CSDN Android客户端开发(二):详解如何基于Java用Jsoup爬虫HTML数据
本文参考鸿洋大大的链接详细介绍如何使用Jsoup包抓取HTML数据,是一个纯java工程,并将其打包成jar包。希望了解如何用java语言爬虫网页的可以看下。
杂家前文就又介绍用HTTP访问百度主页得到html的string字符串,但html的文本数据如果不经过处理就是个文本字符串没有任何效果的。所谓的浏览器就是负责将文本的html“翻译”成看到的界面。在前文有介绍,这个csdn的客户端app分首页、业界、移动、研发、程序员、云计算五大类。以业界为例,http://news.csdn.net/ 实际加上page1的http地址是:http://news.csdn.net/news/1

从上图可知,一个完整的新闻包含东西还是比较多的,将其抽象出来ID号、标题、链接、日期、图片链接、内容、类型,这7个属性。
一、新建org.yanzi.bean包,里面有两个java文件
NewsItem.java是上面具有7个属性的新闻bean
- <span style="font-family:Comic Sans MS;font-size:18px;">package org.yanzi.bean;
- public class NewsItem
- {
- private int id;
- /**
- * 标题
- */
- private String title;
- /**
- * 链接
- */
- private String link;
- /**
- * 发布日期
- */
- private String date;
- /**
- * 图片的链接
- */
- private String imgLink;
- /**
- * 内容
- */
- private String content;
- /**
- * 类型
- *
- */
- private int newsType;
- public int getNewsType()
- {
- return newsType;
- }
- public void setNewsType(int newsType)
- {
- this.newsType = newsType;
- }
- public String getTitle()
- {
- return title;
- }
- public void setTitle(String title)
- {
- this.title = title;
- }
- public String getLink()
- {
- return link;
- }
- public void setLink(String link)
- {
- this.link = link;
- }
- public int getId()
- {
- return id;
- }
- public void setId(int id)
- {
- this.id = id;
- }
- public String getDate()
- {
- return date;
- }
- public void setDate(String date)
- {
- this.date = date;
- }
- public String getImgLink()
- {
- return imgLink;
- }
- public void setImgLink(String imgLink)
- {
- this.imgLink = imgLink;
- }
- public String getContent()
- {
- return content;
- }
- public void setContent(String content)
- {
- this.content = content;
- }
- @Override
- public String toString()
- {
- return "NewsItem [id=" + id + ", title=" + title + ", link=" + link + ", date=" + date + ", imgLink=" + imgLink
- + ", content=" + content + ", newsType=" + newsType + "]";
- }
- }
- </span>
CommonException.java 这个主要是抛出异常,方便构造
- <span style="font-family:Comic Sans MS;font-size:18px;">package org.yanzi.bean;
- public class CommonException extends Exception
- {
- /**
- *
- */
- private static final long serialVersionUID = 1L;
- public CommonException()
- {
- super();
- // TODO Auto-generated constructor stub
- }
- public CommonException(String message, Throwable cause)
- {
- super(message, cause);
- // TODO Auto-generated constructor stub
- }
- public CommonException(String message)
- {
- super(message);
- // TODO Auto-generated constructor stub
- }
- public CommonException(Throwable cause)
- {
- super(cause);
- // TODO Auto-generated constructor stub
- }
- }
