SQL Server ->> 高可用与灾难恢复(HADR)技术 -- AlwaysOn(实战篇)之AlwaysOn可用性组搭建
因为篇幅原因,AlwaysOn可用性组被拆成了两部分:理论部分和实战部分。而实战部分又被拆成了准备工作和AlwaysOn可用性组搭建。
三篇文章各自的链接:
SQL Server ->> 高可用与灾难恢复(HADR)技术 -- AlwaysOn(理论篇)
SQL Server ->> 高可用与灾难恢复(HADR)技术 -- AlwaysOn(实战篇)之建立活动目录域、DNS服务器和Windows故障转移群集(准备工作)
SQL Server ->> 高可用与灾难恢复(HADR)技术 -- AlwaysOn(实战篇)之AlwaysOn可用性组搭建
前面两篇文章介绍了AlwaysOn和搭建AlwaysOn之前的准备工作。这篇文章也是这整一个系列的主题,也就是搭建AlwaysOn可用性组。
本篇主要通过一步步的步骤从如何启动AlwaysOn,配置AlwaysOn可用性组,中间的一些其他Windows层面的配置(如防火墙),数个验证的例子来验证AlwaysOn的功能(故障转移、只读路由、只读副本等)。这里的环境沿用了前两篇文章所搭建的环境。
架设环境信息
域名:jerrychen.com
AlwaysOn虚拟IP地址:192.168.2.200
WSFC虚拟IP地址:192.168.2.201
WSFC群集名:AOCLUSTER
| Domain Controller | Primary Replica | Secondary Replica | |
| Server Name | dc.jerrychen.com | main.jerrychen.com | slave1.jerrychen.com |
