MMU_段式映射
首先, 段式映射的示意图如下:

该例程有5个文件构成:
head.s-------------入口程序
mmu.lds-----------连接文件
init.c---------------初始化文件
makefile-----------编译连接
leds.c--------------主程序
由入口函数开始:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
@*************************************************************************
@ File:
head
.S
@ 功能:设置SDRAM,将第二部分代码复制到SDRAM,设置页表,启动MMU,
@ 然后跳到SDRAM继续执行
@*************************************************************************
.text
.global _start
_start:
ldr sp, =4096 @ 设置栈指针,以下都是C函数,调用前需要设好栈
bl disable_watch_dog @ 关闭WATCHDOG,否则CPU会不断重启
bl memsetup @ 设置存储控制器以使用SDRAM
bl copy_2th_to_sdram @ 将第二部分代码复制到SDRAM --- 注释 1
bl create_page_table @ 设置页表 --- 注释 2
bl mmu_init @ 启动MMU --- 注释 3
ldr sp, =0xB4000000 @ 重设栈指针,指向SDRAM顶端(使用虚拟地址)
ldr pc, =0xB0004000 @ 跳到SDRAM中继续执行第二部分代码
halt_loop:
b halt_loop
|
注释1:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
//file: init.c
void
copy_2th_to_sdram(
void
)
{
unsigned
int
*pdwSrc = (unsigned
int
*)2048;
unsigned
int
*pdwDest = (unsigned
int
*)0x30004000;
while
(pdwSrc < (unsigned
int
*)4096)
{
*pdwDest = *pdwSrc;
pdwDest++;
pdwSrc++;
}
}
|
|
1
2
3
4
5
|
//file: mmu.lds
SECTIONS {
firtst 0x00000000 : { head.o init.o }
second 0xB0004000 : AT(2048) { leds.o }
}
|
由mmu.lds可知, 第二部分的代码链接地址为2048, 加载地址为 0xB000 4000. 而init.c中将第二段的代码放到了 0x3000 4000. 我们利用mmu将 物理地址0x3000 4000 映射到 虚拟地址0xB000 4000.
注释2:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
void
create_page_table(
void
)
{
/*
* 用于段描述符的一些宏定义
*/
#define MMU_FULL_ACCESS (3 << 10) /* 访问权限 */
#define MMU_DOMAIN (0 << 5) /* 属于哪个域 */
#define MMU_SPECIAL (1 << 4) /* 必须是1 */
#define MMU_CACHEABLE (1 << 3) /* cacheable */
#define MMU_BUFFERABLE (1 << 2) /* bufferable */
#define MMU_SECTION (2) /* 表示这是段描述符 */
#define MMU_SECDESC (MMU_FULL_ACCESS | MMU_DOMAIN | MMU_SPECIAL | \
MMU_SECTION)
#define MMU_SECDESC_WB (MMU_FULL_ACCESS | MMU_DOMAIN | MMU_SPECIAL | \
MMU_CACHEABLE | MMU_BUFFERABLE | MMU_SECTION)
#define MMU_SECTION_SIZE 0x00100000
unsigned
long
virtuladdr, physicaladdr;
unsigned
long
*mmu_tlb_base = (unsigned
long
*)0x30000000;
/*
* Steppingstone的起始物理地址为0,第一部分程序的起始运行地址也是0,
* 为了在开启MMU后仍能运行第一部分的程序,
* 将0~1M的虚拟地址映射到同样的物理地址
*/
virtuladdr = 0;
physicaladdr = 0;
*(mmu_tlb_base + (virtuladdr >> 20)) = (physicaladdr & 0xFFF00000) | \
MMU_SECDESC_WB;
/*
* 0x56000000是GPIO寄存器的起始物理地址,
* GPBCON和GPBDAT这两个寄存器的物理地址0x56000050、0x56000054,
* 为了在第二部分程序中能以地址0xA0000050、0xA0000054来操作GPFCON、GPFDAT,
* 把从0xA0000000开始的1M虚拟地址空间映射到从0x56000000开始的1M物理地址空间
*/
virtuladdr = 0xA0000000;
physicaladdr = 0x56000000;
*(mmu_tlb_base + (virtuladdr >> 20)) = (physicaladdr & 0xFFF00000) | \
MMU_SECDESC;
/*
* SDRAM的物理地址范围是0x30000000~0x33FFFFFF,
* 将虚拟地址0xB0000000~0xB3FFFFFF映射到物理地址0x30000000~0x33FFFFFF上,
* 总共64M,涉及64个段描述符
*/
virtuladdr = 0xB0000000;
physicaladdr = 0x30000000;
while
(virtuladdr < 0xB4000000)
{
*(mmu_tlb_base + (virtuladdr >> 20)) = (physicaladdr & 0xFFF00000) | \
MMU_SECDESC_WB;
virtuladdr += 0x100000;
//段描述符对应1M空间, 所以每次加0x100000
physicaladdr += 0x100000;
}
}
|
其中 mmu_tlb_base 被定义unsigned long 类型, 刚好占4byte 它和页表描述符大小相同. mmu_tlb_base的值为 0x3000 0000, 表示一级页表被放置在了SDRAM的开头处.
