TCP/IP协议学习之六(RPC原理以及NFS协议)
有时候我们需要Linux系统之间共享文件,常用的方法为NFS(网络文件系统)。
那么这个NFS协议是怎么实现的呢?
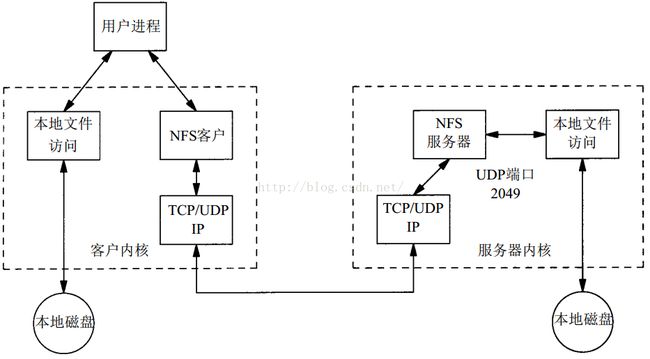
网络文件系统实现的核心是使用了RPC(Remote Procedure Call Protocol),也就是使用了远程过程调用协议。在说明NFS协议之前必须先搞清楚RPC。
传统模式下都是本地编写程序,编译后在本地执行,调用本地资源,在数据日益膨胀的今天,计算量增大,显然使用这种方式是不行的,需要寻找一种方式能够使用其他主机上的资源来完成计算任务,然后结果汇总到一个主机,说到这里,是不是有点分布式计算的味道,和hadoop的实现方式有点相似,其实hadoop就是利用RPC来实现的。
RPC技术最早出现在1981年由Nelson提出,1984年,Birrell和Nelson把RPC用在支持异构型分布式系统之间通讯,Birrel的RPC模型引入存根进程(stub)作为远程进程的本地代理,调用RPC运行时库(RPC runtime)来传输网络中的调用。stub与rpcruntime屏蔽了网络调用所涉及的众多细节,由于分布式系统的异构性以及分布式计算与计算任务的多样性,RPC作为网络通信与委托计算的实现机制,在实现上种类繁多,其中以Sun公司提出的NFS,这个主要是分布式存储;开放软件基金会提出(OSF)提出的ONC,这个主要用于分布式计算。
RPC是建立在Socket之上的,一台主机上运行的主程序,可以调用另一台主机上准备好的子程序,就像本地调用子程序一样,不需要知道底层网络实现的细节。RPC使用类似C/S模型,请求的时候,请求程序时客户端,而服务提供的程序则是服务器。使用C/S模型忽略通讯的具体细节,从而程序员不必关心C/S之间的通信协议,集中精力实现其过程就可以了,这一点就决定了RPC生成的通讯包不可能对每种应用都有最恰当的处理方法,与Socket相比会占用更多地网络带宽与系统资源。
了解了RPC是什么,那么RPC是怎么工作的呢?
RPC调用的时候一般有两种方式:
1、同步调用,客户端等待调用执行完成后并返回结果;
2、异步调用,客户端调用后不用等待执行结果的返回,但可以通过回调通知等方式获取返回结果。如若客户端不关心调用返回的结果,则称为单向异步调用。
任何RPC C/S程序的重要实体都包括 IDL 文件(接口定义文件)、客户机 stub、服务器 stub 以及由客户机和服务器程序共用的头文件。客户机和服务器 stub 使用 RPC 运行时库通信。RPC 运行时库提供一套标准的运行时例程来支持 RPC 应用程序。
当我们建立RPC服务后,客户算的调用参数通过调用底层的RPC传输管道,并根据传输前所提供的目的地址及其RPC上层应用程序的stub,转到相应的RPC应用程序服务端,然后客户端程序处于等待状态,直到收到应答或者Timeout的超时信号。服务端获取请求消息,服务端stub吧所需的信息提交给上层的服务应用程序,服务端执行远程过程调用,然后使用RPC运行时库将结果返回给客户端stub,最后客户端stub将结果反馈给客户端应用程序。从上面的过程可以看出来,stub作为应用程序与RPC运行时层之间的接口,它使得两者可以以理解的格式交互信息。其过程如下所示:

其实RPC,客户端与服务端交互主要涉及以下几个步骤:
- 服务器 RPC 应用程序初始化期间它会向 RPC 运行时库注册接口。需要注册接口是因为,客户机在向服务器发出远程过程调用时,要检查它是否与服务器兼容。服务器创建绑定信息并把信息存储在名称服务数据库中,客户机可以访问这个数据库并寻找到服务器的连接信息。服务器如果使用动态端点,那么它把端点信息放在服务器系统上的本地端点映射数据库中。本地端点映射数据库用于存储在此主机上运行的 RPC 服务器进程的所有端点。服务器启动,监听来自客户机的远程过程调用。
- 客户机发出远程过程调用,此时它会联系名称服务数据库,以寻找服务器系统的相关信息。RPC 运行时库使用这些信息联系服务器系统上的本地端点映射数据库,了解服务器进程在哪个端点上监听到达的 RPC。
- 客户机找到服务器之后,客户机 stub 把远程过程调用和参数转换为服务器 stub 可以理解的格式,然后交给客户机运行时,由客户机运行时通过网络传输这些信息。
- 服务器 RPC 运行时库接收到达的 RPC 调用,把它传递给服务器 stub,服务器 stub 把它转换为服务器可以理解的格式。
- 执行 RPC 调用之后,服务器 stub 和服务器运行时把结果发送回客户机。
- 客户机RPC 运行时接收执行结果,传递给客户机 stub,客户机 stub 再把它传递给客户机进程。客户机应用程序从客户机 stub 接收结果并完成 RPC 调用。
以上就是RPC的一些知识可以帮助我们理解NFS系统的实现。
一个RPC的过程调用报文的格式大致如下:
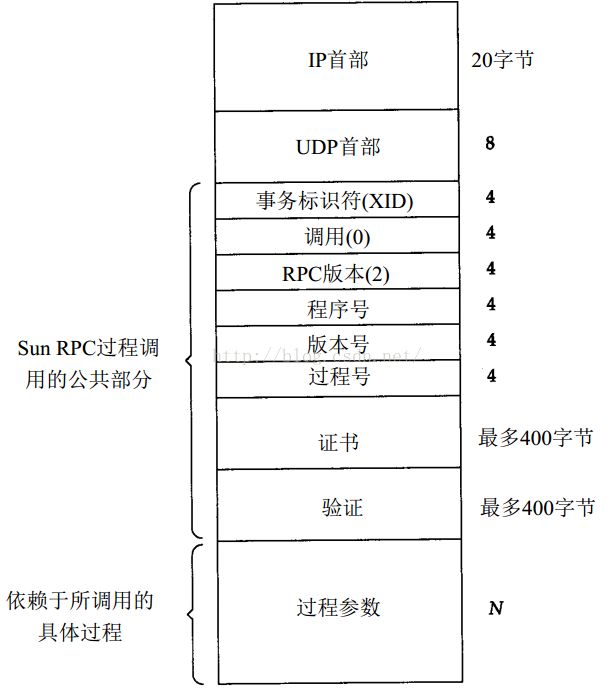
RPC数据报中字段中的公共部分几个含义:
事务标识符(XID)由客户程序设置,由服务器程序返回。当客户收到一个应答,它将服务器返回的XID与它发送的请求的XID相比较。如果不匹配,客户就放弃这个报文,等待从服务器返回的下一个报文。每次客户发出一个新的RPC,它就会改变报文的XID。但是如果客户重传一个以前发送过的RPC,重传报文的XID不会修改。调用(call)变量在过程调用报文中设置为0,在应答报文中设置为1。当前的RPC版本是2。接下来三个变量:程序号、版本号和过程号,标识了服务器上被调用的特定过程。证书(credential)字段标识了客户。有些情况下,证书字段设置为空值;另外一些情况下,证书字段设置为数字形式的客户的用户号和组号。服务器可以查看证书字段以决定是否执行请求的过程。验证(verifier)字段用于使用了DES加密的安全RPC。
远程过程的RPC服务器程序使用的是临时端口,而不是知名端口。这就需要某种形式的“注册”程序来跟踪哪一个RPC程序使用了哪一个临时端口。在 Sun RPC中,这个注册程序被称为端口映射器 (port mapper)。