| OS | Windows Server 2012 Data Center x64 | Windows Server 2012 Data Center x64 | Windows Server 2012 Data Center x64 |
| IP Address | 192.168.2.100 | 192.168.2.102 | 192.168.2.101 |
| Gateway | 192.168.2.2 | 192.168.2.2 | 192.168.2.2 |
| SQL Server Version | - | SQL Server 2014 enterprise x64 | SQL Server 2014 enterprise x64 |
| DNS | 127.0.0.1 | 192.168.2.100 | 192.168.2.100 |
安装SQL Server实例和配置SQL Server服务账户
首先是在Main和Slave1分别安装SQL Server 2014 Enterprise x64。以单机模式默认安装即可,这里不细讲。这样保持默认实例名称即可。
安装完毕后配置DomainAdmin为服务账号
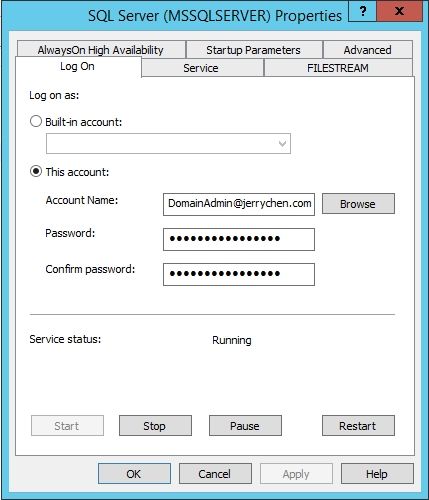
启用Always可用性组
然后在SQL Server Configuration Management中打开SQL Server服务的属性界面。在AlwaysOn High Availability选项卡勾选Enable AlwaysOn Availability Groups选项。
我们就选用SQL Server数据库最常用的DEMO数据库 -- AdventureWorks来作为这次的实验数据库吧。数据库的来源自行谷歌或者百度搜索AdventureWorks2012寻找连接下载。
配置防火墙
由于AlwaysOn需要节点间互相通信,所以我们需要在每个节点上配置防火墙保证SQL Server应用程序可以与外部进行TCP/IP通信

配置服务账户保证其有足够的权限操作
