CMS项目总结:10、MyBatis进阶:SQL映射的XML文件
Config XML file : SqlMapConfig.xml
SQL Mapping XML file : Article.xml、Channel.xml、Admin.xml…
MyBatis真正的力量是在映射语句中。这里是奇迹发生的地方。对于所有的力量,SQL映射的XML文件是相当的简单。当然如果你将它们和对等功能的JDBC代码来比较,你会发现映射文件节省了大约95%的代码量。MyBatis的构建就是聚焦于SQL的,使其远离于普通的方式。
SQL映射文件有很少的几个顶级元素(按照它们应该被定义的顺序):
cache - 配置给定命名空间的缓存。
cache-ref – 从其他命名空间引用缓存配置。
resultMap – 最复杂,也是最有力量的元素,用来描述如何从数据库结果集中来加载你的对象。
parameterMap – 已经被废弃了!老式风格的参数映射。内联参数是首选,这个元素可能在将来被移除。这里不会记录。
sql – 可以重用的SQL块,也可以被其他语句引用。
insert – 映射插入语句
update – 映射更新语句
delete – 映射删除语句
select – 映射查询语句
首先创建这个类:
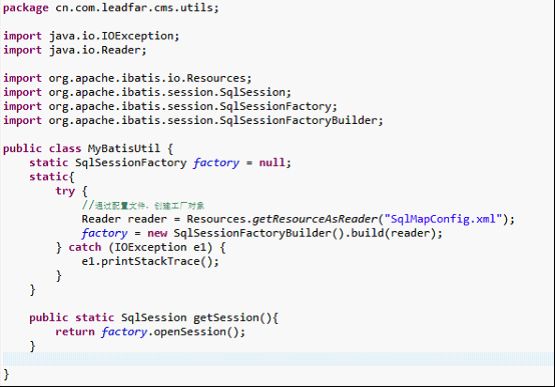
Reader reader = Resources.getResourceAsReader("SqlMapConfig.xml");
factory = new SqlSessionFactoryBuilder().build(reader);
读取配置文件SqlMapConfig.xml,通过这个配置文件创建SqlSessionFactory类的对象factory。
SqlSessionFactoryBuilder:这个类可以被实例化,使用和丢弃。一旦你创建了SqlSessionFactory后,这个类就不需要存在了。因此SqlSessionFactoryBuilder实例的最佳范围是方法范围(也就是本地方法变量)。你可以重用SqlSessionFactoryBuilder来创建多个SqlSessionFactory实例,但是最好的方式是不需要保持它一直存在来保证所有XML解析资源,因为还有更重要的事情要做。
SqlSessionFactory:一旦被创建,SqlSessionFactory应该在你的应用执行期间都存在。没有理由来处理或重新创建它。使用SqlSessionFactory的最佳实践是在应用运行期间不要重复创建多次。这样的操作将被视为是非常糟糕的。因此SqlSessionFactory的最佳范围是应用范围。有很多方法可以做到,最简单的就是使用单例模式或者静态单例模式。然而这两种方法都不认为是最佳实践。这样的话,你可以考虑依赖注入容器,比如Google Guice或Spring。这样的框架允许你创建支持程序来管理单例SqlSessionFactory的生命周期。
SqlSession:每个线程都应该有它自己的SqlSession实例。SqlSession的实例不能被共享,也是线程不安全的。因此最佳的范围是请求或方法范围。绝对不能将SqlSession实例的引用放在一个类的静态字段甚至是实例字段中。也绝不能将SqlSession实例的引用放在任何类型的管理范围中,比如Serlvet架构中的HttpSession。如果你现在正用任意的Web框架,要考虑SqlSession放在一个和HTTP请求对象相似的范围内。换句话说,基于收到的HTTP请求,你可以打开了一个SqlSession,然后返回响应,就可以关闭它了。关闭Session很重要,你应该确保使用finally块来关闭它。
ArticleDaoForMyBatisImpl的代码:


首先调用MyBatisUtil的静态方法getSession()获取SqlSession ,SqlSession session = MyBatisUtil.getSession();
每个线程都应该有它自己的SqlSession实例。SqlSession的实例不能被共享,也是线程不安全的。因此最佳的范围是请求或方法范围。绝对不能将SqlSession实例的引用放在一个类的静态字段甚至是实例字段中。也绝不能将SqlSession实例的引用放在任何类型的管理范围中,比如Serlvet架构中的HttpSession。如果你现在正用任意的Web框架,要考虑SqlSession放在一个和HTTP请求对象相似的范围内。换句话说,基于收到的HTTP请求,你可以打开了一个SqlSession,然后返回响应,就可以关闭它了。关闭Session很重要,你应该确保使用finally块来关闭它。
查询语句是使用MyBatis时最常用的元素之一。直到你从数据库取出数据时才会发现将数据存在数据库中是多么的有价值,所以许多应用程序查询要比更改数据多的多。对于每次插入,更新或删除,那也会有很多的查询。这是MyBatis的一个基本原则,也是将重心和努力放到查询和结果映射的原因。对简单类别的查询元素是非常简单的。
调用SqlSession实例来直接执行已映射的SQL语句,例如:
Article a = (Article)session.selectOne(Article.class.getName()+".findById", id);
