Apache Mahout算法集及源码目录说明
Apache Mahout 是 ApacheSoftware Foundation (ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序,并且,在 Mahout 的最近版本中还加入了对Apache Hadoop 的支持,使这些算法可以更高效的运行在云计算环境中。
https://cwiki.apache.org/confluence/display/MAHOUT/Algorithms
网页右面显示的有机器学习的各种算法,包括三大块聚类、协同过滤、分类等算法
在Mahout实现的机器学习算法见下表:
| 算法类 |
算法名 |
中文名 |
| 分类算法 |
Logistic Regression |
逻辑回归 |
| Bayesian |
贝叶斯 |
|
| Support Vector Machines |
支持向量机 |
|
| Perceptron and Winnow |
感知器算法 |
|
| Neural Network |
神经网络 |
|
| Random Forests |
随机森林 |
|
| Restricted Boltzmann Machines |
有限波尔兹曼机 |
|
| 聚类算法 |
Canopy Clustering |
Canopy聚类 |
| K-Means Clustering |
K均值算法 |
|
| Fuzzy K-Means |
模糊K均值 |
|
| Expectation Maximization |
EM聚类(期望最大化聚类) |
|
| Mean Shift Clustering |
均值漂移聚类 |
|
| Hierarchical Clustering |
层次聚类 |
|
| Dirichlet Process Clustering |
狄里克雷过程聚类 |
|
| Latent Dirichlet Allocation |
LDA聚类 |
|
| Spectral Clustering Minhash Clustering Top Down Clustering |
谱聚类
|
|
| 关联规则挖掘 |
Parallel FP Growth Algorithm |
并行FP Growth算法 |
| 回归 |
Locally Weighted Linear Regression |
局部加权线性回归 |
| 降维/维约简 |
Stochastic Singular ValueDecomposition |
奇异值分解 |
| Principal Components Analysis |
主成分分析 |
|
| Independent Component Analysis |
独立成分分析 |
|
| Gaussian Discriminative Analysis |
高斯判别分析 |
|
| 进化算法 |
并行化了Watchmaker框架 |
|
| 推荐/协同过滤 |
Non-distributed recommenders |
Taste(UserCF, ItemCF, SlopeOne) |
| Distributed Recommenders |
ItemCF |
|
| 向量相似度计算 |
RowSimilarityJob |
计算列间相似度 |
| VectorDistanceJob |
计算向量间距离 |
|
| 非Map-Reduce算法 |
Hidden Markov Models |
隐马尔科夫模型 |
| 集合方法扩展 |
Collocations |
扩展了java的Collections类 |
RecommenderDocumentation
Dimensional Reduction
Parallel Frequent PatternMining
Boosting
Collaborative Filtering with ALS-WR
Itembased Collaborative Filtering
Machine Learning Resources
Online Passive Aggressive
Online Viterbi
Parallel Viterbi
Recommender First-Timer FAQ
Mahout最大的优点就是基于hadoop实现,把很多以前运行于单机上的算法,转化为了MapReduce模式,这样大大提升了算法可处理的数据量和处理性能。
Mahout下个性化推荐引擎Taste介绍
Taste是 Apache Mahout 提供的一个个性化推荐引擎的高效实现,该引擎基于java实现,可扩展性强,同时在mahout中对一些推荐算法进行了MapReduce编程模式转化,从而可以利用hadoop的分布式架构,提高推荐算法的性能。
在Mahout0.5版本中的Taste, 实现了多种推荐算法,其中有最基本的基于用户的和基于内容的推荐算法,也有比较高效的SlopeOne算法,以及处于研究阶段的基于SVD和线性插值的算法,同时Taste还提供了扩展接口,用于定制化开发基于内容或基于模型的个性化推荐算法。
Taste 不仅仅适用于 Java 应用程序,还可以作为内部服务器的一个组件以 HTTP 和 Web Service 的形式向外界提供推荐的逻辑。Taste 的设计使它能满足企业对推荐引擎在性能、灵活性和可扩展性等方面的要求。
下图展示了构成Taste的核心组件:
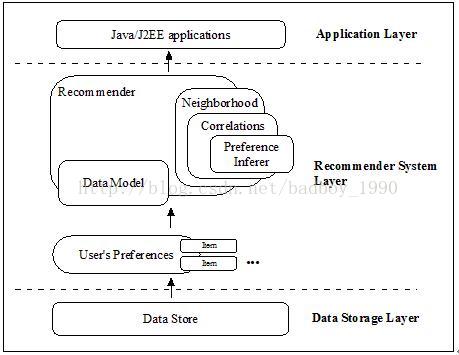
从上图可见,Taste由以下几个主要组件组成:
DataModel:DataModel是用户喜好信息的抽象接口,它的具体实现支持从指定类型的数据源抽取用户喜好信息。在Mahout0.5中,Taste 提供JDBCDataModel 和 FileDataModel两种类的实现,分别支持从数据库和文件文件系统中读取用户的喜好信息。对于数据库的读取支持,在Mahout 0.5中只提供了对MySQL和PostgreSQL的支持,如果数据存储在其他数据库,或者是把数据导入到这两个数据库中,或者是自行编程实现相应的类。
UserSimilarit和ItemSimilarity:前者用于定义两个用户间的相似度,后者用于定义两个项目之间的相似度。Mahout支持大部分驻留的相似度或相关度计算方法,针对不同的数据源,需要合理选择相似度计算方法。
UserNeighborhood:在基于用户的推荐方法中,推荐的内容是基于找到与当前用户喜好相似的“邻居用户”的方式产生的,该组件就是用来定义与目标用户相邻的“邻居用户”。所以,该组件只有在基于用户的推荐算法中才会被使用。
Recommender:Recommender是推荐引擎的抽象接口,Taste 中的核心组件。利用该组件就可以为指定用户生成项目推荐列表。