使用SVD方法实现电影推荐系统
这学期选了一门名叫《web智能与社会计算》的课,老师最后偷懒,最后的课程project作业直接让我们参加百度的一个电影推荐系统算法大赛,然后以在这个比赛中的成绩作为这门课大作业的成绩。不过,最终的结果并不需要百度官方的评估,只需要我们的截图即可(参看百度云平台),例如下面这个:
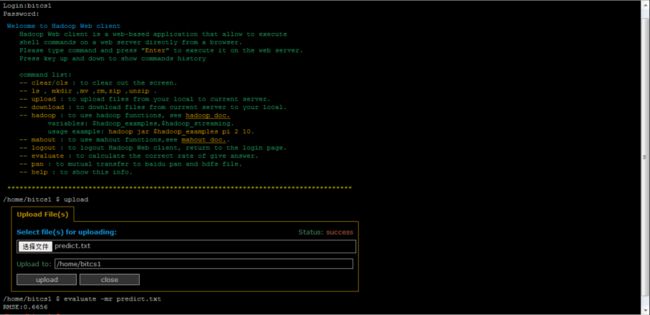
上面最重要的就是RMSE的数值,数值越小代表偏差越小,百度排行榜就是按值从小到大来排列的,这些人使用的可能是比SVD更好的算法,即使这样达到一定范围后再想进步就很难了,估计不会有人低于0.6这个值。
言归正传,下面来说说针对百度这个比赛如何如何用SVD来实现推荐系统,为了了解基本原理可以看看这篇文章:推荐系统相关算法(1):SVD (后面提到的三篇论文也值得一读)
1、数据预处理
本课程的要求是只完成任务一即可,做任务一的时候只需要用到两个数据集,一个是训练数据training_set,一个是待预测的数据predict,百度的要求如下:
l 任务一
n training_set.txt用户评分数据共三列,从左到右依次为userId、movieId、rating。即用户id、电影id、该用户对该电影的评分。列之间以’\t’分隔,行之间以’\r\n’分隔。
n predict.txt为预测集合,共两列。从左到右依次是userId,movieId。即用户id,电影id.列之间以’\t’分隔,行之间以’\r\n’分隔。参赛者需要预测出第三列,即该用户对该电影的评分,作为第三列,并提交给评测平台。需要注意的是,参赛者最终提的predict.txt是三列,列之间以’\t’分隔,行之间以’\r\n’分隔。行之间的顺序不能乱,行的总数不能少。
下载下来以后发现数据并不是从0开始计数的,training_set格式如下:7245481 962729 4.0 7245481 356405 4.0 7245481 836383 4.0 7245481 284550 4.0 7245481 723581 4.0 7245481 827305 4.0 7245481 572786 4.0 7245481 473690 4.0 ..................... ..................... .....................
predict集数据格式如下:
7245481 794171 7245481 381060 7245481 776002 7245481 980705 7245481 354292 7245481 738735 7245481 624561 7245481 985808 7245481 378349 7245481 778269 7245481 242057 ................... ................... ...................
在使用SVD的时候需要用数组存储每一个用户和每一个电影,这里用户的ID都是7位,电影的都是6位,如果直接开个七八位大数组来存储内存估计不够,而且还浪费空间,为此需要先把用户和电影ID进行映射到从0开始一个较小的范围内。
userMap = {}
movieMap = {}
with open('training_set.txt') as fp:
fp_user = open('usermap.txt', 'w')
fp_movis = open('moviemap.txt', 'w')
fp_out = open('smallMatrix.txt', 'w')
fp_prediction = open('test.txt', 'r')
fp_out2 = open('smallPredictionMatrix.txt','w')
for line in fp:
line = line.strip()
if line == '':
continue
tup = line.split()
raw_user = tup[0]
raw_movie = tup[1]
rate = float(tup[2])
if raw_user not in userMap:
userMap[raw_user] = len(userMap.keys())
user_id = userMap[raw_user]
if raw_movie not in movieMap:
movieMap[raw_movie] = len(movieMap.keys())
movie_id = movieMap[raw_movie]
fp_out.write('{0} {1} {2}\n'.format(user_id, movie_id, rate))
for raw_user, user_id in userMap.items():
fp_user.write('{0} {1}\n'.format(raw_user, user_id))
for raw_movie, movie_id in movieMap.items():
fp_movis.write('{0} {1}\n'.format(raw_movie, movie_id))
for line2 in fp_prediction:
line2 = line2.strip()
if line2 == '':
continue
tup2 = line2.split()
raw_user2 = tup2[0]
raw_movie2 = tup2[1]
user_id2 = userMap[raw_user2]
movie_id2 = movieMap[raw_movie2]
fp_out2.write('{0} {1}\n'.format(user_id2, movie_id2))
上面代码实现了用户ID和电影ID的映射过程,实现思想很简单,来一个ID,看看之前是否存在过,如果存在用那个值替换,如果不存在新加入一个,这里是从0开始存储的,处理完以后得到四个文件,用户ID,电影ID的键值对,处理完的小范围训练集,处理完的小范围预测集。
小范围的训练集如下:
0 0 4.0 0 1 4.0 0 2 4.0 0 3 4.0 0 4 4.0 0 5 4.0 0 6 4.0 0 7 4.0 0 8 4.0 0 9 4.0 0 10 4.0 0 11 4.0 0 12 4.0 0 13 4.0 0 14 4.0 0 15 4.0 0 16 4.0 0 17 4.0 0 18 4.0 0 19 4.0 0 20 4.0 0 21 4.0 0 22 4.0 0 23 4.0 0 24 4.0 0 25 4.0 0 26 4.0 0 27 4.0 0 28 4.0 0 29 4.0 0 30 4.0 0 31 4.0 0 32 4.0 0 33 4.0 0 34 4.0 0 35 4.0 0 36 4.0 0 37 4.0...小范围预测集如下:
0 617 0 567 0 575 0 1211 0 1735 0 1255 0 620 0 795 0 890 0 706 0 599 0 1248 0 1651 0 621 0 1996 0 1003 0 2347...
经过这步处理,就不需要再开大数组存储,统计下来不同的用户数,电影数都不到一万个。
2、利用SVD进行训练
得到了小规模数据,修改svd.conf文件里面的值,这里avarageScore这个值需要自己计算后填入,userNum,itemNum是用户和电影数目的范围,后面几个值也并不是固定的,可以根据实际情况进行修改
3.579231 10000 10000 10 0.01 0.05 averageScore userNum itemNum factorNum learnRate regularization
然后运行svd.py文件即可,我们这里训练数据时迭代一次一般需要十五秒的时间,显然训练是很耗时的,为了简单就迭代了五次而已。
3、预测数据
预测数据其实就是矩阵的乘法运算,相比训练来说速度要快很多。这里我们参考上面那篇博客里面的代码,把训练和预测放在一起执行,最终代码如下:
import math
import random
import cPickle as pickle
#calculate the overall average
def Average(fileName):
fi = open(fileName, 'r')
result = 0.0
cnt = 0
for line in fi:
cnt += 1
arr = line.split()
result += int(arr[2].strip())
return result / cnt
def InerProduct(v1, v2):
result = 0
for i in range(len(v1)):
result += v1[i] * v2[i]
return result
def PredictScore(av, bu, bi, pu, qi):
pScore = av + bu + bi + InerProduct(pu, qi)
if pScore < 1:
pScore = 1
elif pScore > 5:
pScore = 5
return pScore
#def SVD(configureFile, testDataFile, trainDataFile, modelSaveFile):
def SVD(configureFile, trainDataFile, modelSaveFile):
#get the configure
fi = open(configureFile, 'r')
line = fi.readline()
arr = line.split()
averageScore = float(arr[0].strip())
userNum = int(arr[1].strip())
itemNum = int(arr[2].strip())
factorNum = int(arr[3].strip())
learnRate = float(arr[4].strip())
regularization = float(arr[5].strip())
fi.close()
bi = [0.0 for i in range(itemNum)]
bu = [0.0 for i in range(userNum)]
temp = math.sqrt(factorNum)
qi = [[(0.1 * random.random() / temp) for j in range(factorNum)] for i in range(itemNum)]
pu = [[(0.1 * random.random() / temp) for j in range(factorNum)] for i in range(userNum)]
print("initialization end\nstart training\n")
#train model
preRmse = 1000000.0
for step in range(5):
fi = open(trainDataFile, 'r')
for line in fi:
arr = line.split()
uid = int(arr[0].strip()) - 1
iid = int(arr[1].strip()) - 1
score = int(arr[2].strip())
prediction = PredictScore(averageScore, bu[uid], bi[iid], pu[uid], qi[iid])
eui = score - prediction
#update parameters
bu[uid] += learnRate * (eui - regularization * bu[uid])
bi[iid] += learnRate * (eui - regularization * bi[iid])
for k in range(factorNum):
temp = pu[uid][k] #attention here, must save the value of pu before updating
pu[uid][k] += learnRate * (eui * qi[iid][k] - regularization * pu[uid][k])
qi[iid][k] += learnRate * (eui * temp - regularization * qi[iid][k])
fi.close()
#learnRate *= 0.9
#curRmse = Validate(testDataFile, averageScore, bu, bi, pu, qi)
#print("test_RMSE in step %d: %f" %(step, curRmse))
#if curRmse >= preRmse:
# break
#else:
# preRmse = curRmse
#write the model to files
