[Linux]常用Linux命令小结(持续更新中)
-
- pbcopy命令
- cat命令
- locate命令
- find命令
- grep命令
- tar命令
- sed命令
- 关机命令
- awk编程
- 记录和域的概念
- 常用使用
对于ls,cd等太过于基础的命令,本文不将进行介绍。
pbcopy命令
复制到粘贴板中。
在进行SSH的时候,需要拷贝公钥,这里Linux有个命令,大家可以试试,
pbcopy < ~/.ssh/id_rsa.pub
该命令也同样适用于拷贝文件。
cat命令
主要有三大功能:
1.一次显示整个文件。 catfilename2.从键盘创建一个文件。 cat > filename
只能创建新文件,不能编辑已有文件.
3.将几个文件合并为一个文件: $cat file1 file2 > file
可参考cat参考资料。
通过命令
ls -l | cat >file可以将ls -l的结果存到文件file中。
Q:cat命令和more命令的区别是什么?
(1)cat作用是:连接并显示一个或多个文件的有关信息
使用方式:cat 文件
-n:由第1行开始对所有输出的行号编号
-b:和-n一样不过对于空白行不编号
(2)more作用是:类似cat,不过会以一页一页的显示方便使用者一页页阅读
使用方法:more 文件名
例子:more -s testfile 逐页显示testfile内容,有连续两行以上空白行则以一行空白行显示
more +30 testfile 从第30行开始显示testfile内容
拷贝文件当然也可以用cp file1 file2。更改文件名可以用mv file1 file2。
locate命令
locate命令用于查找文件,它比find命令的搜索速度快,它需要一个数据库,这个数据库由每天的例行工作(crontab)程序来建立。当我们建立好这个数据库后,就可以方便地来搜寻所需文件了。
即先运行:updatedb(无论在那个目录中均可,可以放在crontab中 )后在 /var/lib/slocate/ 下生成 slocate.db 数据库即可快速查找。在命令提示符下直接执行#updatedb 命令即可:
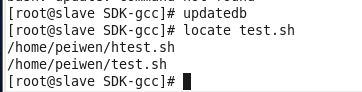
有些同学可能会碰到这样的问题:
updatedb: can not open a temporary file for `/var/lib/mlocate/mlocate.db’
解决方法:用root权限,su一下即可。
find命令
find和locate命令的一大区别是,find是实时查找,locate并非实时查找,因为数据库需要更新。但是find的查找功能十分强大。不仅可以查找指定时间内修改的文件,也可以根据关键字查找,也可以根据文件所属用户进行查找,功能很强大。
这里只介绍根据关键字查找的方式。
find . -name "*.sh"关于find命令的一篇很好的介绍,见博文。linux下find查找命令用法。
grep命令
grep是linux的文本搜索工具,它使用正则表达式搜索文本。grep全称Global Regular Expression Print,表示全局正则表达式打印。
首先我们得建立一个测试文本,我从一个VOA网站上找到了一篇英文文章,并且复制到文本中,将其作为测试文本。
命令
grep --color hel*o test.txt![[Linux]常用Linux命令小结(持续更新中)_第1张图片](http://img.e-com-net.com/image/info5/3bf8c7f7d009459d83acb751977cac29.jpg)
该grep语句匹配到helo,hello,helllo,hellllo……
按照正则表达式的规则对文本进行搜索。
关于grep命令,参考了博文每天一个linux命令(39):grep 命令
tar命令
(1)常用解压缩命令,根据压缩文件不同,参数不太一样。如下。
1).解压 tar包
tar –xvf file.tar
2).解压tar.gz
tar -xzvf file.tar.gz
3).解压 tar.bz2
tar -xjvf file.tar.bz2
4).解压tar.Z
tar –xZvf file.tar.Z
(2)压缩文件的命令
tar –cvf doc.tar *.doc
将目录里所有doc文件打包成doc.tar
tar –czf doc.tar.gz *.doc
tar –cjf doc.tar.bz2 *.doc
tar –xZvf doc.tar.Z *.doc
上面命令都可以打包成不同类型的压缩包。
参考了tar压缩解压缩命令详解。
sed命令
sed是一种在线编辑器,它以行为单位对数据进行处理,可以对数据进行增加、替换、删除等操作。常用选项:
-n∶使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN的资料一般都会被列出到萤幕上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。
常用命令:
a ∶新增
c ∶取代
d ∶删除
i ∶插入, i 的后面可以接字串
p ∶列印
这里的内容来源自cnbolgs博客linux之sed用法。
这里不再举例,可参考其它博文。主要说的一点是,sed修改的内容是不会作用到原来的文本中的,相当于是读出去后进行的操作,这一点需要注意。那么sed后的内容如何保存呢?那就用下面的命令吧~
sed '1a mapeiwen' test.txt|cat >temp.txt例题(题目来源自《Linux Shell 从入门到精通》):通过sed命令将input文件中的\OU字符串修改为(ou),在此基础上将该sed命令写成两种sed脚本,利用sed的第2、3种调用方式实现同样的目的。
答案:
(1)sed ‘s/\ou/(ou)/g’ input // \ou转义符咯
(2)将sed 命令写入到bash脚本中(#!/bin/bash);
(3)写入到sed脚本中(#!/bin/sed -f)
关机命令
sudo shutdown -r NOW
sudo halt
输入密码后即可关机。
awk编程
awk是linux里的一种编程语言,适合于文本处理和报表生成。它具有强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行(记录)的读入,以空格为默认分隔符将每条记录切成域。再对各个域选择处理。
记录和域的概念
awk认为输入文件是结构化的(和数据库的结构化其实是差不多一样的含义),awk将每个文件行定义为记录,行中的每个字符串定义为域,域之间用空格、Tab键或其他符号进行分割,分割域的符号叫做分隔符。
![[Linux]常用Linux命令小结(持续更新中)_第2张图片](http://img.e-com-net.com/image/info5/9521949920e0477685e61a43d621b406.jpg)
(图片来源自《Linux Shell 从入门到精通》)
常用使用
(1)根据每一条进行进行处理。一些常见的统计(数据挖掘中经常会使用到)
比如数据信息如下(学号 姓名 语文 数学 英语 ):
2011 mpw 100 89 81
2012 hhh 9 198 78
求出每个学生的平均分。
awk '{print ($3+$4+$5)/3}' student 求出平均分最高的学生。
awk 'BEGIN{max=0;maxid=0} {if(max<($3+$4+$5)/3) {max=($3+$4+$5)/3}} END{print max}' student …
这里提一点,学过JUnit的同学应该知道JUnit 4 里面有before和after这2种修饰。这里的BEGIN 和END作用类似,对记录进行遍历前执行BEGIN,遍历完记录执行END。这里BEGIN和END是区分大小写的(亲测)。
本篇博文将不断更新,完善~~~每天进步一丢丢咯。。==