机器学习:各算法小结(3)
将最近接触的几个机器学习算法小结一下,顺便理理自己的思路。
近年来在机器学习的研究中,对算法的创新主要是在原有的基础上,通过结合不同算法的优点,得到一种更有效的算法,如结合遗传算法的决策树、结合自助法boot-strap诞生的决策树随机森林等。我最近了解的主要是基础算法,然后接触了一些新的算法理念。主要了解了:监督学习的KNN,决策树,支持向量机,神经网络,非监督学习的系统聚类,k-means;以及一些辅助算法或分析如:EM思想,主成分分析、因子分析等。
一、
监督学习是在知道训练数据X的目标Y下进行的。
KNN(k最近邻)是最简单的监督学习算法之一,他是惰性学习(lazy learning)的典型代表,一开始不训练模型,只保存训练数据样本点,在需要对数据进行预测时,计算输入数据与训练数据各样本点间的距离,选取其中最近的k个样本点,根据样本点所属的分类来加权得到自己所属的类别,权重一般为距离的倒数。KNN的算法很简单,而且分类准确性还挺高的。但是缺点也很明显
①每次都需要计算跟所有样本点的距离,所以当数据量过于庞大时,速度会非常慢,这是惰性学习的缺点。
②当样本点存在范围重叠时,分类效果会变得特别不好。
针对这2个缺点,改进的方法主要有剪辑近邻法,将不同类别交界处的样本进行适当筛选,去掉类别混杂的样本,让边界更清晰。这样做的话,既可以缩减样本量,也可以让分类准确性得到提高,步骤主要如下:
①数据分为参照集(Reference)和训练集(Train)
②利用参照集使用KNN算法对训练集中的数据进行预测
③若预测的类别跟其原来所属的类别不一样(说明该样本点很大可能处在两类别的交界处),则将该样本点从训练集中剔除
④获得最终剪辑后的训练集,剪辑样本集TE
KNN算法还有一个要点就是对于K值的选取,如下面这个经典的图:
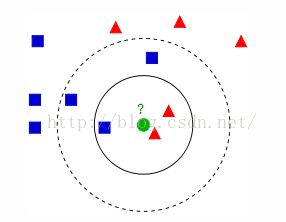
当K为1,3,5时,中间的绿圆点所属的类别都会有差别,所以究竟要选取多大的K值,决定了模型对实际样本预测的准确度。一种最常用的方法是设立验证数据,分别选用不同的k值,得到其对验证数据的分类误差率,综合评价选取分类效果最好的K值,k值一般为2~10或实例个数的平方根。
综合来说,KNN不用建立模型,适用于小样本,还有那些不能一次性获得所有数据的情况,而且其对已分好类的数据是百分百正确的,没有信息损失,其他诸如回归拟合,即使对于已知类别的训练数据,仍然存在偏差,信息损失。
决策树。决策树的树状图易于理解,应用范围相当广范,顾名思义经常用来辅助决策,已经不能简单的称作分类器了。对于决策树的介绍可以看看我的这篇博文:http://blog.csdn.net/databatman/article/details/49406727。这里就简单说下大概,决策树的话现在主要有ID3,C4.5,CART三种版本,其实都是一个东西,只是增加了些小功能,如支持对连续数据进行分类,采用信息增益率结合信息增益,加入了后期对树枝的剪辑功能等,其实本质上都是决策树,只是性能一代代更优而已。如下长这个样子:
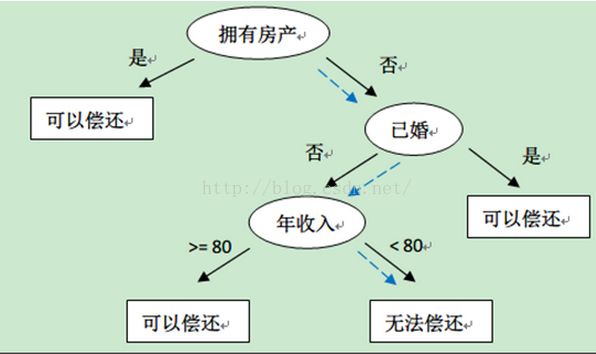
决策树的分类原则是得到一颗尽量小的树,这棵树能满足分类的需求,也就是我们所说的奥坎姆剃刀(最简单的总是最好的),树太宽或太深都不好,决策树的做法是这样的:通过选取信息增益大的为节点来减少树的深度,通过设定信息增益率的阈值来降低树的宽度。
