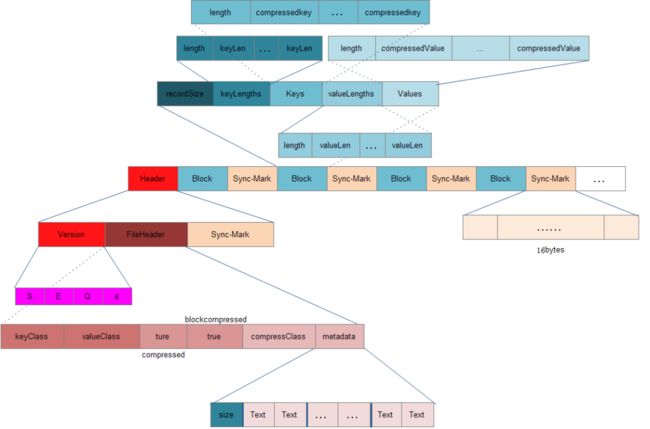
hadoop中的文件接口类-- SequenceFile
SequenceFile文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面文件(Flat File)。目前,也有不少人在该文件的基础之上提出了一些HDFS中小文件存储的解决方案,他们的基本思路就是将小文件进行合并成一个大文件,同时对这些小文件的位置信息构建索引。不过,这类解决方案还涉及到Hadoop的另一种文件格式——MapFile文件。SequenceFile文件并不保证其存储的key-value数据是按照key的某个顺序存储的,同时不支持append操作。
在SequenceFile文件中,每一个key-value被看做是一条记录(Record),因此基于Record的压缩策略,SequenceFile文件可支持三种压缩类型(SequenceFile.CompressionType):
NONE: 对records不进行压缩;
RECORD: 仅压缩每一个record中的value值;
BLOCK: 将一个block中的所有records压缩在一起;
那么,基于这三种压缩类型,Hadoop提供了对应的三种类型的Writer:
SequenceFile.Writer 写入时不压缩任何的key-value对(Record);
- public static class Writer implements java.io.Closeable {
- ...
- //初始化Writer
- void init(Path name, Configuration conf, FSDataOutputStream out, Class keyClass, Class valClass, boolean compress, CompressionCodec codec, Metadata metadata) throws IOException {
- this.conf = conf;
- this.out = out;
- this.keyClass = keyClass;
- this.valClass = valClass;
- this.compress = compress;
- this.codec = codec;
- this.metadata = metadata;
- //创建非压缩的对象序列化器
- SerializationFactory serializationFactory = new SerializationFactory(conf);
- this.keySerializer = serializationFactory.getSerializer(keyClass);
- this.keySerializer.open(buffer);
- this.uncompressedValSerializer = serializationFactory.getSerializer(valClass);
- this.uncompressedValSerializer.open(buffer);
- //创建可压缩的对象序列化器
- if (this.codec != null) {
- ReflectionUtils.setConf(this.codec, this.conf);
- this.compressor = CodecPool.getCompressor(this.codec);
- this.deflateFilter = this.codec.createOutputStream(buffer, compressor);
- this.deflateOut = new DataOutputStream(new BufferedOutputStream(deflateFilter));
- this.compressedValSerializer = serializationFactory.getSerializer(valClass);
- this.compressedValSerializer.open(deflateOut);
- }
- }
- //添加一条记录(key-value,对象值需要序列化)
- public synchronized void append(Object key, Object val) throws IOException {
- if (key.getClass() != keyClass)
- throw new IOException("wrong key class: "+key.getClass().getName() +" is not "+keyClass);
- if (val.getClass() != valClass)
- throw new IOException("wrong value class: "+val.getClass().getName() +" is not "+valClass);
- buffer.reset();
- //序列化key(将key转化为二进制数组),并写入缓存buffer中
- keySerializer.serialize(key);
- int keyLength = buffer.getLength();
- if (keyLength < 0)
- throw new IOException("negative length keys not allowed: " + key);
- //compress在初始化是被置为false
- if (compress) {
- deflateFilter.resetState();
- compressedValSerializer.serialize(val);
- deflateOut.flush();
- deflateFilter.finish();
- } else {
- //序列化value值(不压缩),并将其写入缓存buffer中
- uncompressedValSerializer.serialize(val);
- }
- //将这条记录写入文件流
- checkAndWriteSync(); // sync
- out.writeInt(buffer.getLength()); // total record length
- out.writeInt(keyLength); // key portion length
- out.write(buffer.getData(), 0, buffer.getLength()); // data
- }
- //添加一条记录(key-value,二进制值)
- public synchronized void appendRaw(byte[] keyData, int keyOffset, int keyLength, ValueBytes val) throws IOException {
- if (keyLength < 0)
- throw new IOException("negative length keys not allowed: " + keyLength);
- int valLength = val.getSize();
- checkAndWriteSync();
- //直接将key-value写入文件流
- out.writeInt(keyLength+valLength); // total record length
- out.writeInt(keyLength); // key portion length
- out.write(keyData, keyOffset, keyLength); // key
- val.writeUncompressedBytes(out); // value
- }
- ...
- }
SequenceFile.RecordCompressWriter写入时只压缩key-value对(Record)中的value;
- static class RecordCompressWriter extends Writer {
- ...