datas = session.selectList(Article.class.getName()+".findArticleByTitle", params);
session.insert(Article.class.getName()+".add", a);
session.delete(Article.class.getName()+".del", Integer.parseInt(id));
session.update(Article.class.getName()+".update", a);
这是Article.xml的代码:
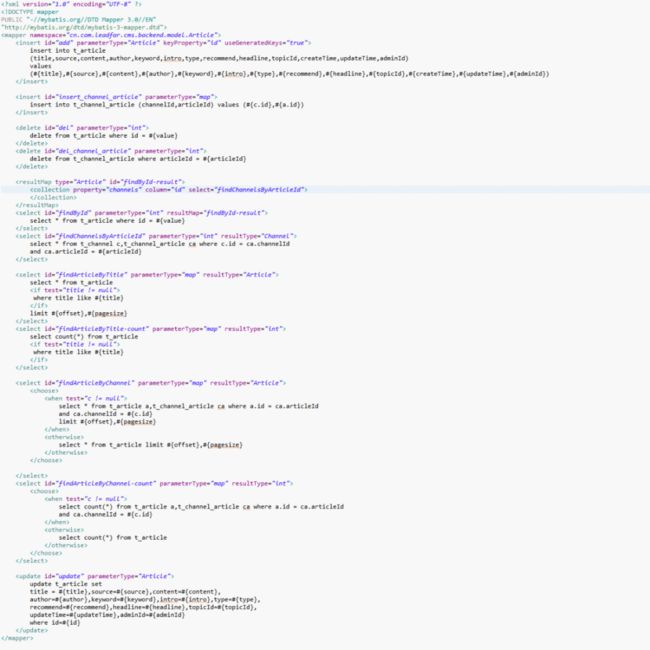
1、(在命名空间namespace“cn.com.leadfar.cms.backend.model.Article”中,定义了一个id为“add”的映射语句,这样它允许你使用全路径类名“cn.com.leadfar.cms.backend.model.Article.add”来调用映射语句,我们可以说是有意定义namespace为全路径类名的,这样在DAO中可以简便的通过(Article.class.getName()+".add",参数)来调用。)
当调用ArticleDaoForMyBatisImpl的session.insert(Article.class.getName()+".add", a);方法时,Article.class.getName()即为cn.com.leadfar.cms.backend.model.Article,所以系统会去Article.xml、Channel.xml、Admin.xml…配置文件中找<mapper namespace="cn.com.leadfar.cms.backend.model.Article">的对应配置文件,然后根据.add在这个配置文件中找id为add的sql语句。即找到了Article.xml中的
<insert id="add" parameterType="Article" keyProperty="id" useGeneratedKeys="true">
insert into t_article
(title,source,content,author,keyword,intro,type,recommend,headline,topicId,createTime,updateTime,adminId)
values (#{title},#{source},#{content},#{author},#{keyword},#{intro},#{type},#{recommend},#{headline},#{topicId},#{createTime},#{updateTime},#{adminId})
</insert>
这里的parameterType="Article"表示从调用sql语句session.insert(Article.class.getName()+".add", a);传过来的参数a是Article类型的对象,Article(bean)中的title、source和content……属性将会被查找,然后它们的值就被传递到预处理语句的参数#{title},#{source},#{content}……中。这里可以直接写Article正是因为在SqlMapConfig.xml中定义了<typeAlias type="cn.com.leadfar.cms.backend.model.Article" alias="Article"/>)。
<select id="findArticleByTitle" parameterType="int" resultType="Article">
select * from t_article where id = #{id}
</select>
上面的这个示例说明了一个非常简单的命名参数映射。参数类型被设置为“int”,因此这个参数可以被设置成任何内容。原生的类型或简单数据类型,比如整型和没有相关属性的字符串,因此它会完全用参数来替代。
MyBatis会在幕后自动创建一个ResultMap,基于属性名来映射到Article(JavaBean)的属性上。如果字段名没有精确匹配,你可以在字段名上使用select字句的别名(一个基本的SQL特性)来匹配标签。比如:
<select id=”findArticleByTitle” parameterType=”int” resultType=”Article”>
select
article_id as “id”,
article_name as “userName”,
hashed_password as “hashedPassword”
from some_table
where id =#{id}
</select>
当t_article表对id使用了自动生成的类型,那么设定useGeneratedKeys="true",而keyProperty="id"的意思是取出数据库的t_article表中自增长的字段(auto_increment)的值赋给Article(JavaBean)参数中的id属性,在DAO中通过取出的这个id属性的值继续执行往t_channel_article中插入articleId和channelId的任务。
Set<Channel> channels = a.getChannels();