支持向量机(Suppirt VectorMachine,SVM).SVM是基于统计学习理论的一种分类算法,可以说是统计数学近年来的巅峰啊。有着坚实的数学推导作为支持。SVM是一种二元分类器,可以通过多次分类来完成对多元的分类,对噪声鲁棒性很好。SVM的思路主要如下图,在两类数据间,其实是有无数条线能够完成对数据的分类,就像感知器(perceptron)也只是找到一条局部最优解的分类线而已。而SVM找到的超平面(这里是线),中间那条线,他处在两条虚线的中间,离两条虚线的距离一样,而两边虚线则是通过支持向量(support vector)来构建的。

而当数据线性不可分的时候,SVM会将当前维度下线性不可分的数据映射到高维空间,完成分类。如下:
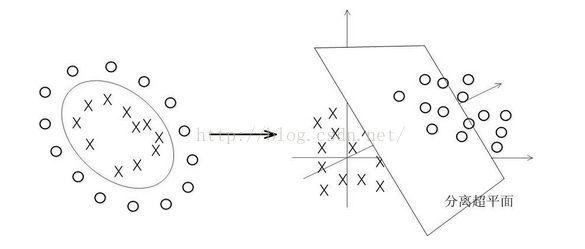
映射的函数叫核函数,有多项式核、高斯核等等。
综合来说,SVM的分类精度特别高,在同类(监督学习算法)算法中,分类精度特别优良,对于SVM的具体推导感兴趣的可以看v_JULY_v大大写的博文【参考文献1】,介绍的特别详细。
神经网络(artificialNeural Network)。神经网络之前沉寂了一段时间,直到2006年由hinton等人提出深度学习框架,一夜之间又变得家喻户晓,当然现在换了名字叫深度学习了。传统的神经网络主要是BP神经网络。BP指Back Propagation反向传播算法。
神经网络是模拟的生物神经元之间传递得到的一种网状模型如下:一般为三层结构:输入层、隐含层(可多层)和输出层,通常3层网络即可拟合相当复杂的函数关系。神经网络只是一种结构,当他运用BP算法来进行拟合,就叫做BP神经网络。BP算法的核心主要是数学中的梯度下降和链式法则,过程主要如图:将训练数据输入,从输出神经元获得预测结果,比对预测结果和真实结果的值,得到误差,通过误差逐渐向上层调整权重,所以叫BP:误差的反向传播算法。

BP神经网络能够对非常复杂的目标函数f(x→y)进行拟合,尤其是在图像识别、语音识别等有广泛的应用,但是当隐含层过多或节点过多时,算法的计算速度特别慢,且初始可供调整的参数过多,有很多选取的trick,需要依赖过多的人工干预,而最终得到的精度还不是特别理想,因而前几年热度逐渐下降。
深度学习。最近稍微关注了下这个,就先浅浅的谈谈。深度学习实质是多层的神经网络(隐含层一般超过十层),如果采用传统的BP算法,需要极其惊人的运行时间,因此大牛们换了一种方法,他们是这么来解决这个问题的:①逐层通过无监督学习来初始化②最后一层采用监督学习来调整。深度学习具有很优异的特征学习能力,能够自动提取数据中的特征,这几乎是科学家们一直以来奋斗的目标,这才叫智能啊!!最近几年在智能车和各种图像识别上得到了广泛的运行,百度还特地成立了一个深度学习的机构,实在火爆。
二、
非监督学习的聚类算法我最近也只了解了下系统聚类和k-means,因为这两比较简单,运用的也特别多。
系统聚类又叫层次聚类。他首先把n个样本点分成n类,然后计算两两之间的距离,将最近的2个样本点聚成一类,之后再次计算各个类别之间的距离,再合并缩小类别,直到最后3类,2类,1类。分类结果形式如下:
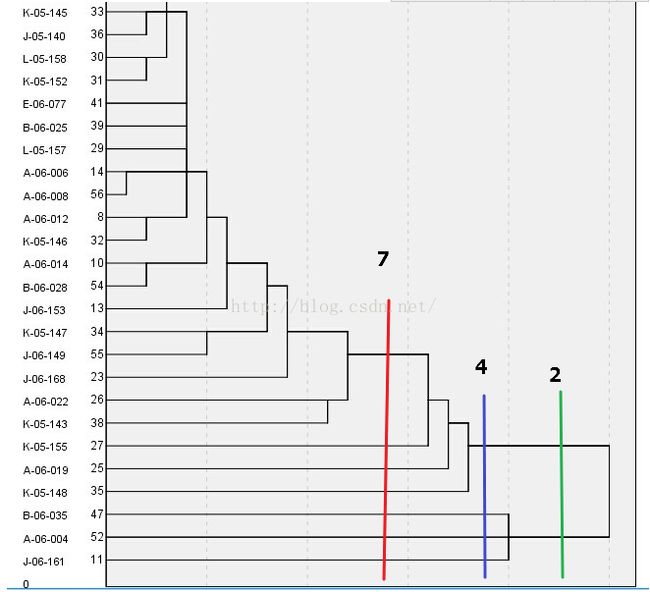
左边的文字代表了各个样本,从右往左看,当你想分成2类时,如图绿线,绿线所接触到的两条线便是所分的两个类别,其下所属的实例分属这两个类别,如倒数3个样本是一类,上面的所有样本是一类。当你想分几类,就在相应的地方进行切割。
系统聚类的分类方法简单直观,核心是距离的度量,距离函数的选取决定了最后的分类精度,主要有最短距离法,最长距离法,重心法,平均值法等,多种距离函数的选取让他具有较灵活的特性。
k-means算法。围绕着k个中心点聚成k个cluster。k-means算法步骤如下:
①首先随机选取k个点作为cluster(群)的中心
②分别计算每个样本点到k个点的距离,分别选取最近的点,聚成k个cluster
③重新计算各个cluster的中心(一般取每个cluster内所有样本点的平均值)
④重复进行第二到第三步,直到cluster的中心不在变化或者满足迭代次数。
k-means算法的难点主要在于k值的选取和cluster中心的初始化。对于k值,如果事先知道该分为几类,当然最好,不知道的情况下,有点难度,我最近看到的一种做法是《大数据-互联网大规模数据挖掘与分布式处理》这本书里提到的【参考文献2】,选取聚类指标来衡量。该思路认为,当类簇的数目接近真实值的时候,指标会发生突变。原来可能上升的很慢,转瞬间上升的很快,原来可能很慢,突然上升的很快。常用的指标有类簇的直径和半径、类簇平均质心的加权平均值等。
对于cluster中心的初始化,
①最常用的是随机初始化,但是这样的方法误差大,聚类结果常常不一样,辅助的办法是多迭代几次取平均值
②先用层次聚类得到结果,根据确定的k值,从每个簇中选取中心点。
③先随机确定一个点,再确定第二个点:跟第一个点的距离最大,第三个点:距离前两个点最近距离最大的点,以此类推。
后两种准确度较高。
三、
EM(Expectationmaximization)思想。EM的核心是极大似然估计,他的基本理论是这样的,我们在进行观测的时候,如我们盯着厕所,看看接下来先出来的是女生还是男生。这时候先出来了一个女生,那我们就有理由相信,这是因为女厕所里面的女生数比较多,所以我们才会优先观测到女生。这就是极大似然估计。通过这个思想,我们能对参数进行估计,即能够使得这种情况出现概率最大的参数的估计值,就是我们想要的最准确的参数的值了。根据这种思想,EM的步骤大概如下:(当需要估计两个参数时)
1、E步:固定参数1,调整参数2直到最优
2、M步:固定参数2,调整参数1直到最优
3、反复迭代1,2步直到似然函数L(Θ)最大
其实从这里也可以看到,EM的思想是融合到许多算法里的,如k-means,k-means当中隐含的思想就是EM,算法步骤中的第二步,固定了cluster的中心,选取了最短距离。第三步,固定了最短距离,选取了最优cluster中心。
降维思想。当数据所含的维度(变量)过多时,直接进行聚类或者分类,速度会特别缓慢,生成的模型过于复杂,而且往往容易造成过拟合,即“维度灾难”。所以我们得对数据进行降维。
如m维空间中的数据集,包含N个样本点Xi 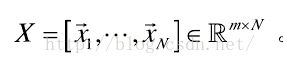 ,降维算法的目的就是获得X的相应低维表达式,
