LPC10e声码器分析
作者:JHJ([email protected])
日期:2012/08/24
欢迎转载,请注明出处
不好意思,之前文章格式完全错乱了,我现在重新发一下。不多说了,研究语音信号处理的都懂的。
LPC-10e分析器(analys.c)
1. LPC-10e分析器系统框图

图1-1 LPC - 10e分析器[1]
本文假设:
Z(0):当前输入帧的数据,即最新输入帧; Z(-1):前一输入帧的数据;
Z(-2):前两输入帧的数据; Z(-n):前n输入帧的数据;
程序中的AF,是在清/浊音窗的设置及后续程序中用到,AF表示当前窗(对应Z(-2)和Z(-1)),AF – 1表示前第一个窗(对应Z(-3)和Z(-2)),AF – 2 表示前第两个窗。
Data Buffers
INBUF Raw speech (with DC bias removed each frame)
PEBUF Preemphasized speech
LPBUF Low pass speech buffer
IVBUF Inverse filtered speech (白化滤波)
OSBUF Indexes of onsets in speech buffers
VWIN Voicing window indices
AWIN Analysis window indices
EWIN Energy window indices
VOIBUF Voicing decisions on windows in VWIN
RMSBUF RMS energy
RCBUF Reflection Coefficients
2. 在analys.c中各buffer中数据分布情况:



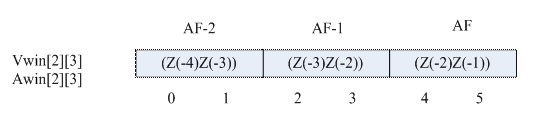
Vwin及Awin中存储的是窗的起点和终点的序号。

Voibuf中半帧voice的值,0代表清音,1代表浊音。

Obound中存储的是onset和vwin的关系值:
Obound = 0表示清/浊音窗两端无onset;
Obound = 1表示清/浊音窗左端有一个onset;
Obound = 2表示清/浊音窗右端有一个onset;
Obound = 3 表示清/浊音窗两端各有一个onset;

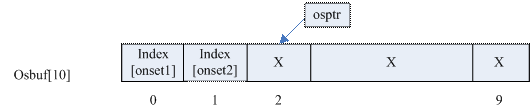
Osbuf中存储的是onset的序号,osptr指针最后一个onset存储位置的后一个存储单元,当Osbuf中无onset时候,osptr指向Osbuf[0]。程序中未考虑Osbuf溢出情况,因为Osbuf缓冲区足够大了。
每调用一次analys_( )函数,osbuf数据更新,即(index[onset] = (index[onset] – 180)) > 0的值顺序存入osbuf中,同时osptr值更新。
注:每次调用analys_( )函数,先更新以上个buffer的数据,再开始做相应的处理。
3. 确定AMDF及清/浊音窗的数据流向图
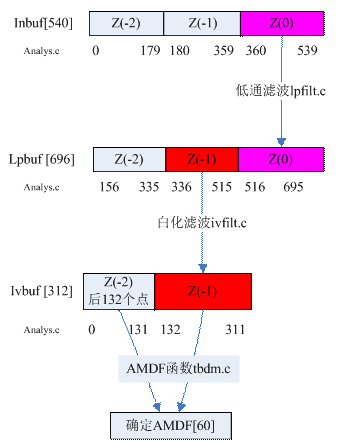
图3-1 确定AMDF[ ]
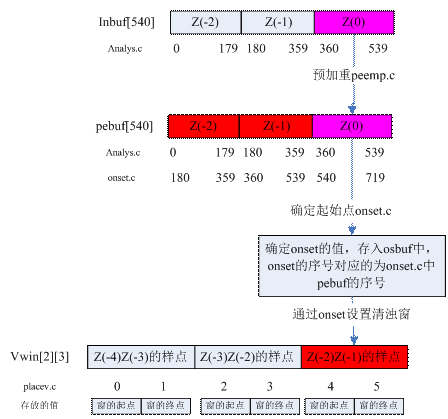
图3-2 确定清浊音窗
如图3-2所示,vwin[ ]中存放的是窗的起点和终点的值。
4. 预加重(preemp.c)
在实施LP分析前进行预加重的目的是加强语音谱中的高频共振峰,使语音短时谱以及线性分析中的余数(残差)频谱变得更为平坦,从而提高了谱参数估值的精确性。
预加重滤波器的传输函数为:
H(z) = 1 - coef * pow(z,-1),coef = 0.9375;
其时域函数为:
pebuf(n) = inbuf(n) - coef * inbuf(n-1);
preemp_( )函数处理的是Z(0)帧的数据,即inbuf(Z(0)) —> pebuf(Z(0))。
5. 白化滤波(ivfilt.c)
白化滤波器是指数字语音经过二阶LPC分析滤波器后,滤除共振峰的白化语音[1]。
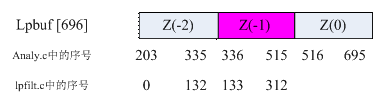

图5-1
程序中,函数ivfilt__( )是将Lpbuf[133,312]中的数据通过ivfilter存入ivbuf[133,312]中。即lpbuf(Z(-1))—>ivbuf(Z(-1))。
6. AMDF函数(tbdm.c)
此函数的输入是白化滤波后的样点数据,把采样频率降低至原来的1/4,再计算延迟时间为20至156个样点的AMDF,由AMDF的最小值即可确定基音周期。
![]() 公式(5-1)
公式(5-1)
其中,t的取值可以为:20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,40,42,44,46,48,50,54,56,58,60,62,64,66,68,70,72,74,76,78,80,84,88,92,96,100,104,108,112,116,120,124,128,132,136,140,144,148,152,156相当于在50-400Hz范围内计算60个ADMF值。
当初步计算出最小AMDF及mintau(最小AMDF所对应的基音周期)时,由于基音周期取值>40后,在整数域上的不连续性,因此需要还需要计算表tau中被遗漏的基音周期所对应的AMDF。
这里采用的方法是:基因周期>40时,取出(mintau - 3)到(mintau + 3)而不包括表tau中的值,将这些值放入新表tau2,用函数difmag_()重新计算这些未被计算过的基音周期, 从而可以提取更精确的基音周期值。

图6-1

图6-2 提取最小AMDF函数流程图
7. 低通滤波(lpfilt.c)


图7-1
按程序所示,函数Lpfilt__( )是将Inbuf[133,312]中的数据通过低通滤波器存入Lpbuf[133,312],即inbuf(Z(0))—>lpbuf(Z(0))。
8. 确定起始点(onset.c)
为了使合成语音清楚地再现急剧变化的语音的起始点的特性,将提取语音特征参数的分析窗的起点取在语音特征短时急剧变化的起始点处在这里是用计算预加重语音x的一阶PARCOR参数的变化来确定语音巨变的起始点。计算公式如下:
Y(i) = (K(i - j)|(j=0 to N/2-1)求和) – (K(i - j)|(j=N/2 to N)求和) (公式7.1)
K(i) = n(i)/d(i) = {[x(i)x(i - 1) + 63n(i -1)/64]/[x(i)x(i) + 63d(i - 1)/64]} (公式7.2)
这里N为帧长。如果y(i)超过某个给顶的阈值,则i点为起始点。