if(channels != null){
for(Channel channel:channels){
Map params = new HashMap();
params.put("a", a);
params.put("c", channel);
session.insert(Article.class.getName()+".insert_channel_article", params);
}
}
在这里一篇article可能会有多个channel,new一个map,将article和channel通过键值对的形式放入map中,传入sql语句,
<insert id="insert_channel_article" parameterType="map">
insert into t_channel_article (channelId,articleId) values (#{c.id},#{a.id})
</insert>
在sql语句中也定义parameterType="map",表示接受的参数为map类型,同时这里的c.id表示传过来的map中key为c的value(channel)的id属性的值。
2、resultMap元素是MyBatis中最重要最强大的元素。它就是让你远离90%的需要从结果集中取出数据的JDBC代码的那个东西,而且在一些情形下允许你做一些JDBC不支持的事情。事实上,编写相似于对复杂语句联合映射这些等同的代码,也许可以跨过上千行的代码。ResultMap的设计就是简单语句不需要明确的结果映射,而很多复杂语句确实需要描述它们的关系。
当调用a = (Article)session.selectOne(Article.class.getName()+".findById", id);方法时,注意以下代码,为重点:
<resultMap type="Article" id="findById-result">
<result column="id" property="id"/>
<collection property="channels" column="id" select="findChannelsByArticleId"></collection>
</resultMap>
<select id="findById" parameterType="int" resultMap="findById-result">
select * from t_article where id = #{value}
</select>
<select id="findChannelsByArticleId" parameterType="int" resultType="Channel">
select * from t_channel c,t_channel_article ca where c.id = ca.channelIdand ca.articleId = #{articleId}
</select>
首先执行<select id="findById" parameterType="int" resultMap="findById-result">
select * from t_article where id = #{value}
</select>
根据传过来的article的id从t_article表中取出article,这里不是resultType,而是通过resultMap="findById-result"来定义映射规则,所以系统会寻找resultMap标签中id为findById-result的sql语句,
<resultMap type="Article" id="findById-result">
<result column="id" property="id"/>
<collection property="channels" column="id" select="findChannelsByArticleId"></collection>
</resultMap>
中的type="Article"表示从转入resultMap的语句中传过来的参数是Article类型的,后面的<result column="id" property="id"/>表示如果Article这个bean中的属性和t_article表中的字段名不一致的话,在result标签中进行匹配,定义字段与属性之间的映射规则,如果字段与属性名一致,则无需显式定义映射规则。例如:<result column="id" property="key"/>。
接下来的<collection property="channels" column="id" select="findChannelsByArticleId">,利用collection来定义属性类型为集合的映射规则,通常需要发出第二条映射语句来查询集合的数据,select就是另外一个映射语句的ID,这条映射语句将接收column字段所指定的值作为参数进行执行,并将执行结果自动设置到property所指定的"channels"这个Article的channels属性中。
使用resultMap或者resultType,但是不能同时使用
3、List datas = null;
Map params = new HashMap();
if(title != null) {
