MPI远程存储访问,实现的简化版参数服务器
简介
按照http://www.cs.cmu.edu/~muli/file/parameter_server_osdi14.pdf 所述,在分布式机器学习中个使用参数服务器并行训练模型。即把模型参数存储在特定服务器上,其它训练模型的节点从服务器上获取模型参数,在训练节点上训练一些样本后,再把模型参数推动到参数服务器,达到并行训练目的。
参数服务器的结构如下
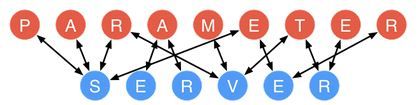
蓝色节点为存储参数的服务器,即Server,红色节点为计算节点即Worker
MPI实现简单的参数武器
- 下面就用MPI中的远程存储访问可能实现一个简化版的参数服务器,用进程0作为参数服务器Server。其它进程作为计算Worker。Worker可以从Server上pull参数,可以把本地参数put到服务器,也把本地数据加到Server上。
- 用到的MPI函数
MPI_Win_create:创建窗口,供其他进程访问相等于Server中的一块缓存
MPI_Win_lock,MPI_Win_unlock对被访问的窗口进行加锁和解锁
MPI_Put:将Worker数据推送到Server上
MPI_Get:从Server上拉数据
MPI_Accumulate:将Worker和Server上的数据相加
详细的API见:http://mpi.deino.net/mpi_functions/
- 上代码
#include "mpi.h"
#include "stdio.h"
#define SIZE1 10
#define SIZE2 22
int main(int argc, char *argv[])
{
int rank, destrank, nprocs, *A, *B, i;
MPI_Group comm_group, group;
MPI_Win win;
int errs = 0;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&nprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
i = MPI_Alloc_mem(SIZE2 * sizeof(int), MPI_INFO_NULL, &A);
if (i) {
printf("Can't allocate memory in test program\n");fflush(stdout);
MPI_Abort(MPI_COMM_WORLD, 1);
}
i = MPI_Alloc_mem(SIZE2 * sizeof(int), MPI_INFO_NULL, &B);
if (i) {
printf("Can't allocate memory in test program\n");fflush(stdout);
MPI_Abort(MPI_COMM_WORLD, 1);
}
MPI_Comm_group(MPI_COMM_WORLD, &comm_group);
if(rank == 0)
{ /* rank = 0 */
for (i=0; i<SIZE2; i++) B[i] = 0;
MPI_Win_create(B, SIZE2*sizeof(int), sizeof(int), MPI_INFO_NULL, MPI_COMM_WORLD, &win);
destrank = 0;
}
else
{
/*rank = others*/
for (i=0; i<SIZE2; i++)
{
A[i] = rank;
B[i] = 0;
}
MPI_Win_create(NULL, 0, 1, MPI_INFO_NULL, MPI_COMM_WORLD, &win);
destrank = 1;
MPI_Win_lock(MPI_LOCK_EXCLUSIVE, 0, 0, win);
//MPI_Put(A, SIZE2, MPI_INT, 0, 0, SIZE2, MPI_INT, win);
MPI_Accumulate(A, SIZE2, MPI_INT, 0, 0, SIZE2, MPI_INT, MPI_SUM, win);
MPI_Get(B, SIZE2, MPI_INT, 0, 0, SIZE2, MPI_INT, win);
MPI_Win_unlock(0, win);
for(i = 0; i < SIZE2; i++)
printf("%d= %d ", rank, B[i]);
printf("\n");
}
MPI_Win_free(&win);
MPI_Free_mem(A);
MPI_Free_mem(B);
MPI_Finalize();
return errs;
}- 编译mpic++ ps.cpp -o ps
- 执行mpirun -n 3 ./ps
改进
用MPI原生的API做起来比较麻烦,可以借助MPI,在进程之间用socket通信,线服务器推送数据,从服务器取数据,在服务器操作会更方便