中文化和国际化问题权威解析之一:字符编码发展历程
前几天看文初的《精武门之Web安全研讨会首日感受 》,说到利用字符集攻击时提到以前宝宝写的一篇有关国际化的文章,趁机再次拜读了宝宝的这篇大作,不得不感慨宝宝的写作功底,无敌!这么好的文章不分享出来实在是太可惜了,在此将宝宝的大作转帖于此;
作者序
在我开发 Java 程序的几年中,遇到得最多,也是别人向我提问最多的问题,就是各种各样看似稀奇古怪的中文乱码问题了。网上也有许多解释和解决 Java 中文问题的文章,但水平参差不齐,有一些文章甚至是错误的。
此外,我们公司自己的 Java 程序从一开始就采用了错误的方式处理中文问题,虽能解一时之急,却引出了越来越多的深远的问题。每当我听到有的同事还在讨论如何特殊处理双字节的中文 GB 码,就感慨他们思路的狭隘。试问,今天我们可以用特殊的方式处理我们所熟悉的中文编码,可是今后我们怎样才能应付日文版、韩文版、或世界其它国家语言的产品开发呢?
在我看来,与其说这些问题是 “ 中文化问题 ” ,不如说是 “ 国际化问题 ” 。所谓的 “ 汉化 ” 这 种说法已经随时代远去了。想想看,这个词带有明显的小农经济的色彩:自家汉化自家用,哪管世界变化多。经过汉化的软件,常常意味着:版本落后、不兼容、不 稳定。为什么会这样呢?根本原因是,从软件的设计阶段,就没有考虑国际用户的需要,没有采用国际通用的标准。事后要弥补自然难上加难。
所以让我们把眼光放开,想一想 “ 国际化 ” 。当然国际化的目的还是生产出 “ 汉化 ” 的软件,但我们可以用同样的方法 “ 韩化 ” 、 “ 日化 ” 、 “ 阿拉伯化 ” ,统称为 “ 本地化 ” —— 这就是 “ 国际化 ” 的目的。国际化和本地化有两个很体面的英文缩写: I18n ( Internationalization )和 L10n ( Localization )。
想要开发出国际化的软件产品,首先要了解国际标准,而不是使用东拼西凑的权宜之计。本文首先从相关国际标准的讨论切入,相信正确地理解和应用这些标准,所有的 “ 中文化问题 ” 或 “ 国际化问题 ” 都会迎刃而解。
字符编码简介
ASCII 码
从学计算机的那天开始,老师就告诉我们在计算机里面,所有的英文字母都对应到一个数字编码,这就是 ASCII 码( American Standard Code for Information Interchange )。 ASCII 码是很久很久以前( 1968 年)制定的。它只使用了一个 8 位字节中的低 7 位,总共是 127 个编码位。这样的方案很快就不够使用了。

单字节编码的发展
在 80 年代早期,一些现在流行的标准(如 ISO 8859 和 Unicode )还未出现。那时为了支持多种地区的语言,各大组织机构或 IT 厂商开始发明它们自己的编码方案,以便弥补 ASCII 编码的不足。一时间,各种互不相容的字符编码方案成百花齐放之势。
为了避免混乱, ISO 组织在 1998 年之后,陆续发表了一系列代号为 8859 的标准,作为 ASCII 编码的标准扩展,终于统一了单字节的西方字符的编码。 ISO 是设在瑞士的国际标准化组织的简称( International Organization for Standardization )。
ISO-8859-1 ( Latin1 - 西欧字符)
ISO-8859-1 覆盖了大多数西欧语言,包括:法国、西班牙、葡萄牙、意大利、荷兰、德国、丹麦、瑞典、挪威、芬兰、冰岛、爱尔兰、苏格兰、英格兰等,因而也涉及到了整个美洲大陆、澳大利亚和非洲很多国家的语言。
此外, ISO-8859-1 后来被采纳为 ISO-10646 标准(后面会讲到)的首页,换句话说, Unicode 的最开头 256 个字符编码和 ISO-8859-1 是一一对应的。正是由于这个特殊性,使很多人产生了对 ISO-8859-1 编码的误用。

ISO-8859 标准还包括:
- ISO-8859-2 ( Latin2 - 中、东欧字符)