params.put("title", "%"+title+"%");
}
params.put("offset", offset);
params.put("pagesize", pagesize);
//查询当前页数据
datas = session.selectList(Article.class.getName()+".findArticleByTitle", params);
(MyBatis的一个强大的特性之一通常是它的动态SQL能力。如果你有使用JDBC或其他相似框架的经验,你就明白条件地串联SQL字符串在一起是多么的痛苦,确保不能忘了空格或在列表的最后省略逗号。动态SQL可以彻底处理这种痛苦。通常使用动态SQL不可能是独立的一部分,MyBatis当然使用一种强大的动态SQL语言来改进这种情形,这种语言可以被用在任意映射的SQL语句中。MyBatis采用功能强大的基于OGNL的表达式。 lif lchoose(when,otherwise) ltrim(where,set) lforeach )
在动态SQL中所做的最通用的事情是包含部分where字句的条件。比如:
在Article.xml中是这么执行这句话的:
<select id="findArticleByTitle" parameterType="map" resultType="Article">
select * from t_article
<if test="title != null">
where title like #{title}
</if>
limit #{offset},#{pagesize}
</select>
要注意在这里title和offset、pagesize不一样,它不是“?”(sql = "select * from t_article where title like '%"+title+"%' limit ?,?";)
这里虽然写的resultType="Article" 但实际上是指返回的List中存放Article对象
Choose,when,otherwise:
<select id=”findArticleByTitle” parameterType=”Article” resultType=”Article”>
select * from t_article
where
<if test=”title != null”>
title like #{title}
</if>
<if test=”content != null”>
and content like #{content }
</if>
<if test=”author != null and keyword!= null”>
and source like #{source}
</if>
</select>
如果这些条件都没有匹配上将会发生什么?这条SQL结束时就会成这样:
select * from t_article where
这会导致查询失败。如果仅仅第二个条件匹配是什么样的?这条SQL结束时就会是这样:
select * from t_article where and content like '~~'
这个查询也会失败。这个问题不能简单的用条件来解决。
MyBatis有一个简单的解决方案,加上一个简单的改变--> <where>标签,所有事情都会顺利进行:
<select id=”findArticleByTitle” parameterType=”Article” resultType=”Article”>
select * from t_article
<where>
<if test=”title != null”>
title like #{title}
</if>
<if test=”content != null”>
and content like #{content }
</if>
<if test=”author != null and keyword!= null”>
and source like #{source}
</if>
</where>
</select>
foreach : 另外一个动态SQL通用的必要操作是迭代一个集合,通常是构建在IN条件中的。比如(这段代码是从文档中摘下来的,看懂就行,我的代码里没这段):
<select id="selectPostIn" resultType="domain.blog.Post">
SELECT *
FROM POST P
WHERE ID in
<foreach item="item" index="index" collection="list" open="(" separator="," close=")">
#{item}
</foreach>
</select>
4、session.update(Article.class.getName()+".update", a);
//删除文章和频道之间的关联
session.delete(Article.class.getName()+".del_channel_article", a.getId());
//插入文章和频道之间的关联
Set<Channel> channels = a.getChannels();
if(channels != null){
for(Channel c:channels){
