。因此,如果加上差量运算,就会产生 26 维的特征向量;如果再加上差量运算,就会产生 39 维的特征向量。一般我们在 PC 上进行的语音辨识,就是使用39 维的特征向量。
为第t+tao个语音帧所求得的倒频谱系数,这里 M 的值一般是取 2 或 3。因此,如果加上差量运算,就会产生 26 维的特征向量;如果再加上差量运算,就会产生 39 维的特征向量。一般我们在 PC 上进行的语音辨识,就是使用39 维的特征向量。

9.参考文献
1、http://mirlab.org/jang/books/audiosignalprocessing/speechFeatureMfcc_chinese.asp?title=12-2%20MFCC Audio Signal Processing and Recognition (音訊處理與辨識)
2、http://blog.csdn.net/zouxy09/article/details/9156785语音信号处理之(四)梅尔频率倒谱系数(MFCC)
3、SPEECH and LANGUAGE PROCESSING An Introduction to Natural Language Processing, ComputationalLinguistics, and Speech Recognition Second Edition by Daniel Jurafsky and James H. Martin
4、語音訊號處理 王小川