- </span>
二、新建org.yanzi.csdn包,这里放三个java文件
Constant.java 这块将其弄成interface比较奇怪哈,写成class也ok
- <span style="font-family:Comic Sans MS;font-size:18px;">package org.yanzi.csdn;
- public interface Constant
- {
- public static final int NEWS_TYPE_YEJIE = 1; //业界
- public static final int NEWS_TYPE_YIDONG = 2; //移动
- public static final int NEWS_TYPE_YANFA = 3; //研发
- public static final int NEWS_TYPE_CHENGXUYUAN = 4;//程序员
- public static final int NEWS_TYPE_YUNJISUAN = 5; //云计算
- }
- </span>
URLUtil.java 这个负责获取到每个大类新闻的精确的url地址
- <span style="font-family:Comic Sans MS;font-size:18px;">package org.yanzi.csdn;
- public class URLUtil
- {
- public static final String NEWS_LIST_URL = "http://www.csdn.net/headlines.html";
- public static final String NEWS_LIST_URL_YIDONG = "http://mobile.csdn.net/mobile";
- public static final String NEWS_LIST_URL_YANFA = "http://sd.csdn.net/sd";
- public static final String NEWS_LIST_URL_YUNJISUAN = "http://cloud.csdn.net/cloud";
- public static final String NEWS_LIST_URL_ZAZHI = "http://programmer.csdn.net/programmer";
- public static final String NEWS_LIST_URL_YEJIE = "http://news.csdn.net/news";
- /**
- * 根据文章类型,和当前页码生成url
- * @param newsType
- * @param currentPage
- * @return
- */
- public static String generateUrl(int newsType, int currentPage)
- {
- currentPage = currentPage > 0 ? currentPage : 1;
- String urlStr = "";
- switch (newsType)
- {
- case Constant.NEWS_TYPE_YEJIE:
- urlStr = NEWS_LIST_URL_YEJIE;
- break;
- case Constant.NEWS_TYPE_YANFA:
- urlStr = NEWS_LIST_URL_YANFA;
- break;
- case Constant.NEWS_TYPE_CHENGXUYUAN:
- urlStr = NEWS_LIST_URL_ZAZHI;
- break;
- case Constant.NEWS_TYPE_YUNJISUAN:
- urlStr = NEWS_LIST_URL_YUNJISUAN;
- break;
- default:
- urlStr = NEWS_LIST_URL_YIDONG;
- break;
- }
- urlStr += "/" + currentPage;
- return urlStr;
- }
- }</span>
DataUtil.java 利用HttpURLConnection 利用get方式获取html的文本,也就是string类型的数据. 注意这个文件跟上个文件封装上的松耦合性。
- <span style="font-family:Comic Sans MS;font-size:18px;">package org.yanzi.csdn;
- import java.io.InputStream;
- import java.net.HttpURLConnection;
- import java.net.URL;
- import org.yanzi.bean.CommonException;
- public class DataUtil {
- /**
- * 获取HTML数据
- * @param urlStr url地址
- * @return
- * @throws CommonException
- */
- public static String doGet(String urlStr) throws CommonException{
- StringBuffer sb = new StringBuffer();
- try {
- URL url = new URL(urlStr);
- HttpURLConnection conn = (HttpURLConnection) url.openConnection();
- conn.setRequestMethod("GET");
- conn.setConnectTimeout(5000);
- conn.setDoInput(true);
- conn.setDoOutput(true);
- if(conn.getResponseCode() == 200){
- InputStream is = conn.getInputStream();
- int len = 0;
- byte[] buf = new byte[1024];
- while((len = is.read(buf)) != -1){
- sb.append(new String(buf, 0, len, "UTF-8"));
- }
- is.close();
- }else{
- throw new CommonException("访问网络失败00");
- }
- } catch (Exception e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- throw new CommonException("访问网络失败11");
- }
- return sb.toString();
- }
- }
- </span>
三、包名org.yanzi.biz,其下只有这个类,复杂完成真正的爬虫工作,即从html string字符串里提取出对应的新闻属性,存到新闻bean里
- <span style="font-family:Comic Sans MS;font-size:18px;">package org.yanzi.biz;
- import java.util.ArrayList;
- import java.util.List;
- import org.jsoup.Jsoup;
- import org.jsoup.nodes.Document;
- import org.jsoup.nodes.Element;
- import org.jsoup.select.Elements;
- import org.yanzi.bean.CommonException;
- import org.yanzi.bean.NewsItem;
- import org.yanzi.csdn.DataUtil;
- import org.yanzi.csdn.URLUtil;
- /**
- * 处理NewItem的业务类
- * @author zhy
- *
- */
- public class NewsItemBiz
- {
- /**
- * 业界、移动、云计算
- *
- * @param htmlStr
- * @return
- * @throws CommonException
- */
- public List<NewsItem> getNewsItems( int newsType , int currentPage) throws CommonException
- {
- String urlStr = URLUtil.generateUrl(newsType, currentPage);
- String htmlStr = DataUtil.doGet(urlStr);
- List<NewsItem> newsItems = new ArrayList<NewsItem>();
- NewsItem newsItem = null;
- Document doc = Jsoup.parse(htmlStr);
- Elements units = doc.getElementsByClass("unit");
- for (int i = 0; i < units.size(); i++)
- {
- newsItem = new NewsItem();
- newsItem.setNewsType(newsType);
- Element unit_ele = units.get(i);
- Element h1_ele = unit_ele.getElementsByTag("h1").get(0);
- Element h1_a_ele = h1_ele.child(0);
- String title = h1_a_ele.text();
- String href = h1_a_ele.attr("href");
- newsItem.setLink(href);
- newsItem.setTitle(title);
- Element h4_ele = unit_ele.getElementsByTag("h4").get(0);
- Element ago_ele = h4_ele.getElementsByClass("ago").get(0);
- String date = ago_ele.text();
- newsItem.setDate(date);
- Element dl_ele = unit_ele.getElementsByTag("dl").get(0);// dl
- Element dt_ele = dl_ele.child(0);// dt
- try
- {// 可能没有图片
- Element img_ele = dt_ele.child(0);
- String imgLink = img_ele.child(0).attr("src");
- newsItem.setImgLink(imgLink);
- } catch (IndexOutOfBoundsException e)
- {
- }
- Element content_ele = dl_ele.child(1);// dd
- String content = content_ele.text();
- newsItem.setContent(content);
- newsItems.add(newsItem);
- }
- return newsItems;
- }
- }
- </span>
注意这个文件是真正的爬虫的核心,说明如下:
1、要爬虫一个html数据在之前可以使用HtmlParser,见链接http://www.cnblogs.com/loveyakamoz/archive/2011/07/27/2118937.html 但自从jsoup诞生后,使用比HtmlParser更方面。此处就是利用jsoup解析html的,需要加载lib文件夹下的jsoup-1.7.2.jar、jsoup-1.7.2-sources.jar,自己add to build path即可。后者是源码,可以查看,真正的包就第一个。
2、jsoup可以直接打开一个网页url,此处为了方便已经写了从url获取string类型的html代码了。所以可以直接利用Document doc = Jsoup.parse(htmlStr); 得到Document类。
以业界新闻为例,http://news.csdn.net/news/1,按快捷键ctrl+u查看其源码,搜索关键字unit可以看到:
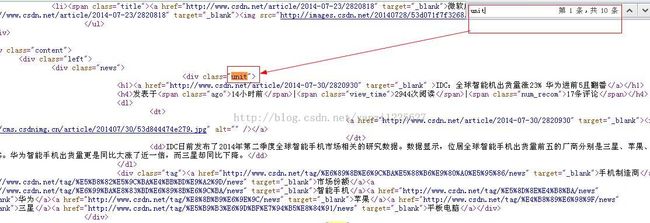
每一个新闻就是以关键字“unit”来标识的,第一页一共有10条新闻所以有10个unit。Elements units = doc.getElementsByClass("unit"); 得到这10个新闻item的集合。
3、接下来就是对一个新闻提取具体信息了
先来看其中一个完整的新闻html代码:
<div class="unit">
<h1><a href="http:www.csdn.net/article/2014-07-25/2820877" target="_blank" >微视、美拍等的春天,不是短视频应用的春天</a></h1>
<h4>发表于<span class="ago">2014-07-25 16:52</span>|<span class="view_time">690次阅读</span>|<span class="num_recom">6条评论</span></h4>
<dl>
<dt>
<a href="http:www.csdn.net/article/2014-07-25/2820877" target="_blank"><img src="http:cms.csdnimg.cn/article/201407/25/53d21abd54a77.jpg" alt="" /></a>
</dt>
<dd>微视、美拍等短视频应用最近很火,它们都已经在App Store社交免费榜靠前。它们的流行,能证明短视频应用的春天到了吗?小谦认为,非也。只有解决4G网络问题、分享问题以及拍摄优化问题后,它的春天才会真正到来。</dd>
</dl>
<div class="tag"><a href="http:www.csdn.net/tag/%E5%B0%8F%E8%B0%A6/news" target="_blank">小谦</a><a href="http:www.csdn.net/tag/%E5%BE%AE%E8%A7%86/news" target="_blank">微视</a><a href="http:www.csdn.net/tag/%E7%A7%92%E6%8B%8D/news" target="_blank">秒拍</a><a href="http:www.csdn.net/tag/%E7%BE%8E%E5%9B%BE%E7%A7%80%E7%A7%80/news" target="_blank">美图秀秀</a><a href="http:www.csdn.net/tag/%E7%BE%8E%E6%8B%8D/news" target="_blank">美拍</a><a href="http:www.csdn.net/tag/%E5%BE%AE%E4%BF%A1/news" target="_blank">微信</a><a href="http:www.csdn.net/tag/%E5%BA%94%E7%94%A8/news" target="_blank">应用</a><a href="http:www.csdn.net/tag/%E7%9F%AD%E8%A7%86%E9%A2%91/news" target="_blank">短视频</a></div>
</div>
从html代码上可以看到,新闻的标题是以<h1>标识的,所以用Element h1_ele = unit_ele.getElementsByTag("h1").get(0);得到一个Element。此处get(0),是因为h1标签的就有1个。
h1标识里的代码是:
<a href="http://www.csdn.net/article/2014-07-30/2820930" target="_blank" >IDC:全球智能机出货量涨23% 华为进前5且翻番</a>
所以通过Element h1_a_ele = h1_ele.child(0);
String title = h1_a_ele.text();
String href = h1_a_ele.attr("href");
得到<a>标签里标识的东西。通过:
String title = h1_a_ele.text();
String href = h1_a_ele.attr("href");
得到标题和链接。
接下来通过h4的tag找日期:
<h4>发表于<span class="ago">14小时前</span>|<span class="view_time">2944次阅读</span>|<span class="num_recom">17条评论</span></h4>
通过class找到ago孩子,最终得到时间。
其他的都类似了,从中可以看出如果是根据html外围的标签,用getElementsByTag("h1").get(0),如果里面包含的有class则要用getElementsByClass("ago").get(0)来进一步定位。如果没有class,只是普通的孩子,利用child(0)定位得到Element。
最后是测试代码:
Test.java
- package org.yanzi.test;
- import java.util.List;
- import org.yanzi.bean.CommonException;
- import org.yanzi.bean.NewsItem;
- import org.yanzi.biz.NewsItemBiz;
- import org.yanzi.csdn.Constant;
- public class Test
- {
- public static void main(String[] args){
- Test test = new Test();
- test.test01();
- }
- @org.junit.Test
- public void test01()
- {
- NewsItemBiz biz = new NewsItemBiz();
- int currentPage = 1;
- try
- {
- /**
- * 业界
- */
- System.out.println("-----------业界-----------");
- List<NewsItem> newsItems = biz.getNewsItems(Constant.NEWS_TYPE_YEJIE, currentPage);
- for (NewsItem item : newsItems)
- {
- System.out.println(item);
- }
- /**
- * 程序员杂志
- */
- System.out.println("-----------程序员-----------");
- newsItems = biz.getNewsItems(Constant.NEWS_TYPE_CHENGXUYUAN, currentPage);
- for (NewsItem item : newsItems)
- {
- System.out.println(item);
- }
- /**
- * 研发
- */
- System.out.println("-----------研发-----------");
- newsItems = biz.getNewsItems(Constant.NEWS_TYPE_YANFA, currentPage);
- for (NewsItem item : newsItems)
- {
- System.out.println(item);
- }
- /**
- * 移动
- */
- System.out.println("-------------移动---------");
- newsItems = biz.getNewsItems(Constant.NEWS_TYPE_YIDONG, currentPage);
- for (NewsItem item : newsItems)
- {
- System.out.println(item);
- }
- System.out.println("-------------结束---------");
- } catch (CommonException e)
- {
- e.printStackTrace();
- }
- }
- }
- -----------业界-----------
- NewsItem [id=0, title=IDC:全球智能机出货量涨23% 华为进前5且翻番, link=http://www.csdn.net/article/2014-07-30/2820930, date=15小时前, imgLink=http://cms.csdnimg.cn/article/201407/30/53d844474e279.jpg, content=IDC日前发布了2014年第二季度全球智能手机市场相关的研究数据。数据显示,位居全球智???手机出货量前五的厂商分别是三星、苹果、华为、联想和LG。华为智能手机出货量更是同比大涨了近一倍,而三星却同比下降。, newsType=1]
- NewsItem [id=0, title=专访叶劲峰:漫谈游戏开发和游戏优化, link=http://www.csdn.net/article/2014-07-30/2820931, date=15小时前, imgLink=http://cms.csdnimg.cn/article/201407/30/53d85983915fe.jpg, content=社区之星第50期采访了腾讯互动娱乐研发部引擎技术中心专家工程师叶劲峰,他讲述了译著《游戏引擎架构》经历,并就游戏引擎、优化、游戏开发学习等进行了分享。与此同时,叶劲峰也将坐镇社区问答第8期回答大家问题。, newsType=1]
- NewsItem [id=0, title=修成正果:Mozilla正式任命Chris Beard为CEO, link=http://www.csdn.net/article/2014-07-29/2820918, date=2014-07-29 14:40, imgLink=http://cms.csdnimg.cn/article/201407/29/53d712420edcd.jpg, content=Mozilla正式任命临时CEO Chris Beard为正式CEO,其于2004年加入Mozilla,随后一直负责产品、营销、创新等方面的工作。后在风投公司担任高管,在创新和企业管理方面积累了很多经验。Beard被公认为最适合的CEO人选。, newsType=1]
- NewsItem [id=0, title=苹果和IBM成最佳搭档 微软谷歌或受威胁, link=http://www.csdn.net/article/2014-07-28/2820905-apple-ibm, date=2014-07-29 14:51, imgLink=http://cms.csdnimg.cn/article/201407/28/53d61d099020f.jpg, content=月中,苹果宣布与IBM达成独家合作协议,两家合作在很大程度上是互补的,因为他们分别专注于消费者和企业市场,合作后必在企业级市场推出更强大的产品。同时,他们的发展也会对微软、谷歌和黑莓等公司带来不利影响。, newsType=1]
- NewsItem [id=0, title=敢为人先:亚马逊推出3D定制和销售门户网站, link=http://www.csdn.net/article/2014-07-29/2820911, date=2014-07-29 08:21, imgLink=http://cms.csdnimg.cn/article/201407/29/53d6e919d6e7e.jpg, content=在线零售商亚马逊近日推出了一门户网站,该网站是一个3D打印产品的销售平台。用户可以根据自己的喜好,比如材料、大小、样式和颜色的个性化,来定制和购买3D产品。甚至只要喜欢,还可以将照片或喜好的话定制上去。, newsType=1]
- NewsItem [id=0, title=微软中国遭工商总局调查 或因涉及“不公平交易”, link=http://www.csdn.net/article/2014-07-29/2820910, date=2014-07-29 07:47, imgLink=http://cms.csdnimg.cn/article/201407/29/53d6dcefe99e0.jpg, content=日前,国家工商总局相关人员突访了微软位??我国北京、上海、广州和成都四地的办公室,正就一些事情展开问询,或因该公司涉及操作系统垄断问题和贿赂官员以换取软件合同等。, newsType=1]
- NewsItem [id=0, title=传智播客“2014年全国高校IT骨干教师研修班”火热开班, link=http://www.csdn.net/article/2014-07-28/2820886, date=2014-07-28 10:11, imgLink=http://cms.csdnimg.cn/article/201407/28/53d5b05190e1a_thumb.jpg, content=日前,由传智播客主办的“2014年全国高校IT骨干教师研修班”火热开班。本届研修班吸引了来自全国30多所院校,近60名IT类专业教师参加。接下来将分Android、Java、PHP、网页平面UI、.Net共5个班开展课程学习交流。, newsType=1]
- NewsItem [id=0, title=【畅言】从程序员到架构师的方法与逻辑, link=http://www.csdn.net/article/2014-07-28/2820883, date=2014-07-28 08:51, imgLink=http://cms.csdnimg.cn/article/201407/28/53d59d5f7d4ca.jpg, content=架构师这个词经常见到,很多人都冠着这个头衔,实际上很多人对架构师究竟是干什么的都没有统一的认识。V众投发起人李智勇则利用特定场景进行分析,诠释了架构师这个概念,并给出如何成为架构师方法。, newsType=1]
- NewsItem [id=0, title=Windows Phone 8.1 Update 1:图标可合并成文件夹、4G语音通话, link=http://www.csdn.net/article/2014-07-28/2820882, date=2014-07-28 07:52, imgLink=http://cms.csdnimg.cn/article/201407/28/53d58fc0ef514.jpg, content=微软终于计划发布已经进入RTM阶段的Windows Phone 8.1Update 1(或GDR1),可能包括:对图标进行拖拽以及合并成文件夹、支持1280 x 800屏幕分辨率和7英寸的设备、支持交互式的手机外壳(见上图),以及4G语音通话。, newsType=1]
- NewsItem [id=0, title=智能硬件生态未成,打造平台为时尚早, link=http://www.csdn.net/article/2014-07-28/2820881, date=2014-07-28 00:37, imgLink=null, content=当前的智能硬件产业发展是由创业公司探路,巨头纷纷跟进打造开放平台。但智能硬件市场至今无标杆性产品、开发者及应用前景不明、尚未找到用户“痛点”等特征表明市场仍处于萌芽阶段,打造平台为时尚早。, newsType=1]
- -----------程序员-----------
- NewsItem [id=0, title=Server SAN:云计算时代的弄潮儿, link=http://www.csdn.net/article/2014-07-28/2820902, date=2014-07-28 15:17, imgLink=http://cms.csdnimg.cn/article/201407/28/53d6087c3920e.jpg, content=Server SAN为何一时间能成为了高大上的东西?分布式存储说来并不新奇,2000年诸如GPFS、Lustre、Panasas及PVFS就出现了,但之后发展不温不火。说到底还是实际应用需求的推动,当前的繁荣源于数据在爆炸式增长。, newsType=4]
- NewsItem [id=0, title=大数据 “在路上”, link=http://www.csdn.net/article/2014-07-25/2820859, date=2014-07-25 11:03, imgLink=http://cms.csdnimg.cn/article/201407/25/53d1cfb8a3844.jpg, content=未来的Google无人驾驶汽车,一定像是一个移动的数据中心,需要同时处理着结构化、非结构化的大量数据,彼时的Big Data才算是真正用于汽车。, newsType=4]
- NewsItem [id=0, title=融合与统一:简评OS X10.10 Yosemite, link=http://www.csdn.net/article/2014-07-21/2820768, date=2014-07-21 17:09, imgLink=http://cms.csdnimg.cn/article/201407/23/53cf2e9689263.jpg, content=苹果旗下两大系列操作系统OS X和iOS发展步调并不一致。相对于iOS的迅猛发展,OS X显得不温不火。Yosemite的发布,应该说是个里程碑。本文基于Yosemite-Developer Preview 1.0版本简单介???这个OS X家族的新成员。, newsType=4]
- NewsItem [id=0, title=智能家居产品安全漫谈, link=http://www.csdn.net/article/2014-07-21/2820748, date=2014-07-21 11:06, imgLink=http://cms.csdnimg.cn/article/201407/21/53cc8931b917b.jpg, content=移动互联网技术的广泛应用为智能家居产业的发展提供了必要条件,无论传统巨头还是新兴创业公司都在投入这一领域,但随之而来的安全问题却未引起足够重视。, newsType=4]
- NewsItem [id=0, title=可穿戴计算机改变信息交互方式, link=http://www.csdn.net/article/2014-07-18/2820718, date=2014-07-18 09:51, imgLink=http://cms.csdnimg.cn/article/201407/18/53c8bf81c4723.jpg, content=可穿戴设备帮助我们更方便地感觉和捕捉世界,并且,我们也在以新的方式进行感官交流。未来几十年,可穿戴计算机将嵌入我们的衣服、珠宝甚至皮肤,而这将对人类信息交互方式产生很大影响。, newsType=4]
- NewsItem [id=0, title=高效能技术团队的协同工具箱, link=http://www.csdn.net/article/2014-07-16/2820681, date=2014-07-16 13:30, imgLink=http://cms.csdnimg.cn/article/201407/16/53c6483a059be.jpg, content=使用适合团队的协同工具,不但能使工作按预定成本如期顺利推进,而且能实现对团队成员、项目过程以及产品等的分析管理。未经调研就选择别人认为好的工具,很可能遭遇“水土不服”。, newsType=4]
- NewsItem [id=0, title=当虚拟照进现实——Oculus的世界梦, link=http://www.csdn.net/article/2014-07-14/2820639, date=2014-07-14 13:19, imgLink=http://cms.csdnimg.cn/article/201407/14/53c36d0be8cd1.jpg, content=专注虚拟现实设备研发的Oculus被Facebook以20亿美元收于麾下,Oculus公司创始人Palmer Luckey希望建立自己的虚拟现实硬件生产线,他还表示要从用户的角度来不断完善Rift,未来是属于用户的,而不仅仅是Oculus。, newsType=4]
- NewsItem [id=0, title=在动态网络下实现分布式共享存储, link=http://www.csdn.net/article/2014-07-09/2820585-implementing-distributed-shared-memory-for-dynamic-networks, date=2014-07-09 10:59, imgLink=http://cms.csdnimg.cn/article/201407/09/53bcddd2580b0.jpg, content=本文介绍了分布式环境下实现共享内存模型会遇到的各种问题和挑战,并针对不同问题介绍多种算法的优劣性。本文是对现阶段该领域研究现状的总体介绍,通过本文能了解动态分布式共享内存研究的前沿状况、挑战与机遇。, newsType=4]
- NewsItem [id=0, title=从Objective-C到Swift, link=http://www.csdn.net/article/2014-07-08/2820568, date=2014-07-08 11:22, imgLink=http://cms.csdnimg.cn/article/201407/09/53bcabb118d79.jpg, content=2014年WWDC大会,苹果在毫无预兆的情况下发布了Swift语言。Swift背后的概念大多与Objective-C类似,但更为简洁、自然,也吸收了很多其他语言的语法。本文将对Swift的语法、特点及改进进行全面介绍。, newsType=4]
- NewsItem [id=0, title=50年内有望实现的7大技术, link=http://www.csdn.net/article/2014-07-07/2820549, date=2014-07-07 10:43, imgLink=http://cms.csdnimg.cn/article/201407/07/53ba0dedb7494.jpg, content=1964年,美国电气与电子工程学会IEEE杂志《IEEE Spectrum》刚成立时,一些预想家就曾预测过50年后的科技走势,如今,这一切都发生了。现在又有一批预想家预测了未来50年的科技发展趋势。, newsType=4]
- -----------研发-----------
最后通过Export---Java---JAR file将其打包。
附个jsoup的相关链接:http://blog.csdn.net/yjflinchong/article/details/7743995
源码下载链接:http://download.csdn.net/detail/yanzi1225627/7697313