- ISO-8859-3 ( Latin3 - 南欧字符)
- ISO-8859-4 ( Latin4 - 北欧字符)
- ISO-8859-5 ( Cyrillic - 斯拉夫语)
- ISO-8859-6 ( Arabic - 阿拉伯语)
- ISO-8859-7 ( Greek - 希腊语)
- ISO-8859-8 ( Hebrew - 希伯来语)
- ISO-8859-9 ( Latin5 )
- ISO-8859-10 ( Latin6 )
- ISO-8859-11 ( Thai - 泰国语)
- ISO-8859-12 (保留)
- ISO-8859-13 ( Latin7 )
- ISO-8859-14 ( Latin8 )
- ISO-8859-15 ( Latin9 )
但是 ISO 8859 系列标准的字符编码,还是互不相容,不可能同时使用的。毕竟它们只是单字节的编码方案。而且,它们和多字节的编码方案如中文编码 GB2312 和 BIG5 也是不相容的。那些欧洲字符(最高位为 1 的字符),在 GB2312 和 BIG5 中被认为是双字节汉字编码的首字节。
多字节编码的发展
单字节编码只有 256 个码位( 28 =256 ),而中文字符何止千千万,单字节编码不可能满足中文编码的需要。于是为了适应东方文字信息处理的需要, ISO 又制定了 ISO 2022 标准( Character code structure and extension techniques ),提供了七位与八位编码字符集的扩充方法的标准。我国根据 ISO 2022 制定了国家标准 GB2311 —— 《信息交换用七位编码字符集的扩充方法》,并根据该标准制定了国家标准 GB2312-80 编码。其他东方国家和地区也制定了各自的字符编码标准,如日本的 JIS0208 ,韩国的 KSC5601 ,台湾地区的 CNS11643 等。
BIG5
BIG5 是从 CNS11643 的早期版本发展而来的,虽然没有包括 CNS11643 的全部内容,但却是目前台湾、香港地区普遍使用的一种繁体汉字的市场标准,包括 440 个符号,一级汉字 5401 个、二级汉字 7652 个,共计 13060 个汉字。
GB2312-80
全称是《信息交换用汉字编码字符集 基本集》, 1980 年发布,是中文信息处理的国家标准,在大陆及海外使用简体中文的地区(如新加坡等)是强制使用的唯一中文编码。
· 双字节编码
· A1-A9 :符号区,包含 682 个符号
· B0-F7 :汉字区,包含 6763 个汉字
GB2312 码共收录 6763 个简体汉字、 682 个符号,其中汉字部分:一级字 3755 ,以拼音排序,二级字 3008 ,以偏旁排序。该标准的制定和应用为规范、推动中文信息化进程起了很大作用。
GBK
汉字内码扩展规范( GBK )是国家技术监督局 1995 年为中文 Windows 95 所制定的新的汉字内码规范。
· 双字节编码, GB2312-80 的扩充,在码位上和 GB2312-80 兼容。
· 范围: 8140 ~ FEFE (剔除 xx7F )共 23940 个码位。
· 包含 21003 个汉字,包含了 ISO 10646 中的全部中日韩汉字,简、繁体字融于一库。
严格说, GBK 不能算是国家标准,最多算是一个商业标准。而 GB18030 才是真正的国家标准。
GB18030-2000
全称是《信息交换用汉字编码字符集》,是我国的强制标准,所有不支持 GB18030 标准的软件将不能作为产品出售。
· 单字节、双字节、四字节编码。
· 向下与 GB2312 编码兼容。
· 支持 GB 13000.1-1993 中的全部中、日、韩( CJK )统一汉字字符和全部 CJK 统一汉字扩展 A 的字符。
虽然 GB18030 标准非常强大,但它是一个中国大陆的标准。在编码上,除了和 GB2312 以外,还是不能和世界上其它任何一种字符编码统一。
终极标准 —— Unicode 和 ISO 10646
