Study Note: RoofLine Model
Some background knowledge:
Here is some connection between latency, throughput and concurrency [1]:

Here is the influence factor of runtime and performance: latency and throughput.
Also, you can reduce running time by increase the throughput.
An example of higher performance != shorter runtime: Imagine a sparse matrix multiplication will take shorter runtime than normal matrix_mul. However, the throughput will be larger than the former one.
A useful hit of FLOP: must notice that floating point operation means operation of add and mul. If you code only use one operation, there is no way you can get the peak performance of FLOP. You can only achieve half of it.
AI (Arithmetic Intensity)
Arithmetic Intensity is the ratio of total floating-point operations to total data movement (bytes). A higher AI means that more likely to achieve the peak performance. Must notice that:
Arithmetic intensity is ultimately limited by compulsory traffic (this cannot be optimised). However, Arithmetic intensity is diminished by conflict or capacity misses. (These can be optimised).
RoofLine Model
What is the axises of RoofLine Model?
Answer: Here is the y axis

It means that if the optimisation did not increase the stream bandwidth, AI* Bandwidth will still smaller than the peak performance and it will be the attainable performance.
and the x axis is
Actual FLOP:Byte ratio. (AI)
We would like to use this as an example to construct RoofLine Model[1]:

The initial model of RoofLine is like this:
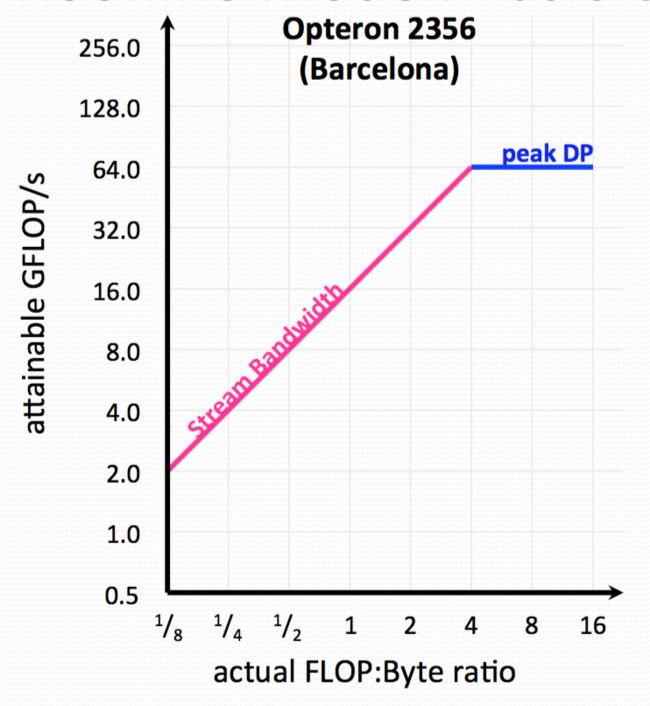
We can tell once it can reach 4FLOP per 1byte or higher, the 2356 will reach its peak performance. But if the bandwidth is small and bandwidth/total data needed movement(byte) is <1, then actual performance(attainable performance) is smaller than peak performance. (since bandwidth/total data needed in movement is less than 1).
There are others constraint of performance like computation ceils, communication ceils and locality walls in RoofLine Model. Remember that we called RoofLine model is synthesising communication,computation,and locality into a single visually-intuitive performance figure using bound and bottleneck analysis.
Now, we have talked a little about the communication. Let us talk it deeper:
The stream line limitation just assumes that you can use the all bandwidth to transfer data. However, the problem is whether you can.
1) Explicit software prefetch instructions are required to achieve peak bandwidth. If you have't used the prefetch instructions, you will get a ceiling like this[1]:
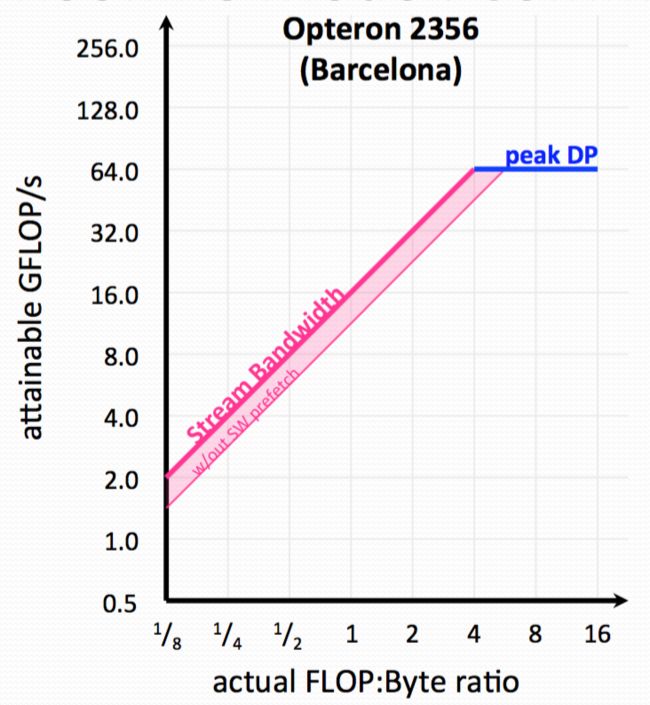
2) Also, 2356 is NUMA(Non Uniform Memory Access Architecture. As such memory traffic must be correctly balanced among the two sockets to achieve good Stream bandwidth. If you haven't we will get a ceiling like this:
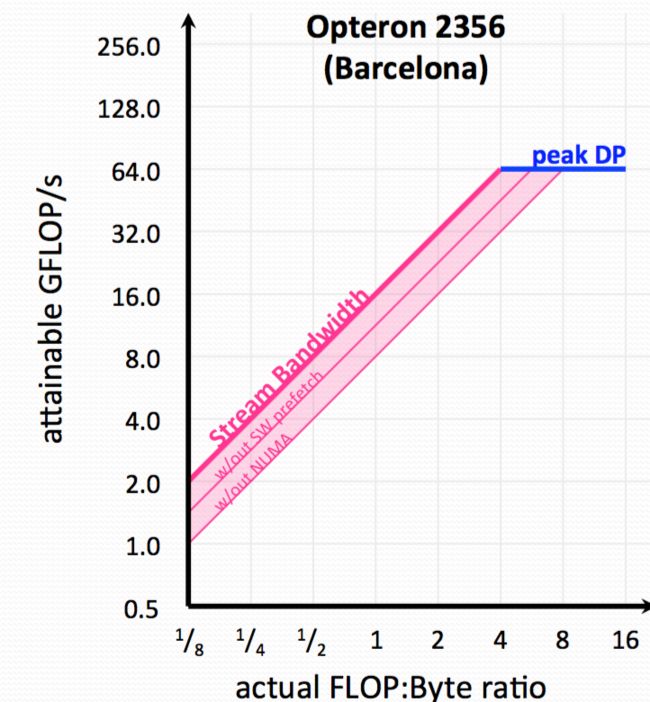
After talking about the communication, let us talk about computation.
1) If the code is dominated by adds, then attainable performance is half of peak.