如果服务账户不是sysadmin成员添加它作为sysadmin角色成员
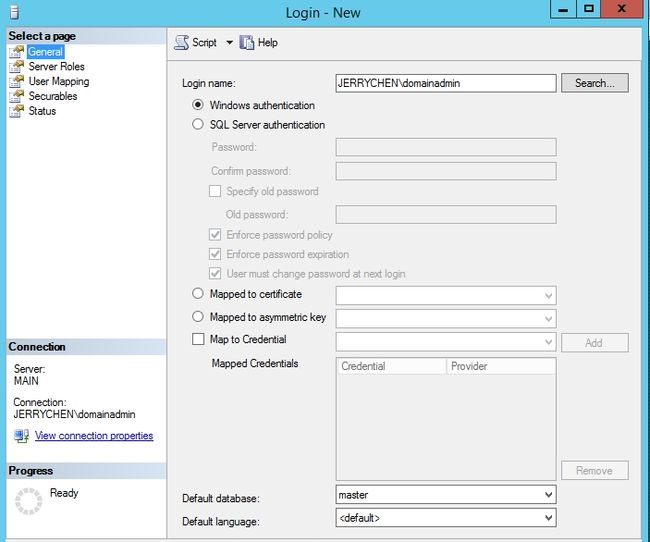
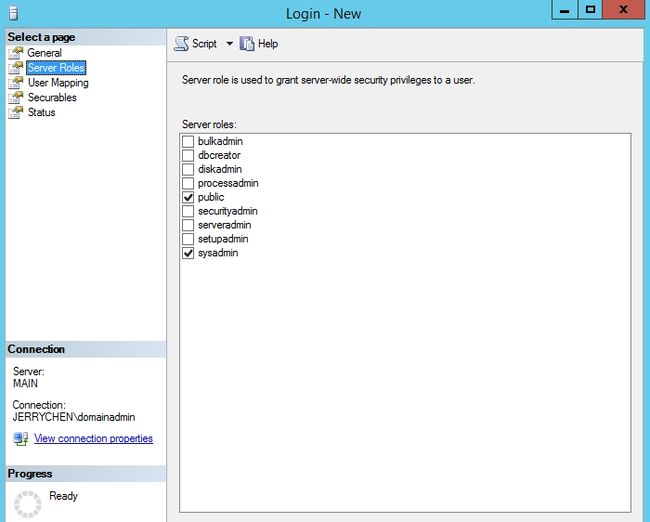
满足所有AlwaysOn可用性组创建的必要条件
数据库完整恢复模式
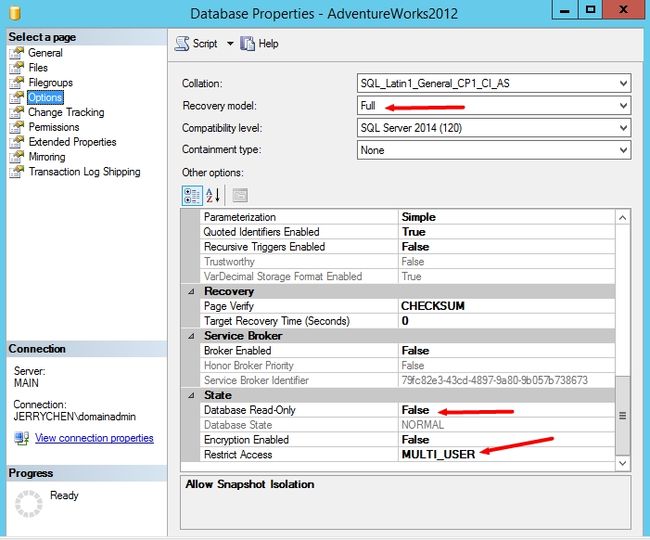
有过完整备份历史
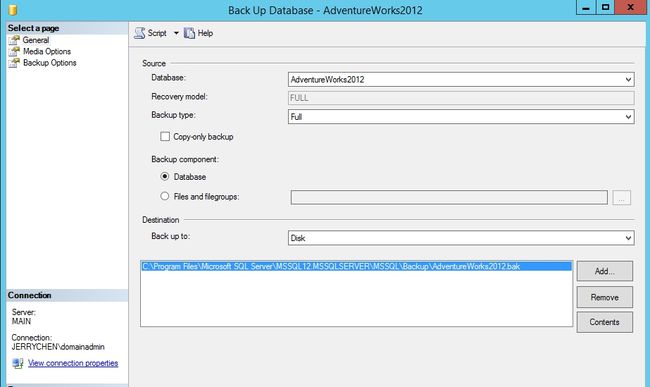
可用性组的创建
通过向导来创建
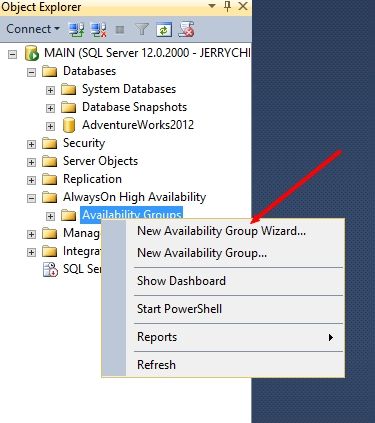
配置可用性组名字
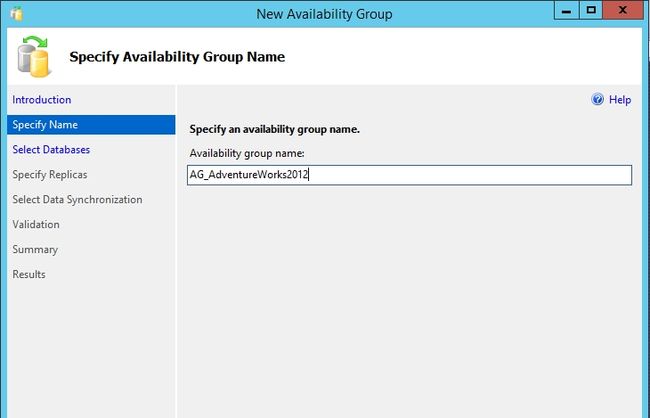
如果你不满足前面的创建可用性组的条件,比如没有完整备份过或者数据库是只读状态或者单用户模式,这里的Status会提示你。这里满足的先决条件。
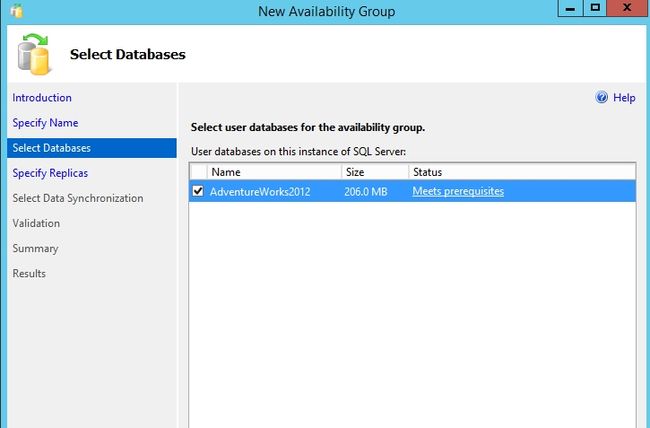
把Slave1添加进来作为辅助副本。勾选Synchronous Commit(同步提交),Up to 3的意思是最多可以有3个的同步提交模式的辅助副本。

无论是主副本或者辅助副本都选择同步提交模式,辅助副本的Readable Secondary选择为Yes。只是为了后面的只读辅助数据库准备。
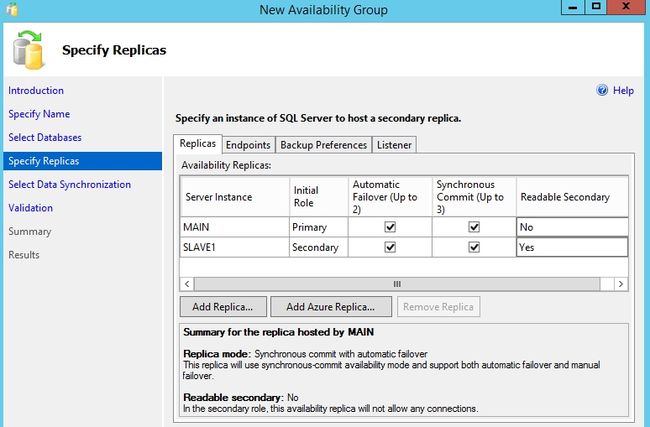
AlwaysOn和镜像一样都采用Endpoint(端点)来进行数据传输。AlwaysOn使用端点是为了和辅助副本进行日志传输和心跳线的通信。
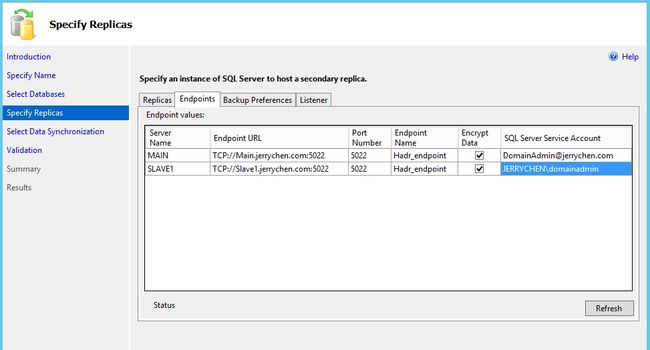
备份优先级勾选Prefer Secondary。意思是有限考虑辅助副本上做数据备份。只有在没有辅助副本的情况下才使用主副本。把辅助副本的优先级别调为100,而主副本50。
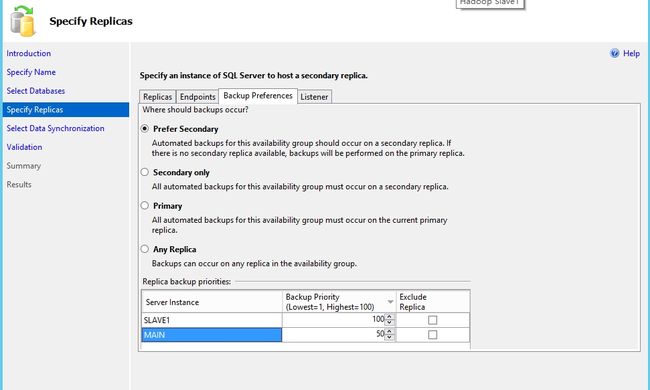
最后一个页面是Listener(侦听器)。这里需要配置侦听器的虚拟服务器名、端口号和IP地址。也就是前面架构环境信息里面写的。
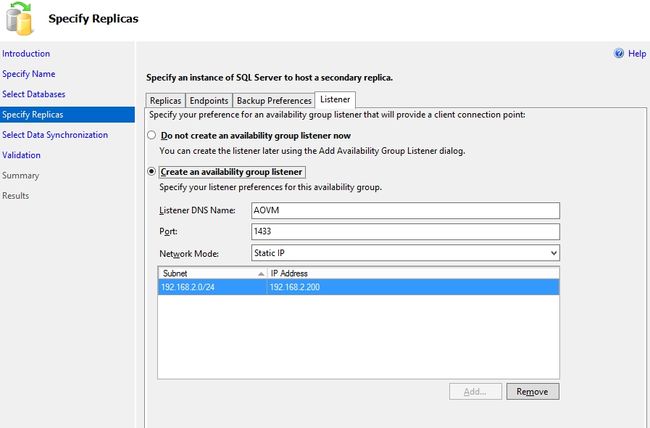
点击Yes进入下一页
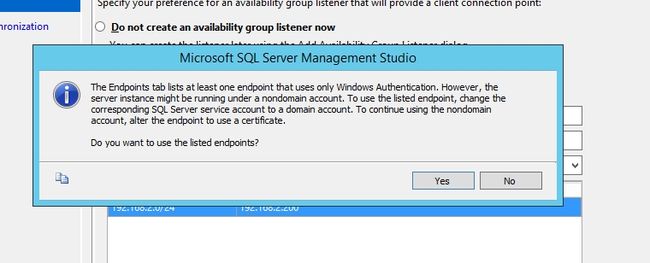
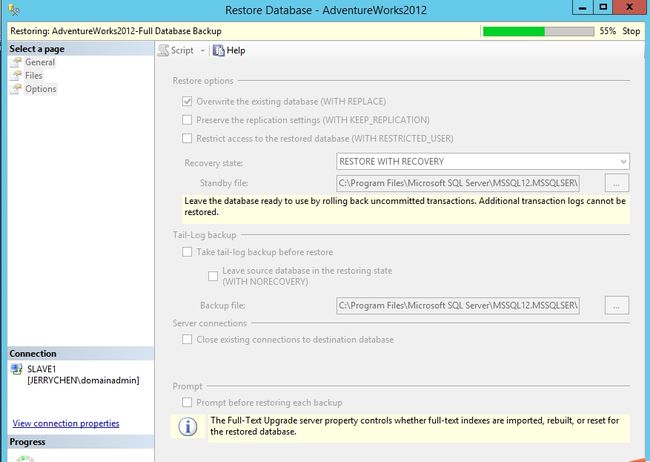
这个地方是选择初始化数据库的方式。如果你选择Full,你需要提供一个共享地址,AlwaysOn自己自动备份数据库然后还原到目标的辅助副本上。这里我们选择Join only,所以我们需要事先把数据库备份并还原到目标的辅助数据库上。
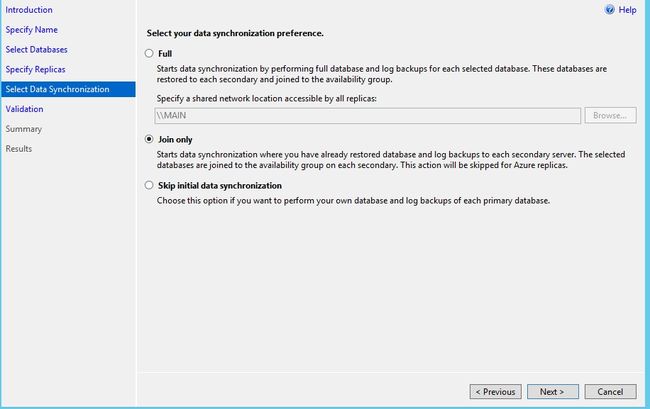
还原过程需要加上WITH NORECOVERY,后面才不会报错。
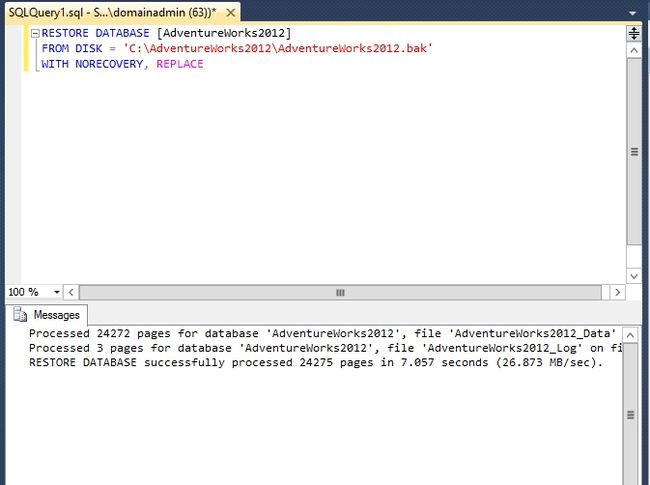
确认没有出现错误提示
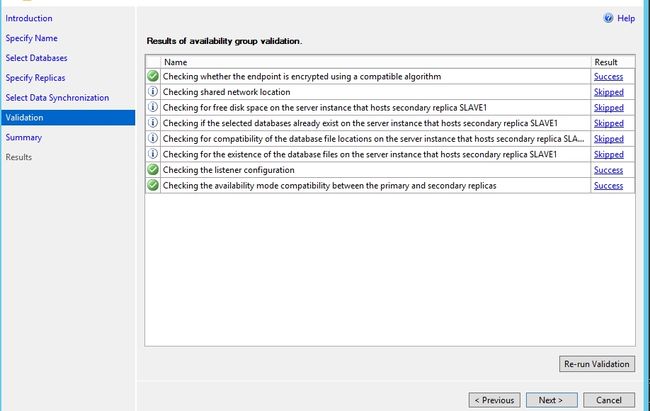
成功把MAIN和SLAVE1加入可用性组
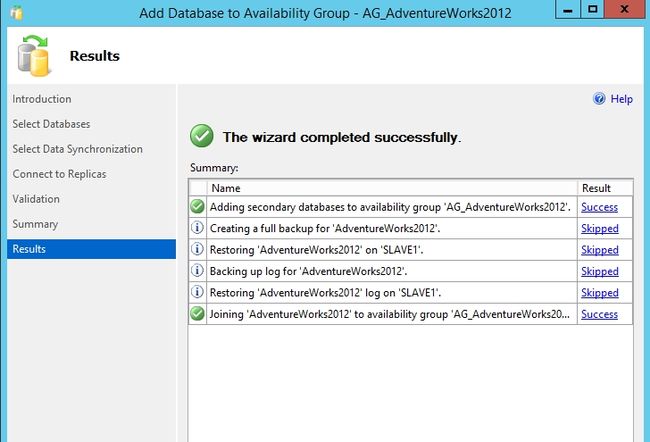
验证可用性组创建的成功与否
这个时候你会发现你前面配置的虚拟服务器名出现在DNS服务器上
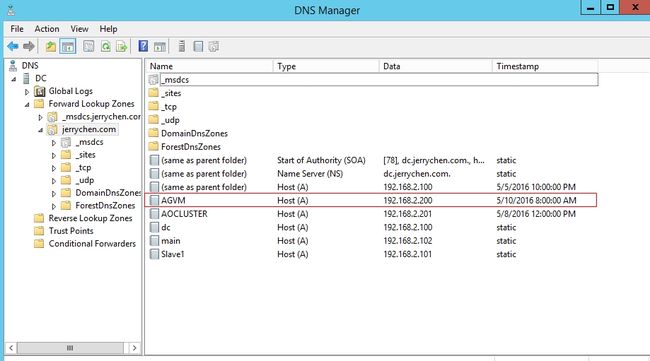
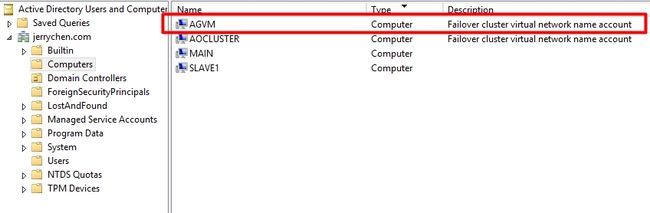
同样也出现在域控制器上
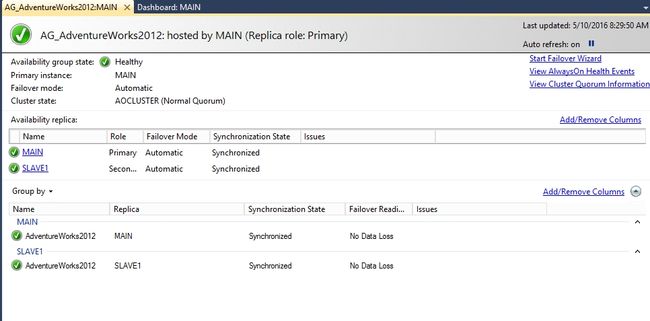
通过Dashboard观察副本的运行情况。是否可用性组处于Healthy状态?是否副本间处于同步状态?