图8-1 onset__()中prebuf数据储存结构
Osbuf中对应的序号是图7.1中pebuf所示的序号。从图7.1和图7.2中可以看出,每次调用onset__( )函数,实际上是检测Z(0)中的onset。
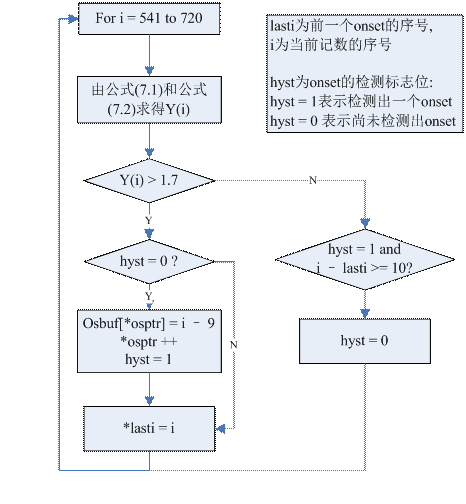
图8-2 onset__( )函数流程图
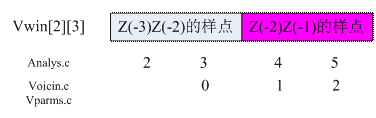
9. 设置清/浊音窗(placev.c)
此函数用来确定最新清/浊音窗的窗长及obound(清/浊音窗与onset的关系)。
![]()


图9-1 placev__( )中buffer数据储存结构
对应图8-1中Pebuf,Range的范围是[180,540],窗长范围是[90,156]。因此是在Z(-2)、Z(-1)这两帧中确定最新的清/浊音窗的。
清/浊音窗的确定原则如下:
1.当range中没有onset时,两种可能性确定起始点:
(1)前一个窗的窗尾大于等于dvwinl,则起点接着此窗尾后面;
(2)前一个窗的窗尾小于dvwinl,则已默认值dvwinl为起点。
2.当range中有一个onset时,则以此onset的前一个点为当前VWIN的窗尾,窗头取max(180, onset value - 156), 表示窗起点可能为180下标, 但窗长不能超过156,此时onset在VWIN的右侧。
3.当range中有超过一个onset时,取第1个onset的点为VWIN窗头,
(1)若第1个onset和第2个onset的间距超过90时,取第2个onset为VWIN窗尾,此时窗两测各有一个onset;
(2)若此两个onset间距小于90,若此range中就2个onset,则窗尾取min(窗头+156,560);
(3)若此两个onset间距小于90,且还有第3个点若第1个onset和第3个onset间距仍然小于90,处理方法同(2),若间距大于90,处理方法同(1)。以此类推。
10. 清/浊音判决(包括计算能量、检测过零率)(voicing.c)




清/浊音判决是利用模式匹配技术,基于低带能量,AMDF函数的最大值和最小值之比,过零率做出的。最后对基音值通过清、浊音判决结果用动态规划算法,得出前一帧的基音周期。在三清浊音窗范围内进行平滑和误差范围校正,得出第一个窗的清、浊音判决结果。
清/浊音判决是对输入语音每半帧判决一次(程序中实际是对清/浊音窗每半个窗判决一次,最后乘以一个比例因子),判决结果存入 voibuf中,0代表清音,1代表浊音。先是对当前窗做暂时的清/浊音判决,而利用这个判决结果对前两个窗做平滑处理,得出前第2个窗的判决结果,而前第1个窗的结果需要未来一个窗的结果来平滑决定。
清/浊音参数向量(VALUE)基于矩形窗的语音样点,由加窗算法决定的。清/浊音参数向量包括AMDF函数的最大值和最小值之比、过零率、能量检测、反射系数、预测增益做出决定的。
输入信号分为清音(包括无声)和浊音。清/浊音的判决由线性判别函数确定,即清/浊音判决系数(VDC)行向量和清/浊音参数列向量(VALUE)的点乘。VDC向量是一个二维向量,每一个行向量都对应一个特定的信噪比(SNR)。因此,在点乘前,先需要估计一个SNR来选择合适的VDC向量。
平滑算法是一个修改中间值的平滑器。清/浊音判别函数利用这个平滑器来确定一个信号的清/浊音的健壮性。如果在某个半帧中如果有一个onset或者清/浊音转变,则数据可以得到进一步修正。在这种情况下,清/浊音转变点会延长到onset。出于传输考虑,清/浊音转变期会有些限制。平滑器会考虑这些限制性因数。
最后,更新能量估计值和用来计算过零率(ZC)的阈值dither。

图10-1 清/浊音判决流程图
11. 基音检测(dyptrk.c)
用动态规划算法求解基音值的基本思想是:欲求出前n帧的最小AMDF,则只需要求出前n-1 帧的AMDF的权值,加上当前帧的AMDF,然后求最小值,找出最小AMDF对应的基音值就是所要求的基音值。现在的问题是如何通过前n-1帧的AMDF的权值求解前n帧的AMDF。先将前n-1帧的权值做斜率阈值限制处理,即AMDF[60]缓冲区中相邻的AMDF值的绝对值不能大于某个值,然后把限制处理后的值都减去最小AMDF,则更新了前n-1帧AMDF缓冲区。此时用这个缓冲区的值加上当前AMDF,求出最小AMDF即可。
函数dyptrk__( )中有三个重要变量:s[ ]、p[ ]和alphax。下面是这三个变量的简单说明:
s[60]:s[60]为amdf[60]的权值,与所有以前求出的 amdf[60]都关联起来。
p[120]:p[60][2]中储存的信息是:s[60]中被修改的元素的信息。比如p[5 to 10]={8,8,8,8,8,8,8},则说明s[7](即第8个元素)未被修改,而s[5 to 6]和s[8 to 10]被修改。
alphax:alphax/16为s[60]的斜率阈值,即s[60]中相邻元素的差值的绝对值不大于alphax/16,alphax的确定和清浊音有关。
12. 设置分析窗(placea.c)

确定分析窗awin
分析窗由4个参数决定:清浊音窗,起始点,零时清浊音判决,基音周期。有以下三种情况:
l 连续的浊音
即voibuf的(2,AF-2), (1,AF-1), (2,AF-1), (1,AF), (2,AF)都为1
这里先确定awin[((*af - 1) << 1) + 1]与k(其中k = (vwin[(*af << 1) + 1] + vwin[(*af << 1) + 2] + 1 - 156) / 2)的间距,然后以awin[((*af - 1) << 1) + 1]为起点,pitch为步长,确定 awin[(*af << 1) + 1]使得(|k - pitch/2|) <= awin[(*af << 1) + 1]。然后先默认分析窗的窗长为156,确定awin[(*af << 1) + 2]。对于4种情况(详见程序)需要调整当前分析帧的端点(原则是窗中不能有onset且不能超出定义域[180,540])。
l 清浊音转变
即voibuf的(1,AF), (2,AF)不全为零且obound = 0;
处理方式同连续的浊音。
l 清音或者有起始点(obound != 0 )
AF中如果为清音或者obound != 0(非连续浊音情况),则分析窗和清浊音窗相同。
确定能量窗ewin
l 如果本窗为清音窗,则能量窗与清浊音窗(亦即分析窗)相同。
l 若为case 3且obound = 2(清浊音窗的右端点有onset), 亦即obound = 2且非连续的浊音,则能量窗的右端点与分析窗的右端点相同,能量窗窗长为有效分析窗(即分析窗中最大整数个pitch的长度),以此来确定能量窗的左端点。
l 其他情况下,则能量窗的左端点与分析窗的左端点相同,能量窗的窗长为有效分析窗,以此来确定能量窗的右端点。
13. RMS计算(energy.c)
以prebuf(加AF能量窗,即对应Z(-2)Z(-1)输入帧)为输入,去除其直流分量,然后计算RMS值。即计算当前能量窗(AF)中预处理语音数据的RMS。
14. 协方差分析(invert.c)
书[1],P72~P73有求解介绍。由于是在分析窗的窗内求解,因此只要分析窗确定,就可以利用相应程序得出LPC及RC值。
15. 困惑问题
1) 在analys_(&speech[1], voice, &pitch, &rms, rc, st)函数中,输入的是180个语音点,输出的是voice, pitch, rms, rc的参数值,这些参数值对应的是哪个输入帧?(2007-11-9)
答:输出的voice, pitch, rms, rc的参数值是对应AF-2清浊音窗中的参数值,因此对应的是输入帧的Z(-4)Z(-3)帧。
参考文献
[1] 王炳锡编著。西安:西安电子科技大学出版社,2002
[2] LPC10e源代码