最能代表 页表结构的一句是:
|
1
|
*(mmu_tlb_base + (virtuladdr >> 20)) = (physicaladdr & 0xFFF00000) | MMU_SECDESC_WB;
|
MVA的[31:20]等于页表索引(table index), 对应的代码是 (virtualaddr >> 20)
PA[31:20]等于段描述符的[31:20], 对应的代码是 (physicaladdr & 0xFFF00000)
简单来说就是根据MVA和TTB寄存器找到一级页表中的段描述符, 该段描述符里存放的就是实际的物理地址, 我们的程序只是 1. 配置了 TTB寄存器 2. 把物理地址存放到了段描述符里
还有, 我们映射的区域是0x3000 0000 到 0xB000 0000, 为什么代码从0x3000 4000开始存放呢? 因为页表项最多有4096个, 每个4byte, 共16k, 所以前16k 保留, 防止覆盖掉页表区域.
注释3:
mmu部分不详细解释他的各种配置了, 最重要的是将我们定好的页表基址0x3000 0000 , 写入cp15的页表基址寄存器
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
/*
* 启动MMU
*/
void
mmu_init(
void
)
{
unsigned
long
ttb = 0x30000000;
__asm__(
"mov r0, #0\n"
"mcr p15, 0, r0, c7, c7, 0\n"
/* 使无效ICaches和DCaches */
"mcr p15, 0, r0, c7, c10, 4\n"
/* drain write buffer on v4 */
"mcr p15, 0, r0, c8, c7, 0\n"
/* 使无效指令、数据TLB */
"mov r4, %0\n"
/* r4 = 页表基址 */
"mcr p15, 0, r4, c2, c0, 0\n"
/* 设置页表基址寄存器 */
"mvn r0, #0\n"
"mcr p15, 0, r0, c3, c0, 0\n"
/* 域访问控制寄存器设为0xFFFFFFFF,
* 不进行权限检查
*/
/*
* 对于控制寄存器,先读出其值,在这基础上修改感兴趣的位,
* 然后再写入
*/
"mrc p15, 0, r0, c1, c0, 0\n"
/* 读出控制寄存器的值 */
/* 控制寄存器的低16位含义为:.RVI ..RS B... .CAM
* R : 表示换出Cache中的条目时使用的算法,
* 0 = Random replacement;1 = Round robin replacement
* V : 表示异常向量表所在的位置,
* 0 = Low addresses = 0x00000000;1 = High addresses = 0xFFFF0000
* I : 0 = 关闭ICaches;1 = 开启ICaches
* R、S : 用来与页表中的描述符一起确定内存的访问权限
* B : 0 = CPU为小字节序;1 = CPU为大字节序
* C : 0 = 关闭DCaches;1 = 开启DCaches
* A : 0 = 数据访问时不进行地址对齐检查;1 = 数据访问时进行地址对齐检查
* M : 0 = 关闭MMU;1 = 开启MMU
*/
/*
* 先清除不需要的位,往下若需要则重新设置它们
*/
/* .RVI ..RS B... .CAM */
"bic r0, r0, #0x3000\n"
/* ..11 .... .... .... 清除V、I位 */
"bic r0, r0, #0x0300\n"
/* .... ..11 .... .... 清除R、S位 */
"bic r0, r0, #0x0087\n"
/* .... .... 1... .111 清除B/C/A/M */
/*
* 设置需要的位
*/
"orr r0, r0, #0x0002\n"
/* .... .... .... ..1. 开启对齐检查 */
"orr r0, r0, #0x0004\n"
/* .... .... .... .1.. 开启DCaches */
"orr r0, r0, #0x1000\n"
/* ...1 .... .... .... 开启ICaches */
"orr r0, r0, #0x0001\n"
/* .... .... .... ...1 使能MMU */
"mcr p15, 0, r0, c1, c0, 0\n"
/* 将修改的值写入控制寄存器 */
:
/* 无输出 */
:
"r"
(ttb) );
}
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
// leds.c: 循环点亮4个LED
/* 属于第二部分程序,此时MMU已开启,使用虚拟地址
*/
#define GPFCON (*(volatile unsigned long *)0xA0000050) // 物理地址0x56000050对应虚拟地址 0xA000 0050
#define GPFDAT (*(volatile unsigned long *)0xA0000054) // 物理地址0x56000054对应虚拟地址 0xA000 0054
#define GPF4_out (1<<(4*2))
#define GPF5_out (1<<(5*2))
#define GPF6_out (1<<(6*2))
/*
* wait函数加上“static inline”是有原因的,
* 这样可以使得编译leds.c时,wait嵌入main中,编译结果中只有main一个函数。
* 于是在连接时,main函数的地址就是由连接文件指定的运行时装载地址。
* 而连接文件mmu.lds中,指定了leds.o的运行时装载地址为0xB4004000,
* 这样,head.S中的“ldr pc, =0xB4004000”就是跳去执行main函数。
*/
static
inline
void
wait(unsigned
long
dly)
{
for
(; dly > 0; dly--);
}
int
main(
void
)
{
unsigned
long
i = 0;
GPFCON = GPF4_out|GPF5_out|GPF6_out;
// 将LED1,2,4对应的GPF4/5/6三个引脚设为输出
while
(1)
{
wait(30000);
GPFDAT = (~(i<<4));
// 根据i的值,点亮LED1,2,4
if
(++i == 8)
i = 0;
}
return
0;
}
|
链接文件:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
//file: mmu.lds
objs := head.o init.o leds.o
all : $(objs)
arm-none-eabi-ld -Tmmu.lds -o mmu_elf $^
arm-none-eabi-objcopy -O binary -S mmu_elf $@
arm-none-eabi-objdump -D -m arm mmu_elf > mmu.dis
%.o:%.c
arm-none-eabi-gcc -Wall -O2 -c -o $@ $<
%.o:%.S
arm-none-eabi-gcc -Wall -O2 -c -o $@ $<
clean:
rm -rf mmu.bin mmu_elf mmu.dis *.o
|
代码执行示意:
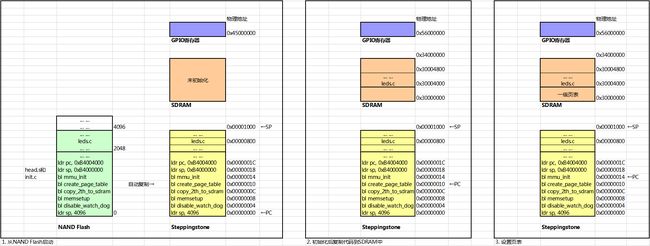

最后说一下TLB和cache:
TLB: 上述地址转换只经过了一级转换, 但是每次读/写数据都要访问两次sdram, 第一次取地址, 第二次读写数据. 如果是两级页表转换的话则需要每次读/写都要访问三次sdram, 为了提高访问效率使用TLB来存储要用到的若干条页表条目(段/大页/小页/极小页描述符).通常在启动mmu之前先使无效整个TLB,
改变页表时, 使无效所涉及的虚拟地址对应的TLB中的条目
cache: 在cpu和通用寄存器之间设置的存储器, 可以把正在执行的指令附近的指令或数据从主存调入这个存储器来提高速度