Map params = new HashMap();
params.put("a", a);
params.put("c", c);
session.insert(Article.class.getName()+".insert_channel_article", params);
}
}
因为article表中是不存channel字段的,article跟channel的关联是通过一张专门的t_channle_article表来表示的,在更新文章时,先把Article(bean)中的channels外的属性更新到article表中,
<update id="update" parameterType="Article">
update t_article set
title = #{title},source=#{source},content=#{content},author=#{author},keyword=#{keyword},intro=#{intro},
type=#{type}, recommend=#{recommend},headline=#{headline},topicId=#{topicId},
updateTime=#{updateTime},adminId=#{adminId}
where id=#{id}
</update>
其次根据articleId把t_channle_article中的跟此篇文章关联的记录全删掉,然后再插入新的article跟channel的关联记录
5、sql这个元素可以被用来定义可重用的SQL代码段,可以包含在其他语句中。比如:
<sql id=”userColumns”> id,username,password </sql>
这个SQL片段可以被包含在其他语句中,例如:
<select id=”selectUsers” parameterType=”int” resultType=”hashmap”>
select <include refid=”userColumns”/> from some_table where id = #{id}
</select>
6、当执行完后一定关闭SqlSession,应该确保用finally块来关闭它。
下面的示例就是一个确保SqlSession关闭的基本模式:
SqlSession session = sqlSessionFactory.openSession();
try {
// do work
} catch (Exception e) {
e.printStackTrace();
session.rollback();
} finally {
//关闭session
session.close();
}
在你的代码中一贯地使用这种模式,将会保证所有数据库资源都正确地关闭(假设你没有通过你自己的连接关闭,这会给MyBatis造成一种迹象表明你要自己管理连接资源)。
7、MyBatis包含一个非常强大的查询缓存特性,它可以非常方便地配置和定制。MyBatis 3中的缓存实现的很多改进都已经实现了,使得它更加强大而且易于配置。
默认情况下是没有开启缓存的,除了局部的session缓存,可以增强变现而且处理循环依赖也是必须的。要开启二级缓存,你需要在你的SQL映射文件中添加一行:
<cache/>
字面上看就是这样。这个简单语句的效果如下:
映射语句文件中的所有select语句将会被缓存。
映射语句文件中的所有insert,update和delete语句会刷新缓存。
缓存会使用Least Recently Used(LRU,最近最少使用的)算法来收回。
根据时间表(比如no Flush Interval,没有刷新间隔),缓存不会以任何时间顺序来刷新。
缓存会存储列表集合或对象(无论查询方法返回什么)的1024个引用。
缓存会被视为是read/write(可读/可写)的缓存,意味着对象检索不是共享的,而且可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
所有的这些属性都可以通过缓存元素的属性来修改。比如:
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
这个更高级的配置创建了一个FIFO缓存,并每隔60秒刷新,存数结果对象或列表的512个引用,而且返回的对象被认为是只读的,因此在不同线程中的调用者之间修改它们会导致冲突。
可用的收回策略有:
LRU – 最近最少使用的:移除最长时间不被使用的对象。
FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。
WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
默认的是LRU。
flushInterval(刷新间隔)可以被设置为任意的正整数,而且它们代表一个合理的毫秒形式的时间段。默认情况是不设置,也就是没有刷新间隔,缓存仅仅调用语句时刷新。
size(引用数目)可以被设置为任意正整数,要记住你缓存的对象数目和你运行环境的可用内存资源数目。默认值是1024。
readOnly(只读)属性可以被设置为true或false。只读的缓存会给所有调用者返回缓存对象的相同实例。因此这些对象不能被修改。这提供了很重要的性能优势。可读写的缓存会返回缓存对象的拷贝(通过序列化)。这会慢一些,但是安全,因此默认是false。