前面所讲的一切字符编码方案,都是针对局部地区或少数语言文字的,没有办法同时表达所有的语言文字,或在多种语言平台上交换。这对今天极其频繁的国际信息交流是不相称的。
为了提高计算机的信息处理和交换功能,使得世界各国的文字都能在计算机中处理,从 1984 年起, ISO 组织就开始研究制定一个全新的标准:通用多八位编码字符集( Universal Multiple-Octet Coded Character Set ),简称 UCS 。标准的编号为: ISO 10646 。这一标准为世界各种主要语言的字符 ( 包括简体及繁体的中文字 ) 及附加符号,编制统一的内码。
统一码( Unicode )是 Universal Code 的缩写,是由另一个叫 “Unicode 学术学会 ” ( The Unicode Consortium )的机构制定的字符编码系统。 Unicode 与 ISO 10646 国际编码标准从内容上来说是同步一致的。
Unicode 是 Java 语言和 XML 的基础,所以我们要稍微详细地介绍一下 Unicode 以及 ISO 10646 标准。
注意: 不够耐心的读者可以跳过本章的余下部分。但显然了解本章所描述的 Unicode 及相关编码的技术细节,有利于你更好地理解和应用 Unicode 。
Unicode 和 ISO 10646 的关系
在 1991 年, Unicode 学术学会与 ISO 国际标准化组织决定共同制订一套适用于多种语言文本的通用编码标准。 Unicode 与 ISO 10646 国际编码标准于 1992 年 1 月正式合作发展一套通用编码标准。自此,两个组织便一直紧密合作,同步发展 Unicode 及 ISO 10646 国际编码标准。
| ISO 10646 ( UCS ) |
Unicode |
| 1993 年, ISO 组织发表 ISO 10646 国际编码标准的第一个版本,全名是 ISO/IEC 10646-1:1993 。它收录了 20902 个表意字符( ideograph ,中日韩文均属表意字符)。 |
同年, Unicode 学术学会根据 ISO/IEC 10646-1:1993 修订了 Unicode 1.0 ,发布 Unicode 1.1 。 |
| 不断改善和修订 ISO 10646 标准。 |
1996 年发表 Unicode 2.0 , 1998 年发表 Unicode 2.1 ,根据 ISO 10646 做了一些改善和修订,新增了欧元符号。 |
| 2000 年 10 月发表了 ISO 10646 第二版的第一部分: ISO/IEC 10646-1:2000 ,新增收了 6,582 个表意字符于扩展区 A 中( CJK Unified Ideographs Extension A )。 |
2000 年 2 月,发表 Unicode 3.0 ,也包含了同样的 CJK Ext A 。 |
| 2001 年,发表了 ISO/IEC 10646 的第二部分,增收了 42711 个表意字符于扩展区 B 里。 |
2001 年, Unicode 发表 3.1 版,将 CJK Ext B 纳入新版 Unicode 中。 |
虽然两个组织保持如此密切的合作关系,但 Unicode 和 ISO 10646 还是有区别的。 ISO 10646 着重定义字符编码,而 Unicode 则在此基础上,为这些字符及编码数据提出应用的方法以及对语义数据作补充。
UCS 的结构
UCS 的结构是一个四维的编码空间,每一维由一个字节(八位二进制位)组成,范围是 00 到 FF 。总体上分为 128 个群组 (Group 00-7F) ,每一群组由 256 个平面 (Plane 00-FF) 组成,每一平面有 256 行 (Row 00-FF) ,每一行 256 个编码位 (Cell 00-FF) 。所以,每一平面包括 65,536 个字符位 (Character Position 0000-FFFF) 。