- public synchronized void append(Object key, Object val) throws IOException {
- if (key.getClass() != keyClass)
- throw new IOException("wrong key class: "+key.getClass().getName() +" is not "+keyClass);
- if (val.getClass() != valClass)
- throw new IOException("wrong value class: "+val.getClass().getName() +" is not "+valClass);
- buffer.reset();
- //序列化key(将key转化为二进制数组),并写入缓存buffer中
- keySerializer.serialize(key);
- int keyLength = buffer.getLength();
- if (keyLength < 0)
- throw new IOException("negative length keys not allowed: " + key);
- //序列化value值(不压缩),并将其写入缓存buffer中
- deflateFilter.resetState();
- compressedValSerializer.serialize(val);
- deflateOut.flush();
- deflateFilter.finish();
- //将这条记录写入文件流
- checkAndWriteSync(); // sync
- out.writeInt(buffer.getLength()); // total record length
- out.writeInt(keyLength); // key portion length
- out.write(buffer.getData(), 0, buffer.getLength()); // data
- }
- /** 添加一条记录(key-value,二进制值,value已压缩) */
- public synchronized void appendRaw(byte[] keyData, int keyOffset,
- int keyLength, ValueBytes val) throws IOException {
- if (keyLength < 0)
- throw new IOException("negative length keys not allowed: " + keyLength);
- int valLength = val.getSize();
- checkAndWriteSync(); // sync
- out.writeInt(keyLength+valLength); // total record length
- out.writeInt(keyLength); // key portion length
- out.write(keyData, keyOffset, keyLength); // 'key' data
- val.writeCompressedBytes(out); // 'value' data
- }
- } // RecordCompressionWriter
- ...
- }
SequenceFile.BlockCompressWriter 写入时将一批key-value对(Record)压缩成一个Block;
- static class BlockCompressWriter extends Writer {
- ...
- void init(int compressionBlockSize) throws IOException {
- this.compressionBlockSize = compressionBlockSize;
- keySerializer.close();
- keySerializer.open(keyBuffer);
- uncompressedValSerializer.close();
- uncompressedValSerializer.open(valBuffer);
- }
- /** Workhorse to check and write out compressed data/lengths */
- private synchronized void writeBuffer(DataOutputBuffer uncompressedDataBuffer) throws IOException {
- deflateFilter.resetState();
- buffer.reset();
- deflateOut.write(uncompressedDataBuffer.getData(), 0, uncompressedDataBuffer.getLength());
- deflateOut.flush();
- deflateFilter.finish();
- WritableUtils.writeVInt(out, buffer.getLength());
- out.write(buffer.getData(), 0, buffer.getLength());
- }
- /** Compress and flush contents to dfs */
- public synchronized void sync() throws IOException {
- if (noBufferedRecords > 0) {
- super.sync();
- // No. of records
- WritableUtils.writeVInt(out, noBufferedRecords);
- // Write 'keys' and lengths
- writeBuffer(keyLenBuffer);
- writeBuffer(keyBuffer);
- // Write 'values' and lengths
- writeBuffer(valLenBuffer);
- writeBuffer(valBuffer);
- // Flush the file-stream
- out.flush();
- // Reset internal states
- keyLenBuffer.reset();
- keyBuffer.reset();
- valLenBuffer.reset();
- valBuffer.reset();
- noBufferedRecords = 0;
- }
- }
- //添加一条记录(key-value,对象值需要序列化)
- public synchronized void append(Object key, Object val) throws IOException {
- if (key.getClass() != keyClass)
- throw new IOException("wrong key class: "+key+" is not "+keyClass);
- if (val.getClass() != valClass)
- throw new IOException("wrong value class: "+val+" is not "+valClass);
- //序列化key(将key转化为二进制数组)(未压缩),并写入缓存keyBuffer中
- int oldKeyLength = keyBuffer.getLength();
- keySerializer.serialize(key);
- int keyLength = keyBuffer.getLength() - oldKeyLength;
- if (keyLength < 0)
- throw new IOException("negative length keys not allowed: " + key);
- WritableUtils.writeVInt(keyLenBuffer, keyLength);
- //序列化value(将value转化为二进制数组)(未压缩),并写入缓存valBuffer中
- int oldValLength = valBuffer.getLength();
- uncompressedValSerializer.serialize(val);
- int valLength = valBuffer.getLength() - oldValLength;
- WritableUtils.writeVInt(valLenBuffer, valLength);
- // Added another key/value pair
- ++noBufferedRecords;
- // Compress and flush?
- int currentBlockSize = keyBuffer.getLength() + valBuffer.getLength();
- //block已满,可将整个block进行压缩并写入文件流
- if (currentBlockSize >= compressionBlockSize) {
- sync();
- }
- }
- /**添加一条记录(key-value,二进制值,value已压缩). */
- public synchronized void appendRaw(byte[] keyData, int keyOffset, int keyLength, ValueBytes val) throws IOException {
- if (keyLength < 0)
- throw new IOException("negative length keys not allowed");
- int valLength = val.getSize();
- // Save key/value data in relevant buffers
- WritableUtils.writeVInt(keyLenBuffer, keyLength);
- keyBuffer.write(keyData, keyOffset, keyLength);
- WritableUtils.writeVInt(valLenBuffer, valLength);
- val.writeUncompressedBytes(valBuffer);
- // Added another key/value pair
- ++noBufferedRecords;
- // Compress and flush?
- int currentBlockSize = keyBuffer.getLength() + valBuffer.getLength();
- if (currentBlockSize >= compressionBlockSize) {
- sync();
- }
- }
- } // RecordCompressionWriter
- ...
- }
根据三种压缩算法,共有三种类型的SequenceFile文件格式:
1). Uncompressed SequenceFile

2). Record-Compressed SequenceFile

3). Block-Compressed SequenceFile