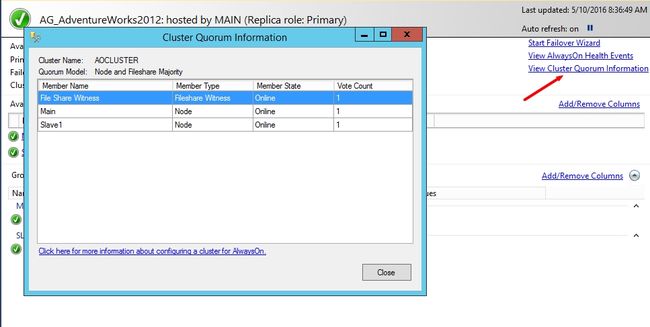
仲裁信息
验证辅助数据库的只读访问是否成功
SSMS对象浏览器可以显示出我们创建好的可用性组,包括主副本和辅助副本的服务器上都能显示出来。
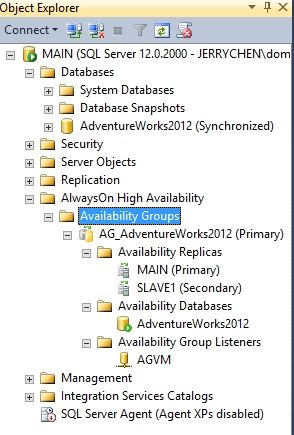
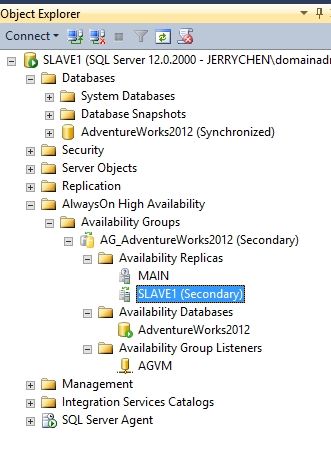
这个时候你尝试用SSMS开启一个查询窗口,在连接前添加APPLICATIONINTENT=READONLY选项来连接SLAVE1服务器。尝试访问任意一张数据表。是可以只读访问的。
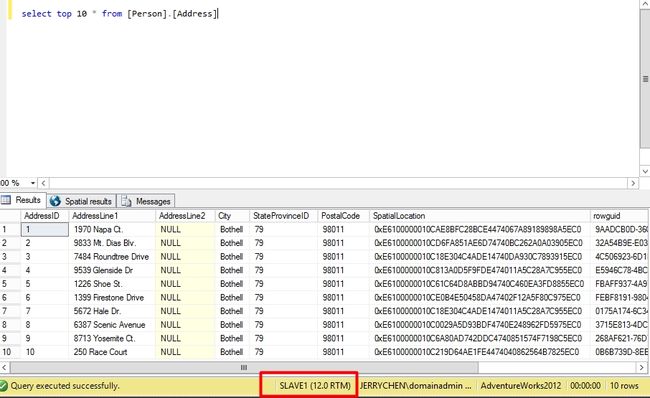
接下来换成虚拟服务器名来访问,看看到底会不会被重导向到SLAVE1
结果可以开到还是在MAIN上面。
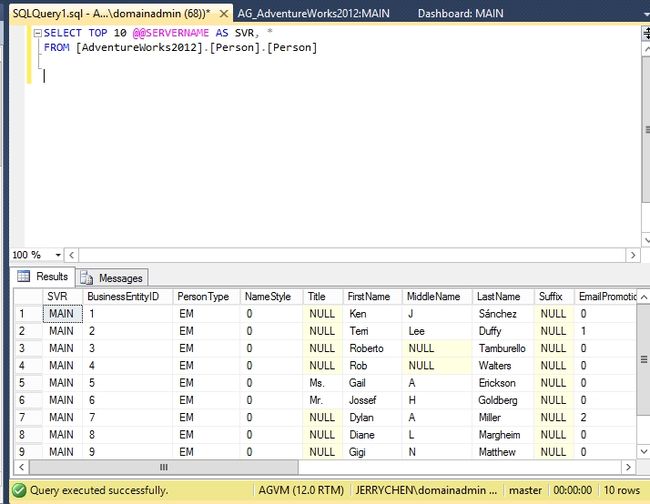
只读路由功能
其实是因为我们还没有配置只读路由
ALTER AVAILABILITY GROUP [AG_AdventureWorks2012] MODIFY REPLICA ON N'MAIN' WITH (SECONDARY_ROLE (ALLOW_CONNECTIONS = ALL)); ALTER AVAILABILITY GROUP [AG_AdventureWorks2012] MODIFY REPLICA ON N'MAIN' WITH (SECONDARY_ROLE (READ_ONLY_ROUTING_URL = N'TCP://MAIN.jerrychen.com:1433')); ALTER AVAILABILITY GROUP [AG_AdventureWorks2012] MODIFY REPLICA ON N'SLAVE1' WITH (SECONDARY_ROLE (ALLOW_CONNECTIONS = READ_ONLY)); ALTER AVAILABILITY GROUP [AG_AdventureWorks2012] MODIFY REPLICA ON N'SLAVE1' WITH (SECONDARY_ROLE (READ_ONLY_ROUTING_URL = N'TCP://SLAVE1.jerrychen.com:1433')); ALTER AVAILABILITY GROUP [AG_AdventureWorks2012] MODIFY REPLICA ON N'MAIN' WITH (PRIMARY_ROLE (READ_ONLY_ROUTING_LIST=('SLAVE1','MAIN'))); ALTER AVAILABILITY GROUP [AG_AdventureWorks2012] MODIFY REPLICA ON N'SLAVE1' WITH (PRIMARY_ROLE (READ_ONLY_ROUTING_LIST=('MAIN','SLAVE1'))); GO
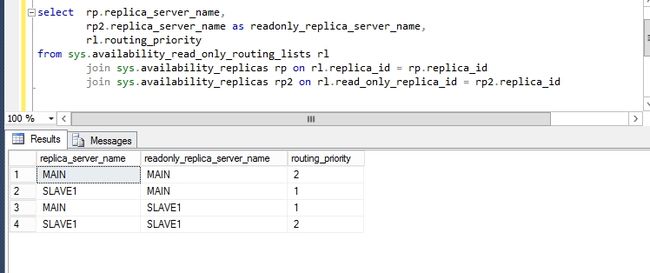
运行下面代码观察前面的配置是否成功
select rp.replica_server_name, rp2.replica_server_name as readonly_replica_server_name, rl.routing_priority from sys.availability_read_only_routing_lists rl join sys.availability_replicas rp on rl.replica_id = rp.replica_id join sys.availability_replicas rp2 on rl.read_only_replica_id = rp2.replica_id
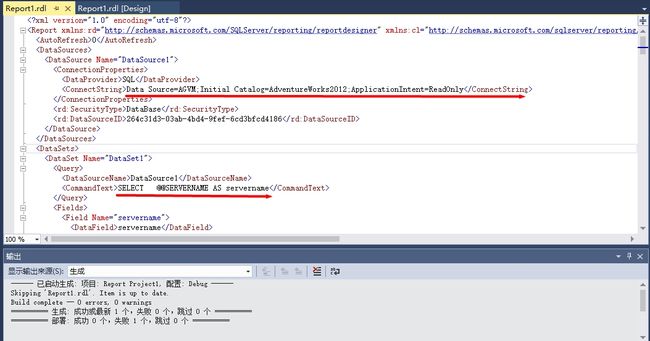
SSMS其实不太支持这个APPLICATIONINTENT=READONLY。为了测试目的,我们用SSRS报表来测试。创建一个SSRS报表,报表的Dataset的datasource使用下面的connection string,也就是加入了APPLICATIONINTENT=READONLY。然后查看服务器名。
预览一下你就可以发现,其实是重导向只读访问到辅助副本的数据库上。
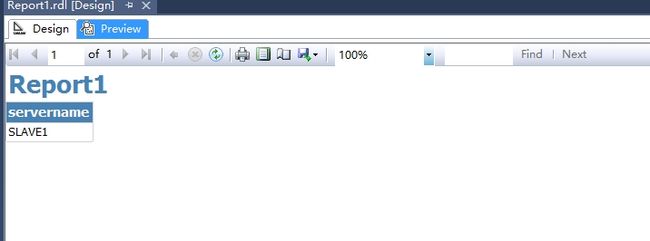
验证数据同步情况
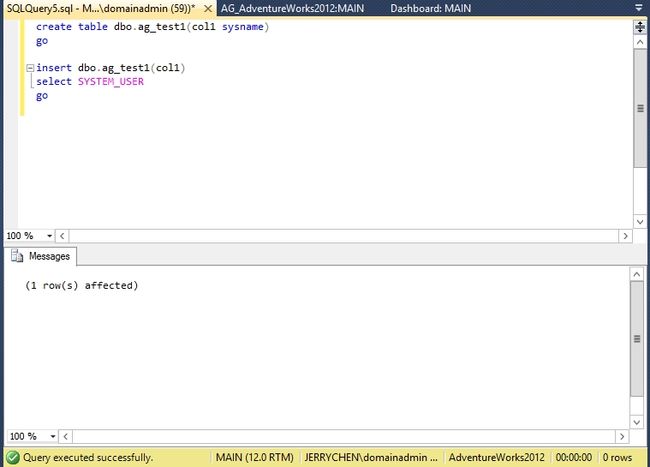
实验1: 简单的测试
我们先关闭辅助副本的网卡,然后在主副本上创建一张表并插入一行记录
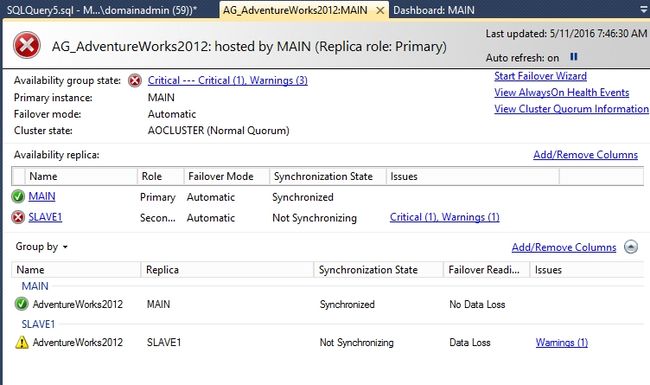
可以从主副本上得Dashboard看到SLAVE1处于断开状态。SLAVE1的同步状态为NOT SYNCHRONIZING。
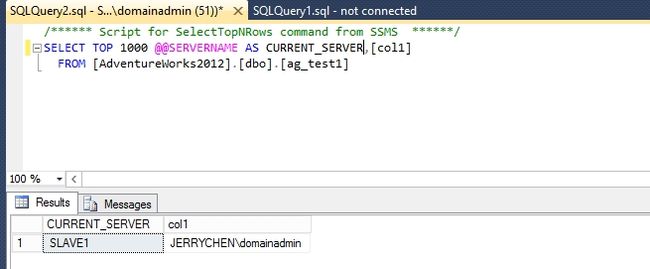
然后我们再把网卡重新启动,再在SLAVE1上查询刚才在MAIN上创建的表。数据同步过来了。
实验2: 并发测试
在MAIN上再创建一张表。然而这次我们开启两个会话不间断地这张表插入数据。在两个会话不不间断插入数据的同时,我们再把SLAVE1的网卡切断。
会话1:

会话2
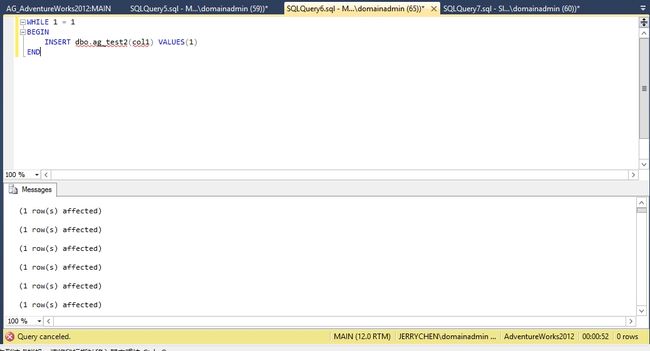
SLAVE1的网卡切断口我们停止两个会话的数据库插入操作。再来观察下一共插入多少行记录。
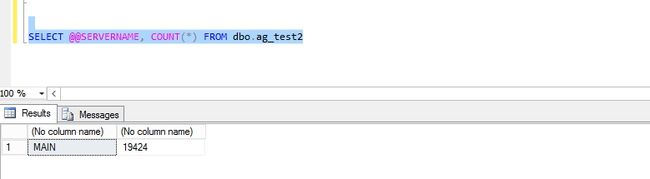
重新启用SLAVE1的网卡,再看看是否同步过来了?而且数据也是一致的。从下图可以看出,副本在重新恢复后会自动“跟上” -- 重做日志尾端 -- 这点是没错。
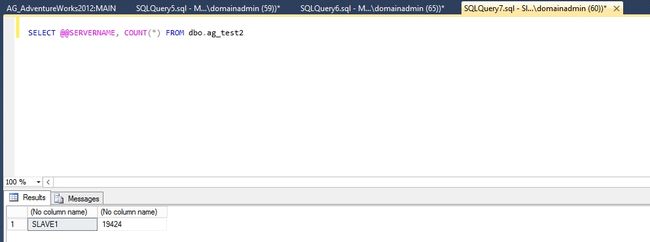
测试辅助副本FailOver
既然AlwaysOn主要的功能就是Failover。这里就测试下把SLAVE1的网卡断开后,MAIN是否会接过只读访问的活?