整个编码字符集的每个字符都由 4 个字节,按 “ 组 - 面 - 行 - 列 ” 的顺序表示。所以 UCS 的可编码空间为: 128 × 256 × 256 × 256 = 231 。
UCS 将其第一个平面 (00 群组中的 00 平面 ) 称作基本多语种平面( Basic Multilingual Plane , BMP )。
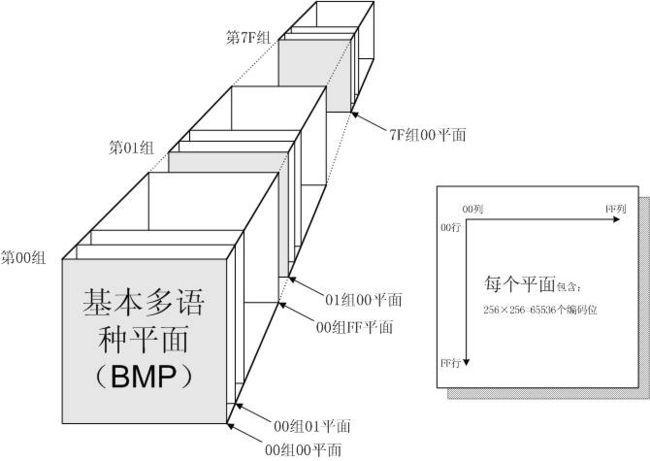
在 UCS 中,目前只有 00 组是重要的, Unicode 学术学会断言,在可以预见的将来,甚至不可能用完 00 组中的前 17 个平面( 00 平面到 10 平面)。因此, Unicode 只定义了 ISO 10646 的第 00 组的前 17 个平面。事实上,目前绝大多数字符,都分配在第 00 平面 BMP 中。
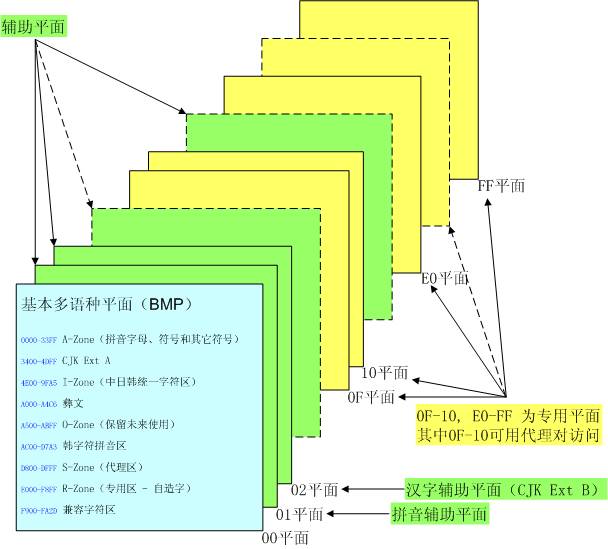
下表中列出了 BMP 中的字符分配情况:
| 区间 |
描述 |
| ( 0000-1FFF )基本拼音字符区 |
包括所有拼读文字的字母拼音和音标。它的字符集一般较小,如:拉丁文、西里尔文、希腊文、希伯来文、阿拉伯文、泰文、天成文书(梵文)等。 |
| ( 2000-28FF )符号区 |
包括许多种用于标点、数学、化学、科技及其它特殊用途上的 “ 符号 ” 和 “ 丁贝符 ” (示意图形符号)。 |
| ( 2E80-33FF )中日韩语音及符号区 |
包括用于中国、日本、韩国语言中的标点、符号、字根(笔画)及发音等字符。 |
| ( 3400-9FA5 )中日韩汉字字符区 |
由 27,484 个中日韩(越)的统一汉字组成。 |
| ( A000-A4C6 )彝族字符区 |
由 1,165 个中国南方彝族音节和 50 个其字根组成。 |
| ( AC00-D7A3 )韩字符拼音区 |
由 11,172 个预先组合的韩字符拼音音节组成。 |
| ( D800-DFFF )代理区 |
这个区被平分为 1024 个 “ 高半代理区 ” ( D800-DBFF )码位和 1024 个 “ 低半代理区 ” ( DC00-DFFF )码位,用来形成代理对,可以得到超过一百万个扩充编码位。 |
| ( E000-F8FF )私人专用区 |
包含 6,400 个编码位,用于用户或开发商自行定义的字符编码。 |
| ( F900-FA2D )兼容字符区 |
包括一些被许多行业协会和国家标准广泛使用的字符,但在 Unicode 编码中有不同的表现形式。包含一些专用字符。 |
UCS 的表现形式
UCS 有两种方式来表示一个字符编码:四字节正规形式( UCS-4 , Four-octet canonical form )和双字节基本平面形式( UCS-2 , Two-octet BMP form )。
UCS-4 —— 四字节正规形式
UCS-4 用 4 个字节来表示一个字符。第一个字节表示组( Group ),第二表示平面( Plane ),第三表示行( Row ),第四表示单元号或列( Cell )。
UCS-2 —— 双字节基本平面形式
当系统只使用 BMP 的字符码时,可以省略群组和平面中的八位,将字符码由 32 个位缩短为 16 个位( 2 个字节)。标记为 UCS-2 。
Unicode 和 UCS-2 同样采用 16 位编码。所以一般 可以把 Unicode 和 UCS-2 看作是同一样东西 。
代理对( Surrogate Pair )
UCS-4 定义了 4 个字节表示一个字符,用来应付将来的扩展是绰绰有余。可是 Unicode 和 UCS-2 只定义了 2 个字节,却很容易用尽。代理对( Surrogate Pair )的设计在这种背景下应运而生。