fo = file(modelSaveFile, 'wb')
pickle.dump(bu, fo, True)
pickle.dump(bi, fo, True)
pickle.dump(qi, fo, True)
pickle.dump(pu, fo, True)
fo.close()
print("model generation over")
#validate the model
def Validate(testDataFile, av, bu, bi, pu, qi):
cnt = 0
rmse = 0.0
fi = open(testDataFile, 'r')
for line in fi:
cnt += 1
arr = line.split()
uid = int(arr[0].strip()) - 1
iid = int(arr[1].strip()) - 1
pScore = PredictScore(av, bu[uid], bi[iid], pu[uid], qi[iid])
tScore = int(arr[2].strip())
rmse += (tScore - pScore) * (tScore - pScore)
fi.close()
return math.sqrt(rmse / cnt)
#use the model to make predict
def Predict(configureFile, modelSaveFile, testDataFile, resultSaveFile):
#get parameter
fi = open(configureFile, 'r')
line = fi.readline()
arr = line.split()
averageScore = float(arr[0].strip())
fi.close()
#get model
fi = file(modelSaveFile, 'rb')
bu = pickle.load(fi)
bi = pickle.load(fi)
qi = pickle.load(fi)
pu = pickle.load(fi)
fi.close()
#predict
fi = open(testDataFile, 'r')
fo = open(resultSaveFile, 'w')
for line in fi:
arr = line.split()
uid = int(arr[0].strip()) - 1
iid = int(arr[1].strip()) - 1
pScore = PredictScore(averageScore, bu[uid], bi[iid], pu[uid], qi[iid])
fo.write("%f\n" %pScore)
fi.close()
fo.close()
print("predict over")
if __name__ == '__main__':
configureFile = 'svd.conf'
trainDataFile = 'ml_data\\smallMatrix.txt'
testDataFile = 'ml_data\\smallPredictionMatrix.txt'
modelSaveFile = 'svd_model.pkl'
resultSaveFile = 'prediction.txt'
#print("%f" %Average("ua.base"))
SVD(configureFile, trainDataFile, modelSaveFile)
Predict(configureFile, modelSaveFile, testDataFile, resultSaveFile)
4、数据后处理
预测结果作为一列输出到一个单独的文件,按照百度的要求需要把结果插入到预测集的最后一列,用python处理一下就好
fp1 = open('predict.txt')
fp2 = open('prediction.txt')
fp_out = open('file3.txt', 'w')
for line1, line2 in zip(fp1, fp2):
line1 = line1.strip()
line2 = line2.strip()
fp_out.write('{0}\t{1}\n'.format(line1, line2))
最终我们就得到了可以提交到百度云平台上面进行评价的文件,格式如下:
7245481 794171 3.879440 7245481 381060 4.028262 7245481 776002 4.152251 7245481 980705 3.986217 7245481 354292 3.758884 7245481 738735 3.925804 7245481 624561 3.880905 7245481 985808 3.776078 7245481 378349 3.902128 7245481 778269 3.892242 7245481 242057 3.871258 7245481 648898 3.861340 7245481 171218 3.696469 7245481 897136 3.834176 7245481 572785 3.917795 7245481 518661 3.835075 7245481 544840 3.873519 7245481 131620 3.725185 7245481 600353 3.899684 7245481 865019 3.878535 .......................... .......................... ..........................
评价结果就是博文最开始的那张图了。
5、改进和思考
显然我们还能够让RMSE值再小一些,其实一般来说svd在训练的时候还需要有一个测试数据来验证训练的好坏,但百度没有给测试数据,这里我们也没弄,如果有测试数据训练的效果可能会好一些。同时在训练时迭代次数的选择也有技巧,选择太少或太多效果都可能不好,需要自己把握,我们这里只迭代了五次显然不够。svd.conf里面最后三个参数的选择应该还存在技巧。也许还存在其他一些改进的方法,例如考虑到用户之间的关系这些,不过那个处理起来就有点复杂了,任务二貌似就要考虑到这一点。
总的来说,利用SVD仅仅迭代五次就能有这样的结果确实让人惊讶,想法简单但结果却不错,看来简单的并不意外着是不好,一些问题的完美解决往往蕴含在简单之中。