,降维算法的目的就是获得X的相应低维表达式, ,其中d<m,存在一个转换矩阵
,其中d<m,存在一个转换矩阵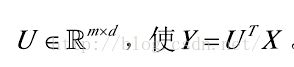 。以上思路是对于线性降维算法,非线性降维无法通过线性变换来得到。
。以上思路是对于线性降维算法,非线性降维无法通过线性变换来得到。
其实在做回归分析的时候,使用逐步回归或者方差分析剔除变量的时候,就涉及到了降维的思想。
①主成分分析。通过协方差矩阵进行降维。主成分的思路是对现有维度进行整合,得到各个变量的综合指标。用例子解释原理的话主要如下图,一个二维的数据集,原维度为横轴和纵轴X1、X2,通过线性变换将坐标轴转换成如图交叉垂直的两条虚线轴,
Y1=aX1+bX2
Y2=cX1+dX2
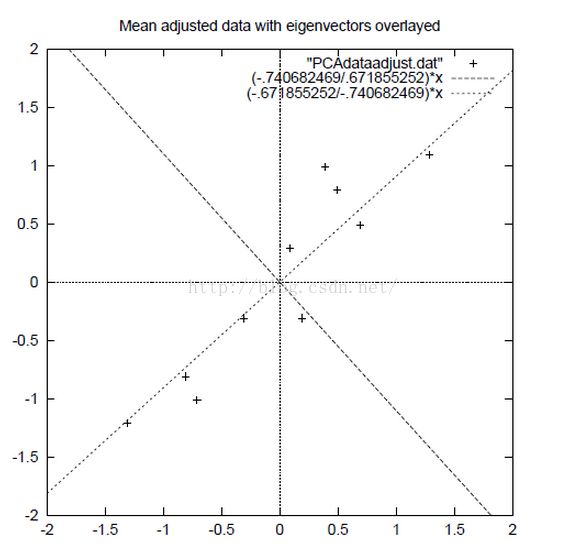
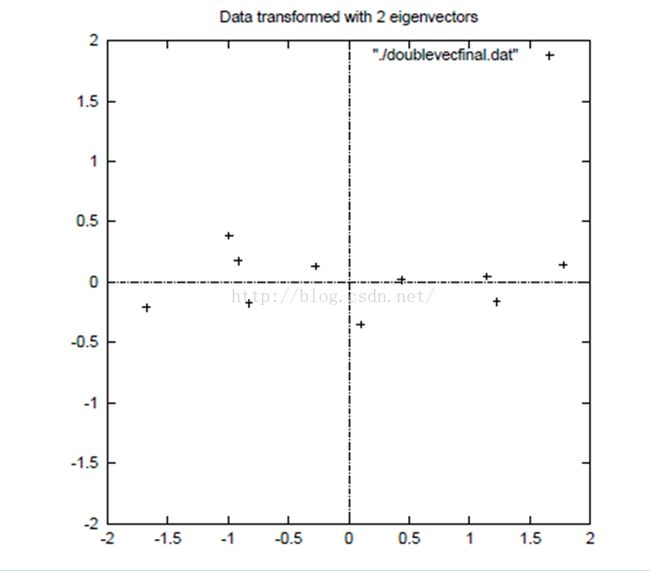
我们看到数据基本都分布在第一条虚线上,这个时候就可以将这个轴当做第一主成分(新轴)用来拟合数据。第二主成分上的偏差(f方差)较小,可以去掉这个维度。一般来说选取的主成分个数,只要对原维度解释能达到80%以上就很好了。具体介绍看博文【参考文献4】。
②因子分析。因子分析用的好像并没有想象中的广泛,所以我稍微了解了下,思路主要是探寻可观测变量间存在的不可观测的隐含变量即公共因子,如数学成绩和语文成绩,同时高或低,我们知道他其实一定程度上代表了智商,这里智商就是公共因子。模型构造多个公共因子和一个特殊因子,用来解释目标值。
主成分和因子分析都消除了相关性对数据的影响,虽然当模型只是用于预测时,变量间的相关性(或多重共线性)对结果影响不大。关于两者之间的更深入比较可参考【参考文献5】。目前较常采用的算法是主成分分析。
注:不能因为PCA可以降维就滥用,使用PCA的目的主要是为了避免信息重叠,如一个数学成绩,多个语文成绩变量,这个时候语文成绩的占比就会高很多,从而影响模型的准确性,通过PCA将语文成绩降维,就能削减这种影响,并不是相关性高就要使用PCA,可以看出我们关注的实质是相关性后面的信息重叠。所以应当慎用PCA。
最后,目前在机器学习的研究中,对算法的创新主要是在原有的基础上,通过结合不同算法的优点,得到一种更有效的算法,如结合遗传算法的决策树、结合自助法boot-strap诞生的决策树随机森林等。
呼,总算整理完了,大脑要炸了。最后我自己总结一下,大致的流程差不多是这样:
①到手数据进行清理,去除NA,scale标准化
②当变量过多时,主观选取变量,或者采用PCA降维
③根据情况选用ML算法建模
参考文献:
[1] http://blog.csdn.net/v_july_v/article/details/7624837 支持向量机通俗导论(理解SVM的三层境界)
[2] http://www.tuicool.com/articles/RnIvIn
[3] https://web.stanford.edu/~hastie/Papers/gap.pdf
[4] http://www.cnblogs.com/jerrylead/archive/2011/04/18/2020209.html
[5] http://www.douban.com/note/225942377/
以上图片皆来自网络,图片侵删。