UCS-2 在 BMP 中开辟了一个特殊的区间( D800 - DFFF ) -- 代理区,并平分成两个区,分别称为高半代理区( High-half Zone , D800 - DBFF ),和低半代理区( Low-half Zone , DC00 - DFFF ),各有 1024 个码位。使用时,从高低两个代理区中各取一个编码组成一个四字节的代理,来表示一个在 BMP 以外平面上的编码字符位。这样一来,总共可以多表示 1024×1024 个字符,映射到 00 群组中的 01 到 10 平面(共 16 个平面)。
代理对提供了用 BMP 的 2 字节编码来表示在基本多文种平面( BMP )之外的 16 个平面编码的机制。一些不常用的字符可以用代理对表示。目前,只有 ISO/IEC 10646-2:2001 和 Unicode 3.1 才使用到代理对。
高半代理区和低半代理区的划分,使编码位相互区分开。非代理区字符一定不会在这个区里。因为高半代理区和低半代理区不相交,所以很容易决定字符值的边界。一个完好的文本中,高半代理码和低半代理码总是按先后成对出现。
如果在实现上没有删除代理码或在代理码对中插入字符,数据的完整性就可得到保证。即使数据有残损,也只是局部的。一个残缺的码只影响一个字符。因为高半代理区和低半代理区不相交,且成对出现,错码不会传到文本的其它部分。
具体来说,一个代理对( H , L )由码值为 D800-DBFF 的高半代理码 H 和码值为 DC00-DFFF 低半代理码 L 组成。将一个字符映射到 UCS-4 码位中。假设 N 是 UCS-4 码值,则有:(以下所有数字均为 16 进制)
N = (H - D800) × 400 + (L - DC00) + 10000
于是得到 N 的码值为 10000 到 10FFFF 。
注意
Unicode 3.0 没有用到代理对,直到 3.1 才增加了 CJK Ext B ,用到了 02 平面,需要使用代理对才能访问。但 99.99% 的情况下,根本用不到那些字。此外, JDK1.4 只支持到 Unicode 3.0 ,所以目前 Java 还不能应用代理对。
UTF 编码
UTF 为 UCS Transformation Format 的缩写,意为 “UCS 转换格式 ” 。 UCS 只是一个字形和内码上的标准,并没有定义实际在计算机上存取的方法,而 UTF 便定义了一整套的计算机存取 UCS 编码的转换格式,并考虑了与其它编码方式兼容。常用的格式有 UTF-8 和 UTF-16 。有时也用到 UTF-7 来进行 7 位数据传输。
UTF-16
UTF-16 是用定长 16 位( 2 字节)来表示的 UCS-2 或 Unicode 转换格式。它将 Unicode 的编码值变成 2 字节的 Big-endian (高位字节在前,低位字节在后)或 Little-endian (低位字节在前,高位字节在后)编码。 UTF-16 利用代理对来访问 BMP 之外的字符编码。
Java 使用 Big-endian 系统,而 Intel 系列处理器内部使用 Little-endian 系统(学汇编语言和 C 语言的人都知道)。
例如: “ 中国 ” 两字, Unicode 是 4E2D 56FD ,在 Windows 上用 UTF-16 编码,结果为四个字节: 2D 4E FD 56 ;如果使用 Java 输出,结果为: 4E 2D 56 FD 。
使用 UTF-16 有什么缺点呢?很显然,
1. 所有原本 1 个字节就可以表示的西方字符,现在要用 2 个字节来表示,体积大了一倍。
2. 学过 C 的人都知道, 0x00 代表 C 字符串的结尾。但是用 UTF-16 来表示单字节字符( ISO-8859-1 )时,高位字节为 0x00 。这样就会使 C 语言库函数发生误判。用 UTF-16 表示文件名、网址等,全引出无数的问题。
3. 字符的边界不好找。程序处理时必须从字符串的头部开始扫描,才可能正确地找出一个字符的边界,效率较低。此外,万一坏掉一个字节,这个字节之后的字符都会错位,坏掉一片。
所有的这些问题,在 UTF-8 中都不存在。