可以看到重新刷新SSRS报表后,访问的目标服务器确实变成了MAIN.
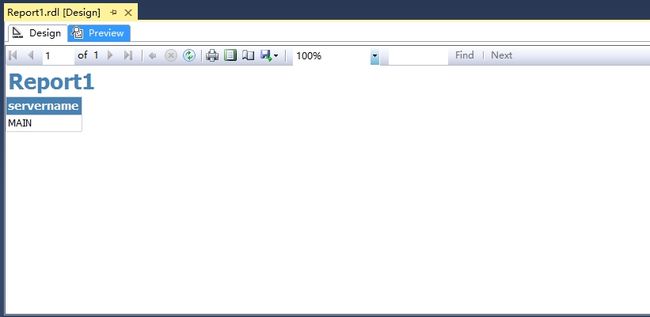
测试主副本FailOver
反过来,也是最主要的测试:主副本FAILOVER。断开主副本网卡。

再刷新报表。发现目标的服务器变了。
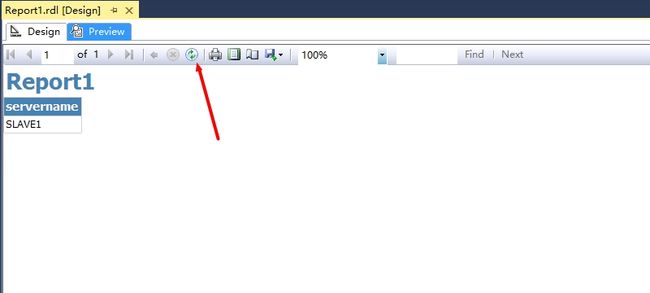
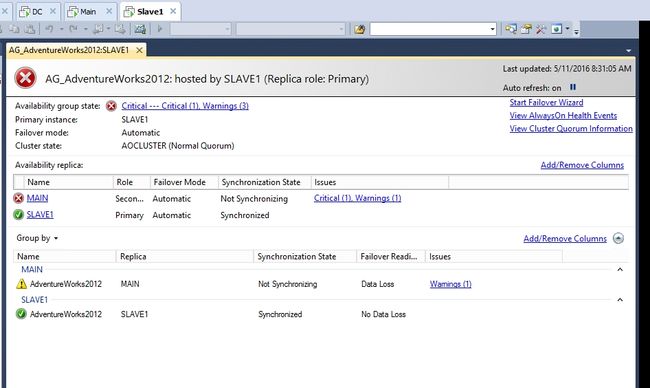
观察SLAVE1上的dashboard,我们可以看到现在SLAVE1的角色被提升为了PRIMARY。
当然,我们更重要的是测试FAILOVER后,原来的辅助副本是否能接受数据写入。我们用AGVM这个虚拟服务器名开启连接后新建一张表再插入一条记录验证是否能写入数据。
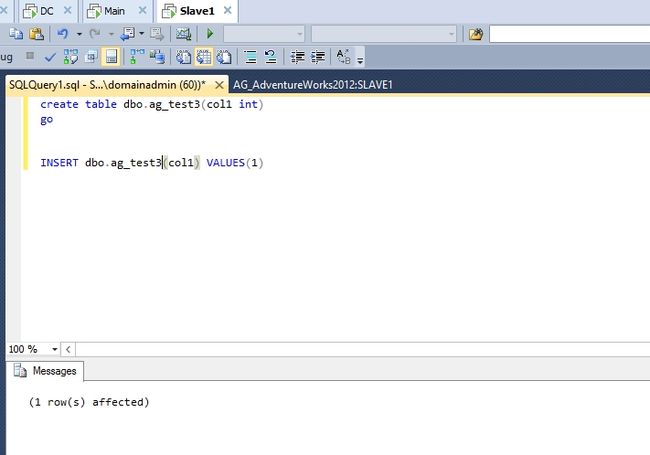
我们再把MAIN的网卡重启。这个时候ALWAYSON会先等待MAIN先重新加入CLUSTER的节点后再重新成为一个辅助副本。
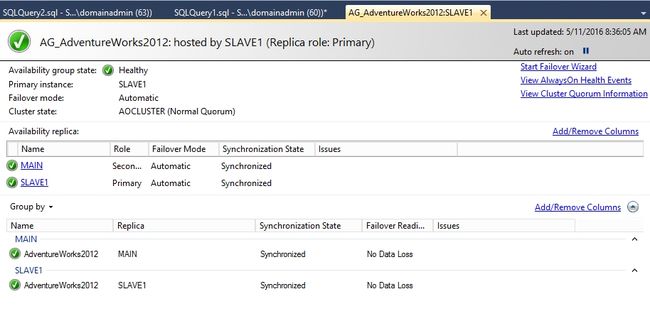
我们再访问MAIN数据库,看看刚才它下线的时候在SLAVE1上创建的表被同步过来了没有。
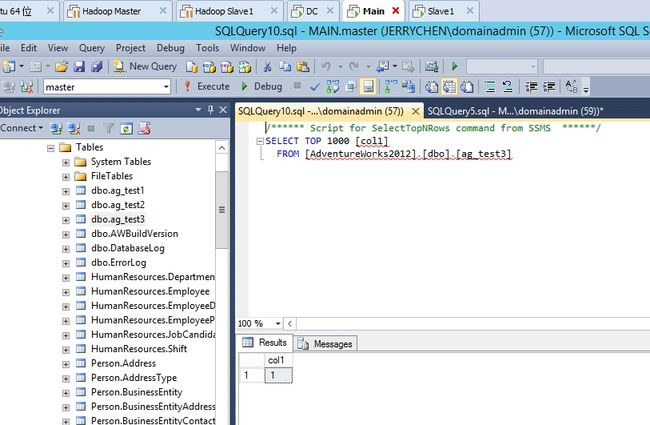
有一点我不解的是,在FAILOVER之后,SLAVE1的角色居然是Unknown
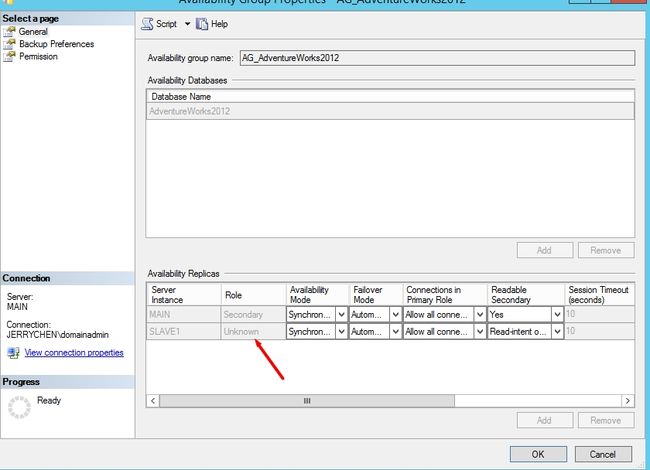
有人会问,那我们想把现在辅助副本再切换回主副本怎么办?那就手动Failover咯。
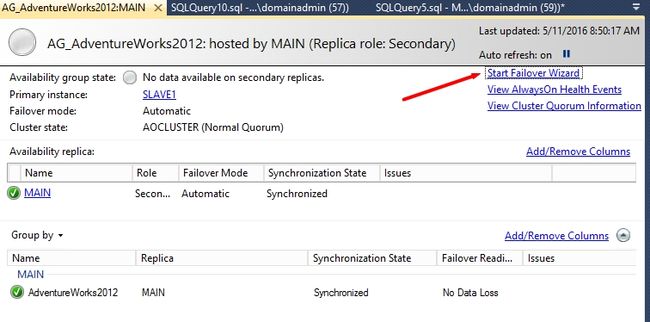
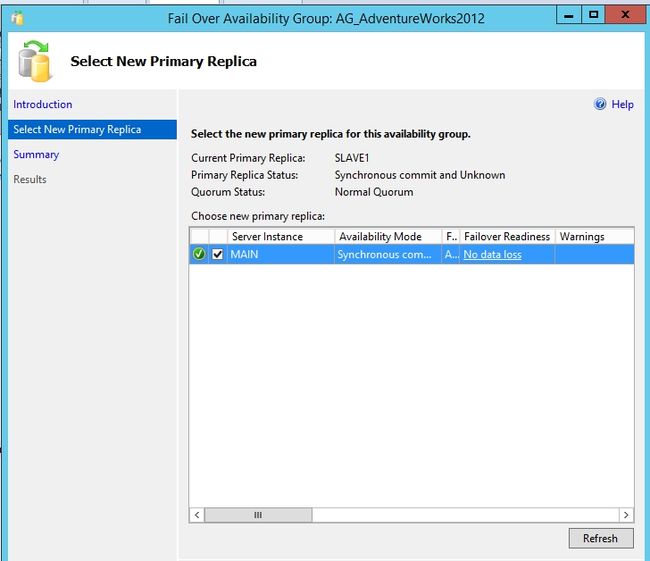
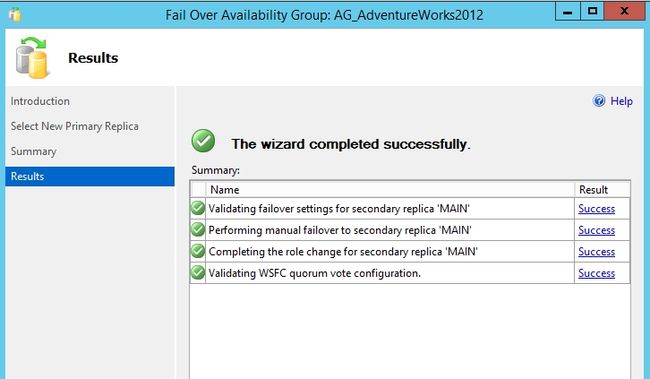
