hdfs架构分析与第一个hdfs应用程序
参考
王家林大数据IMF系列
场景
hdfs架构分析与第一个hdfs应用程序
分析
- HDFS架构
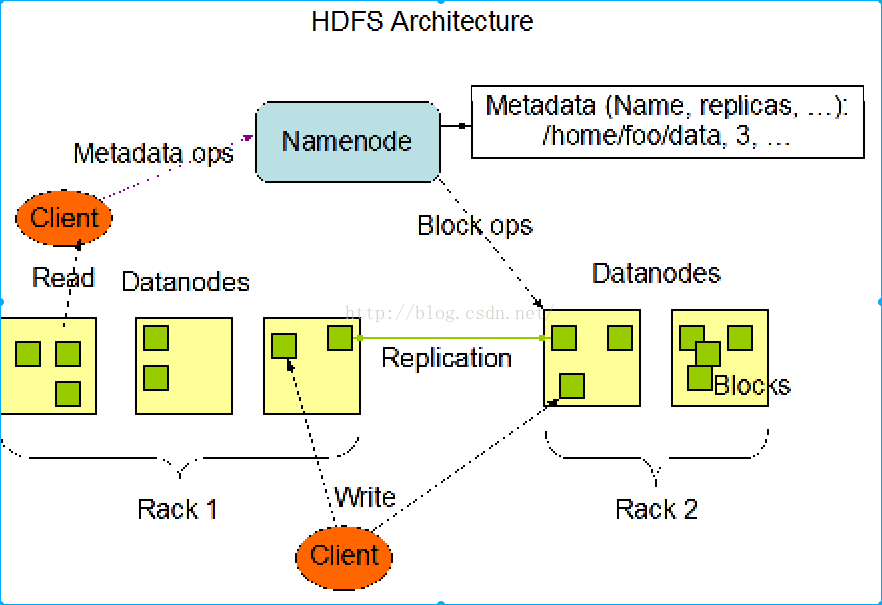
.主从结构
-主节点,只有一个:namenode(HA下会有多个NameNode)
-从节点,有很多个:datanodes
.namenode负责
-接收用户操作请求
-维护文件系统的目录结构
-管理文件与block之间的关系,block与datanode之间的关系
.datanode负责
-存储文件
-文件被分成block存储在磁盘上
-为保证数据安全,文件会有多个副本
注释:
1、HDFS存储的文件是以Block的方式存在的,一个文件的不同Block具体存储在哪台datanaode上是随机的
2、为保证数据的安全,文件的block会有多个副本
3、HDFS本身只是一套分布式数据存储的逻辑管理软件,实际的数据是分布式存储在具体的Linux机器的磁盘上的。
4、HDFS提供了管理文件系统的众多工具,eg:fsck
- HDFS读写
1、HDFS读取数据:Client向NameNode发起读数据的请求,NameNode会检索Client读取数据的元数据信息来决定第一个Block具体在哪些台机器上,并根据Hadoop的机架感知策略等决定把哪个副本交给Client取读取,其实NameNode是返回了该副本的URL,接下来就是Client通过该URL建立InputStram进行数据的读取;后续Block按照此流程依次类推。
2、HDFS写入数据:Client向NameNode发起写数据的请求,NameNode会决定把第一个Block及其副本写在哪些台机器(一般而言,如果有三个副本,那么两个副本在同一个Rack,另外一个副本在另一个机器中),但是实际上写入数据的时候,客户端只写入每个Block的第一个副本给HDFS,Client写入每个Block的第一个副本后,该Block的副本是在NameNode的管理下基于第一个副本的数据进行Pipeline方式的写入。
- HDFScommand-shell
http://hadoop.apache.org/docs/r2.6.4/hadoop-project-dist/hadoop-common/FileSystemShell.html
#hadoop fs -rm -r hdfs://master:9000/output2
注 : fs是一个用于操作HDFS的客户端程序-如果把HDFS看作是一个百度网盘的话,那么fs可以理解成百度云管家
- HDFSAPI for java
http://hadoop.apache.org/docs/r2.6.4/api/index.html
- 第一个HDFS应用程序之 向hdfs写入一个文件
import java.io.IOException;
import java.io.InputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
/**
* 第一个HDFS程序
* function 体验hdfs API
* @author pengyucheng
* date 2016/04/24
*/
public class HelloHDFS
{
public static void main(String[] args) throws IOException
{
String uri = "hdfs://112.74.21.122:9000";
Configuration config = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), config);
// 列出/input目录下的所有文件
FileStatus[] statuses = fs.listStatus(new Path("/input"));
for (FileStatus fileStatus : statuses) {
System.out.println(fileStatus);
}
// 在/input目录下创建一个文件 test.log并写入数据
FSDataOutputStream fsop = fs.create(new Path("/input/test.log"));
fsop.write("Hello HDFS".getBytes());
fsop.flush();
fsop.close();
// 在控制台输出test.log文件中的内容
InputStream is = fs.open(new Path("/input/test.log"));
IOUtils.copyBytes(is, System.out, 1024,true);
}
}
总结
1、HDFS is the primary distributed storage used by Hadoop applications. A HDFS cluster primarily consists of a NameNode that manages the file system metadata and DataNodes that store the actual data.
2、HDFS是一个分布式文件系统,是一个软件系统,真实数据存储在Linux管理下的物理机器上.
”