但是, UTF-16 也有其天然的优点:它直接表现了字符编码的整数值。所以 UTF-16 是最直接的 Unicode 表示法。此外,它是定长的,这大大简化了字符串的操作。 Java 语言就是用 UTF-16 格式将字符存储在内存中的。正是这样,才使 Java 的 Unicode 字符串的操作格外简单高效。
UTF-8
UTF-8 使用了变长技术,在每一个编码区域有不同的字码长度:
1. 对 UCS-2 ,由 1 字节至 3 字节构成;
2. 如果 UCS-2 使用了代理对,则 UTF-8 最长可到 4 字节;
3. 对 UCS-4 ,由 1 字节至 6 字节构成。
因为以字节( 8 位)为组成单元,故称为 “UTF-8 ” 。对于英文文本, UTF-8 的文件大小比其它转换格式都小。
在 UTF-8 内,字符由 1 个至 6 个字节为组合。下表列举出了不同范围的 UCS 码转换成 UTF-8 的规则。英文字母 “x” 代表可以用来记录 Unicode 码值的区域。
| UCS-4 区域(十六进制) |
UTF-8 字节组合(二进制) |
| 0000 0000 —— 0000 007F |
0xxxxxxx |
| 0000 0080 —— 0000 07FF |
110xxxxx 10xxxxxx |
| 0000 0800 —— 0000 FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000 —— 001F FFFF |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 0020 0000 —— 03FF FFFF |
111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 0400 0000 —— 7FFF FFFF |
1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
在 UTF-8 内,
1. 如果一个字节,最高位(第 8 位)为 0 ,表示这是一个 ASCII 字符( 00 - 7F )。可见,所有 ASCII 编码已经是 UTF-8 了。
2. 如果一个字节,以 11 开头,连续的 1 的个数暗示这个字符的字节数,例如: 110xxxxx 代表它是双字节 UTF-8 字符的首字节。
3. 如果一个字节,以 10 开始,表示它不是首字节,需要向前查找才能得到当前字符的首字节。
可见 UTF-8 可以有效地保证数据的完整性,避免出现编码的错位。即使偶然出现 “ 坏字 ” ,也不会影响到后续的文本。
那么 UTF-8 有什么缺点呢?显然,对于在 BMP 中的中文字来说,需要用 3 个字节才能表示,比使用 UTF-16 或直接使用双字节的 GB2312 编码大了 0.5 倍。
上文说了一大通,总结一下,其实很简单:
- 字符编码是抽象字符在计算机中的数字表示。
- 字符编码集( character set ,简称字符集)是一批字符编码的集合。世界上存在大量互不兼容的字符集,给国际交流带来了困难。
- ASCII 码是最古老的字符编码,它总共只定义了 7 位共 128 个字母、数字和符号。但它是其它所有字符编码的基础。
- Unicode 用 16 位整数编码,将世界上所有主要文字的字符统一起来了。如果利用代理对( surrogate pair )最多可以表示从 0 到 1FFFF 的字符。然而绝大多数情况下,只需要用到 0 到 FFFF 之间的字符就足够了。
- Unicode 常用 UTF-8 和 UTF-16 来表示。 7 位的 ASCII 码不用作任何变化,就已经是 UTF-8 了。但 UTF-8 需要用 3 个字节来表示一个汉字。
- ISO 8859 系列字符集,定义了单字节字符编码的标准。其中最特殊的是 ISO-8859-1 编码,它的编码和 Unicode 中最开始的 256 个字符编码完全相同。
- GB18030 编码是中国大陆的国家标准,在字汇上等同于 Unicode ,在编码上和 GB2312 编码以及 GBK 编码兼容。