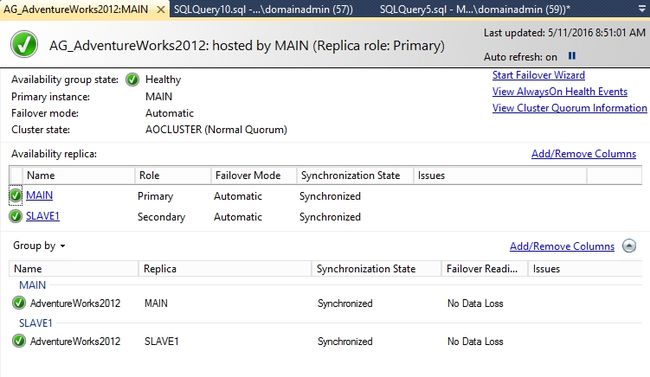
Main重新成了主副本
总结:
好了。AlwaysOn系列的最后一篇文章就到此结束了。 最后在这里做一个小小的总结:AlwaysOn作为SQL Server 2012的一大特性,集之前版本中的各项HADR技术的优点于一身,确实让人眼前一亮。它也不负它SQL Server 2012后HADR的首选技术之名。一番体验下来,确实看到了它于Failover Cluster、Mirroring和Log Shipping等的不同点和相同点。我想它对产品而言更具又意义的是SQL Server HADR技术向来不是一项技术即可满足公司的业务需求,往往都是结合其他的HADR的技术来达成最优的解决方案。而如今AlwaysOn的出现是给出了一个更加优秀的解决方案。在设计高可用解决方案的时候可以提供强大的功能性。
参考:
《SQL Server 2012实施与管理实战指南》
Configure Read-Only Routing for an Availability Group (SQL Server)
AlwaysOn Client Connectivity (SQL Server)
Creation and Configuration of Availability Groups (SQL Server)
Use the Availability Group Wizard (SQL Server Management Studio)
AlwaysOn Architecture Guide: Building a High Availability and Disaster Recovery Solution by Using Failover Cluster Instances and Availability Groups