2) Opterons have 128-bit data paths(two ways double precision). If instructions aren’t SIMDized, attainable performance will be halved.

3) On Opterons, floating-point instructions have a 4 cycle latency. If we don’t express 4-way ILP(Instruction level parallelism), performance will drop by as much as 4x.

What is instruction level parallelism?
Actually, instruction level parallelism has been taken care by compiler automatically. Instruction level parallelism means to find out instructions in a sequence that can be computed at the same.
Even though our compiler has done a good job on taking care of this. But, Compilers may produce valid instruction sequences that have less ILP when executed in order. Like it will produce instructions like:

Obviously, more clever choice will be:
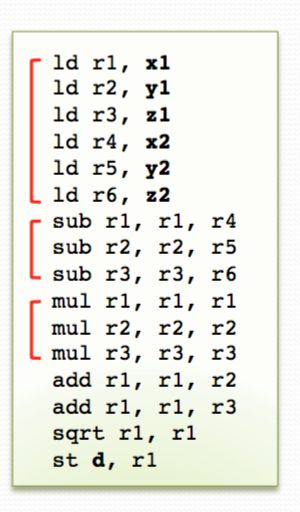
If we use a CPU of traditional in order pipeline, it will run the instruction sequence as the compiler tells with two different means:

However, even with the in-order super scalar pipeline, it will still reduce the instruction level parallelism.
However, if we use a out of order pipeline CPU, it allows instruction reordering.
It can automatically assemble the instructions.

Disadvantage: As you can see, much of the portion of this cpu is focusing on direct the instructions and control the boundary issues. It is a significantly more complex processor architecture than simple in order pipeline. And it also consume more energy.
Now, let us talk about locality issues:
1) Remember, memory traffic includes more than just compulsory misses. Actual arithmetic intensity may be substantially lower. The original boundary is just for only includes compulsory misses.


The actual roofline model will be:

While the AI will be:
