Streaming+Python实现Itembased CF
1 数据描述
| 空白 | sku1 | sku2 | … | skuN |
|---|---|---|---|---|
| session1 | 0 | 1 | … | 1 |
| session2 | 1 | 0 | … | 1 |
| … | … | … | … | … |
| sessionM | 1 | 1 | 0 | 0 |
2 向量相似度计算
下面给出计算向量 x,y 的相似度公式, x,y 的长度都为 N
夹角余弦
∑Nk=1 xk×yk∑Nk=1 x2k−−−−−−−√∑Nk=1 y2k−−−−−−−√皮尔逊相似度
∑(x−x¯)×(y−y¯)∑( x−x¯)2−−−−−−−−−√∑( y−y¯)2−−−−−−−−−√欧式距离
∑k=1N(xk−yk)2−−−−−−−−−−−⎷- 杰卡相似度
|x⋂y||x|+|y|−|x⋂y| - 曼哈顿相似度
∑k=1N |xk−yk| - Log-likelihood ratio
下面介绍 x 与 y 之间的loglikelihood ratio计算方式
| 空 | x | x 没发生 |
|---|---|---|
| y |
k11
|
k12
|
| y 没发生 |
k21
|
k22
|
N=k11+k12+k21+k22
loglikelihoodratio=2∗(rowEntropy−columnEntropy−matrixEntropy)
rowEntropy=−k11+k12N×log2(k11+k12N)−k21+k22N×log2(k21+k22N)
其中rowEntropy,columnEntropy,matrixEntropy的计算公式如下
columnEntropy=−k11+k21N×log2(k11+k21N)−k12+k22N×log2(k12+k22N)
matrixEntropy=−k11N×log2(k11N)−k12N×log2(k12>N)−k21N×log2(k21N)−k22N×log2(k22N)
3 普适化的相似度计算
在MapReduce模式下计算商品(向量)间的相似度主要参考如下文章 **《Scalable Similarity-Based Neighborhood Methods with MapReduce》**3.1 三步标准化流程向量相似度
在计算任意向量 x,y 的相似度时,只需要如下三步计算
a) 首先将 x,y 通过前处理计算函数得到 x¯,y¯
x^=preprocess(x),y^=preprocess(y)b) 将经过第一步处理后的向量 x¯,y¯ 输入到 norm() 函数中计算范数
ni=norm(x¯),nj=norm(y¯)c) 在a),b)的基础上计算出向量的相似度
Sij=similarity(dotij,ni,nj),其中:dotij=x^⋅y^
算子说明
- bin(x) :对向量 x 中的值进行二值化
- |x|1 表示对向量 x 求1的范数
三个步骤计算相似度的示例
假设 x,y 是如下三个元素的向量
x=⎡⎣⎢103⎤⎦⎥,y=⎡⎣⎢215⎤⎦⎥- a) 前处理
x^=preprocess(x)=bin(x)=⎡⎣⎢101⎤⎦⎥ b) 计算范数
ni=norm(x¯)=|x^|1=2,nj=norm(y¯)=|y^|1=3c) 计算杰卡相似度
jacc(i,j)=dotijni+nj−dotij=22+3−2=23
- a) 前处理
3.2 常用相似度计算算子总结
在3.1中介绍了如何用三步标准步骤计算向量间的相似度,对于不同的相似度计算方法,这三个步骤中所涉及到的计算算子是不相同的,下表总结了常用相似度的计算算子
|
度量方法
|
preprocess
|
norm
|
similarity
|
|---|---|---|---|
| 余弦相似度 |
v∥v∥2
|
- |
dotij
|
| 皮尔逊相似度 |
v−v¯∥v−v¯∥2
|
- |
dotij
|
| 欧式距离 | - |
v^2
|
ni−2×dotij+nj−−−−−−−−−−−−−−−√
|
| 杰卡距离 |
bin(v)
|
∥v^∥1
|
dotijni+nj−dotij
|
| 曼哈顿距离 |
bin(v)
|
∥v^∥1
|
ni+nj−2×dotij
|
| Log-likelihood ratio |
bin(v)
|
∥v^∥1
|
2×(H(dotij,nj−dotij,nj−dotij,|U|−ni−nj+dotij)−H(nj,|U|−nj)−H(ni,|U|−ni))
|
4 MapReduce+Python实现Itembased CF
经过前面的介绍,如果现在想计算1中介绍的数据格式中的商品相似度,只需要三个MapReduce任务就可以完成,下面分别介绍这两个MR任务的实现,由于Hadoop提供的Streaming接口能够通过标准输入、输出流和其它程序进行数据交互,只要算的上一种语言的基本都支持标准输入、输出流吧,这使其它语言也可以很方便的编写MR程序,具体的就不bb了,上干货。
- 第一个MR程序,对应于 preprocess 方法,主要可以分为分为四种实现方式,
- 分别对应于计算向量(sku向量)的2范数
- 对向量进行归一化(中心化)
- 计算向量(sku向量)的平均值
- 对向量(sku向量)进行二值化。
对于每种计算方法需要的计算算子见下表
|
相似度方法
|
前处理1
|
前处理2
|
|---|---|---|
| 余弦相似度 | 计算向量2的范数(Mapper:cfCosiPreMapper_1.py,Reducer:cfCosiPreReducer_1.py) | 数据归一化(Mapper:cfCosiPreMapper_2.py) |
| 皮尔逊相似度 | 计算向量的和,平方和,2的范数(Mapper:cfPearPreMapper_1.py,Reduce:cfPearPreReducer_1.py) | - |
| 杰卡距离、曼哈顿距离、Log-likelihood ratio | 对向量二值化(Mapper:cfPreMapper.py) | - |
| 欧式距离 | - | - |
前处理示意图
余弦相似度的前处理1示意图
图1 余弦相似度的前处理1示意图
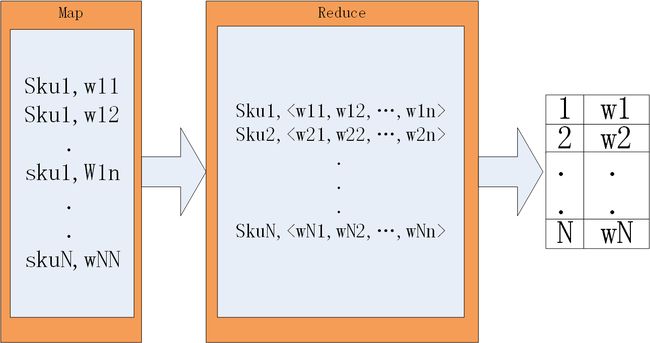
余弦相似度的前处理2示意图
图2 余弦相似度的前处理2示意图

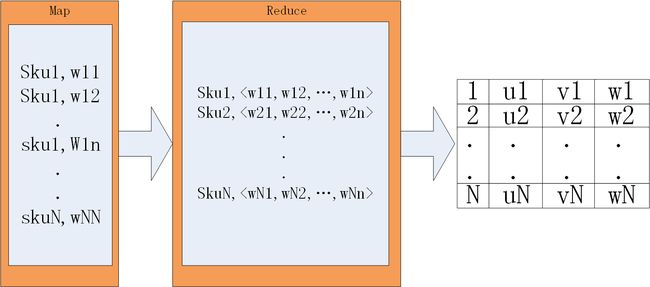
图3 皮尔逊相似度前处理1示意图
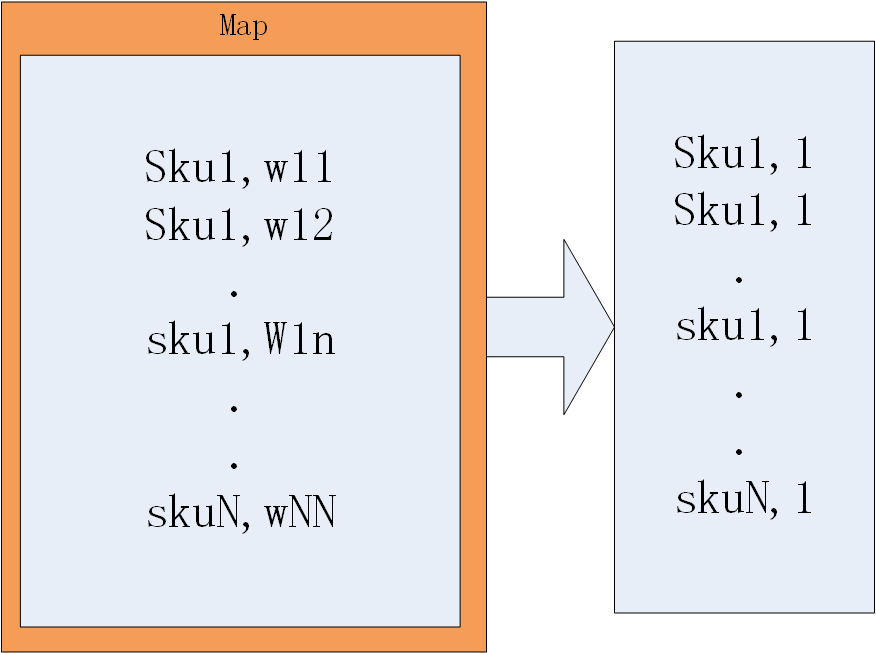
图4 杰卡距离、曼哈顿距离、Log-likelihood ratio前处理1示意图
第二个MR程序,对应于 preprocess 方法,主要可以分为分为两种实现方式,
- 在前处理数据基础上计算向量长度
- 在前处理数据基础上计算向量的1范数
对于每种计算方法需要的计算算子见下表
|
相似度方法
|
norm计算
|
|---|---|
| 欧式距离 | 计算向量长度的平方(Mapper:cfNormMapper.py,Reducer:cfNormReducer.py) |
| 杰卡距离、曼哈顿距离、Log-likelihood ratio | 向量1的范数(Mapper:cfNormMapper.py,Reducer:cfNormReducer.py) |
| 余弦距离,皮尔逊相似度 | - |
- 第三个MR程序,在第二个MR基础上,按照表1中的similarity算子计算各种不同的相似度
5 代码解析
代码分成两部分:
- cfItemSim.sh是可执行脚本,其中封装了全部计算逻辑
- 剩下的其它Python脚本都是MR任务中用到的Mpper和Reducer代码
下面按照前处理,计算,后处理对cfItemSim.sh中的逻辑进行介绍
- 前处理
为了节省存储空间,在计算每个向量(sku向量)长度时需要采用数组额存储方式,所以在进行itembased cf计算之前需要将原始数据中的sku号编码成连续的id,这部分代码如下
- 在${IN_TABLE}_id表中存储的数据供itembased cf方法使用
#=======================================================#
#===================数据预处理方法======================#
#=======================================================#
if [ ${pre} = 'TRUE' ]
then
echo "Preprocess the data......"
#计算uuid1d对应的id
hive -e "
set mapreduce.job.reduce.slowstart.completedmaps=0.9;
drop table ${IN_TABLE}_pin_id;
create table ${IN_TABLE}_pin_id as select cc.uuid1d,cc.id-1 id from (select bb.uuid1d,row_number(bb.num) as id from (select distinct 1 as num, uuid1d from ${IN_TABLE} order by num) bb) cc order by id " #计算sku对应的id hive -e " set mapreduce.job.reduce.slowstart.completedmaps=0.9;
drop table ${IN_TABLE}_sku_id;
create table ${IN_TABLE}_sku_id as select cc.sku,cc.id-1 id from (select bb.sku,row_number(bb.num) as id from (select distinct 1 as num, sku from ${IN_TABLE} order by num) bb) cc order by id " #关联出uuid1d对应的数据 hive -e " set mapreduce.job.reduce.slowstart.completedmaps=0.9;
drop table ${IN_TABLE}_id;
create table ${IN_TABLE}_id as select concat_ws('#',collect_set(sku)) from (select b.id,concat_ws('_',cast(bb.id as string),cast(a.weight as string)) sku from ${IN_TABLE} a join ${IN_TABLE}_pin_id b on (a.uuid1d=b.uuid1d) join ${IN_TABLE}_sku_id bb on (a.sku=bb.sku)) c group by c.id " fi- itembased cf计算部分
在前处理之后就可以计算itembased cf了,根据不同的方法程序中会进行不同的计算,代码如下
- 下面只列出了部分相似度计算代码,详见代码
#在itembased cf计算之前一些数据准备工作
N=`hive -e "select max(id)+1 from ${IN_TABLE}_pin_id"`
lib=`echo ${IN_TABLE}_id | awk 'BEGIN{FS="."} {print $1}'`
tab=`echo ${IN_TABLE}_id | awk 'BEGIN{FS="."} {print $2}'`
input=/user/recsys/${lib}.db/${tab}
output=${tmp}/${method}_output
#=======================================================#
#===============itemSimilarity计算方法==================#
#=======================================================#
echo "Calculate the item to item similarity using cf......"
#Log-likelihood ratio
if [ $method = 'logl' ]
then
#预处理
hadoop fs -rm -r ${tmp}/pre1
cd /data0/recsys/zhongchao/recsys_work/cf;
hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-2.2.0.jar \
-Dmapreduce.job.reduce.slowstart.completedmaps=0.9 \ -Dstream.non.zero.exit.is.failure=false \ -Dmapred.reduce.tasks=0 \ -Dmapred.map.child.java.opts=-Xmx2048m \ -Dmapred.reduce.child.java.opts=-Xmx2048m \ -input ${input} \ -output ${tmp}/pre1 \ -mapper "python ./cfPreMapper.py" \ -file "cfPreMapper.py" #计算norm
hadoop fs -rm -r ${tmp}/pre2
cd /data0/recsys/zhongchao/recsys_work/cf;
hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-2.2.0.jar \
-Dmapreduce.job.reduce.slowstart.completedmaps=0.9 \ -Dstream.non.zero.exit.is.failure=false \ -Dmapred.reduce.tasks=20 \ -Dmapred.map.child.java.opts=-Xmx2048m \ -Dmapred.reduce.child.java.opts=-Xmx2048m \ -input ${tmp}/pre1 \ -output ${tmp}/pre2 \ -mapper "python ./cfNormMapper.py" \ -file "cfNormMapper.py" \ -reducer "python ./cfNormReducer.py ${method}" \ -file "cfNormReducer.py"
norm_file='norm_'`echo $RANDOM`
norm_sort_file='norm_sort'`echo $RANDOM`
# echo $tmp_file1
echo $norm_file
echo $norm_sort_file
hadoop fs -getmerge ${tmp}/pre2 ${norm_file}
cat ${norm_file} | sort -k1 -n > ${norm_sort_file}
#cat hdfs_data.txt | python ./cfNormMapper.py | sort -k1 -n | python ./cfNormReducer.py > norm_sort.txt
#计算相似度
hadoop fs -rm -r ${output};
cd /data0/recsys/zhongchao/recsys_work/cf;
hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-2.2.0.jar \
-Dmapreduce.job.reduce.slowstart.completedmaps=0.9 \ -Dstream.non.zero.exit.is.failure=false \ -Dmapred.reduce.tasks=80 \ -Dmapred.map.child.java.opts=-Xmx2048m \ -Dmapred.reduce.child.java.opts=-Xmx2048m \ -input ${tmp}/pre1 \ -output ${output} \ -mapper "python ./cfSimMapper.py" \ -file "cfSimMapper.py" \ -reducer "python ./cfSimReducer.py ${method} $N ${norm_sort_file}" \ -file "cfSimReducer.py" \ -file ${norm_sort_file}
[ $? -ne 0 ] && { echo "cfSimReducer 错误";exit 2;}
\rm -r ${norm_file}
\rm -r ${norm_sort_file}
#cat pre1 | python ./cfSimMapper.py | sort -k1 -n | python ./cfSimReducer.py logl 12834737 norm_sort28075 | sort -k12 -n > logl.txt
fi
#Jaccard coeffcient
if [ $method = 'jacc' ]
then
#预处理
hadoop fs -rm -r ${tmp}/pre1
cd /data0/recsys/zhongchao/recsys_work/cf;
hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-2.2.0.jar \
-Dmapreduce.job.reduce.slowstart.completedmaps=0.9 \ -Dstream.non.zero.exit.is.failure=false \ -Dmapred.reduce.tasks=0 \ -Dmapred.map.child.java.opts=-Xmx2048m \ -Dmapred.reduce.child.java.opts=-Xmx2048m \ -input ${input} \ -output ${tmp}/pre1 \ -mapper "python ./cfPreMapper.py" \ -file "cfPreMapper.py" #计算norm
hadoop fs -rm -r ${tmp}/pre2
cd /data0/recsys/zhongchao/recsys_work/cf;
hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-2.2.0.jar \
-Dmapreduce.job.reduce.slowstart.completedmaps=0.9 \ -Dstream.non.zero.exit.is.failure=false \ -Dmapred.reduce.tasks=20 \ -Dmapred.map.child.java.opts=-Xmx2048m \ -Dmapred.reduce.child.java.opts=-Xmx2048m \ -input ${tmp}/pre1\ -output ${tmp}/pre2 \ -mapper "python ./cfNormMapper.py" \ -file "cfNormMapper.py" \ -reducer "python ./cfNormReducer.py ${method}" \ -file "cfNormReducer.py"
#cat hdfs_data.txt | python ./cfNormMapper.py | sort -k1 -n | python ./cfNormReducer.py > norm_sort.txt
#计算相似度
norm_file='norm_'`echo $RANDOM`
norm_sort_file='norm_sort'`echo $RANDOM`
# echo $tmp_file1
echo $norm_file
echo $norm_sort_file
hadoop fs -getmerge ${tmp}/pre2 ${norm_file}
cat ${norm_file} | sort -k1 -n > ${norm_sort_file}
hadoop fs -rm -r ${output};
cd /data0/recsys/zhongchao/recsys_work/cf;
hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-2.2.0.jar \
-Dmapreduce.job.reduce.slowstart.completedmaps=0.9 \ -Dstream.non.zero.exit.is.failure=false \ -Dmapred.reduce.tasks=80 \ -Dmapred.map.child.java.opts=-Xmx2048m \ -Dmapred.reduce.child.java.opts=-Xmx2048m \ -input ${tmp}/pre1 \ -output ${output} \ -mapper "python ./cfSimMapper.py" \ -file "cfSimMapper.py" \ -reducer "python ./cfSimReducer.py ${method} $N ${norm_sort_file}" \ -file "cfSimReducer.py" \ -file ${norm_sort_file}
\rm -r ${norm_file}
\rm -r ${norm_sort_file}
#cat pre1 | python ./cfSimMapper.py | sort -k1 -n | python ./cfSimReducer.py jacc 100 norm_sort3284 | sort -k12 -n > text.txt
fi- 后处理
早后处理部分就比较简单了,将itembased cf的计算结果还原成正常的sku号,得到召回模型,代码如下
#=======================================================#
#==============后处理,取topK,生成hive表===============#
#=======================================================#
hadoop fs -rm -r ${output}/_SUCCESS
#建立外部临时表
s="
drop table ${OUT_TABLE}_t1;
CREATE EXTERNAL TABLE ${OUT_TABLE}_t1(id1 string,id2 string,weight double) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${output}'" hive -e "$s" [ $? -ne 0 ] && { echo "$s EXIT";exit 2;} #取临时表中的topK数据 s=" drop table ${OUT_TABLE}_t2;
create table ${OUT_TABLE}_t2 as select id1,id2,weight from (select id1,id2,weight,row_number(id1) id from (select id1,id2,weight from ${OUT_TABLE}_t1 distribute by id1 sort by id1,weight desc) a) b where b.id<${K} " #关联出最终结果 hive -e "$s" [ $? -ne 0 ] && { echo "$s EXIT";exit 2;} s=" drop table ${OUT_TABLE};
create table ${OUT_TABLE} as select b.sku sku1,c.sku sku2,a.weight from ${OUT_TABLE}_t2 a join ${IN_TABLE}_sku_id b on (a.id1=b.id) join ${IN_TABLE}_sku_id c on (a.id2=c.id) " hive -e "$s" [ $? -ne 0 ] && { echo "$s EXIT";exit 2;}6 其它注意事项
- 注意由-i参数控制的输入表的表结构必须为sessionid,sku,weight,否则程序会报错,因为程序中会用这几个字段从某些表中取数,改进的方法是将字段也作为参数从命令行输入或通过配置文件输入
- 在计算余弦相似度和皮尔逊相似度的前处理程序可以进一步改进,随机现在的计算方式结果没有问题,实际上按照表1的计算方式会更加简单,不知道当时怎么想的没按照表1中的算子实现,以后更新。
参考文献:《Scalable Similarity-Based Neighborhood Methods with MapReduce》