《李航:统计学习方法》笔记之感知机
感知机学习旨在求出将训练数据集进行线性划分的分类超平面,为此,导入了基于误分类的损失函数,然后利用梯度下降法对损失函数进行极小化,从而求出感知机模型。感知机模型是神经网络和支持向量机的基础。也是现代流行的深度学习网络模型的基础。下面分别从感知机学习的模型、策略和算法三个方面来介绍。
1. 感知机模型
感知机模型如下:
f(x)= sign(w*x+b)
其中,x为输入向量,sign为符号函数,括号里面大于等于0,则其值为1,括号里面小于0,则其值为-1。w为权值向量,b为偏置。求感知机模型即求模型参数w和b。感知机预测,即通过学习得到的感知机模型,对于新的输入实例给出其对应的输出类别1或者-1。2. 感知机策略
假设训练数据集是线性可分的,感知机学习的目标就是求得一个能够将训练数据集中正负实例完全分开的分类超平面,为了找到分类超平面,即确定感知机模型中的参数w和b,需要定义一个损失函数并通过将损失函数最小化来求w和b。
这里选择的损失函数是误分类点到分类超平面S的总距离。输入空间中任一点x 0 到超平面S的距离为: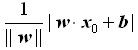
其中,||w||为w的L2范数。
其次,对于误分类点来说,当-y i (wx i + b)>0时,y i=-1,当-y i(wx i + b)<0时,y i=+1。所以对误分类点(x i, y i)满足:-yi (wxi +b) > 0
所以误分类点(x i, y i)到分类超平面S的距离是:
3. 感知机算法
感知机学习问题转化为求解损失函数式(1)的最优化问题,最优化的方法是随机梯度下降法。感知机学习算法是误分类驱动的,具体采用随机梯度下降法。首先,任意选取一个超平面w0,b0,然后用梯度下降法不断极小化目标函数式(1)。极小化的过程不是一次使M中所有误分类点的梯度下降,而是一次随机选取一个误分类点使其梯度下降。
损失函数L(w,b)的梯度是对w和b求偏导,即:

这种算法的基本思想是:当一个实例点被误分类,即位于分类超平面错误的一侧时,则调整w和b,使分类超平面向该误分类点的一侧移动,以减少该误分类点与超平面的距离,直到超平面越过该误分类点使其被正确分类为止。
需要注意的是,这种感知机学习算法得到的模型参数不是唯一的,它会由于采用不同的参数初始值或选取不同的误分类点,而导致解不同。为了得到唯一的分类超平面,需要对分类超平面增加约束条件,线性支持向量机就是这个想法。另外,当训练数据集线性不可分时,感知机学习算法不收敛,迭代结果会发生震荡。而对于线性可分的数据集,算法一定是收敛的,即经过有限次迭代,一定可以得到一个将数据集完全正确划分的分类超平面及感知机模型。
以上是感知机学习算法的原始形式,下面介绍感知机学习算法的对偶形式,对偶形式的基本想法是,将w和b表示为实例x i 和标记y i 的线性组合形式,通过求解其系数而求得w和b。对误分类点(x i , y i )通过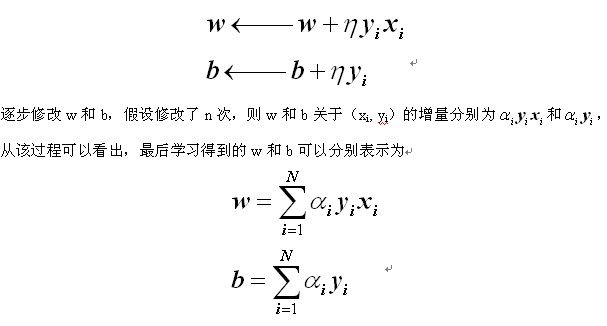

感知机的原始形式和对偶形式在解决问题的计算上是一致的,但是他们的思想不同,原始形式的基本思想是对于误分类点,调整w和b,使分类超平面向该误分类点的一侧移动,以减少该误分类点与超平面的距离,直到超平面越过该误分类点使其被正确分类为止。 而对偶形式的基本思想是将w和b表示成x和y的线性组合形式,从而求出w和b。
1)原始形式代码如下:
#include <iostream>
using namespace std;
int x[3][2] = {
{3, 3},
{4, 3},
{1, 1}
};
int y[3] = {1, 1, -1};
int w[2] = {0};
int b = 0;
int L(int y, int* x)
{
int temp = (w[0] * x[0] + w[1] * x[1] + b) * y;
if (temp <= 0)
return 1;//存在错误点
else
return 0;
}
int main(void)
{
int j = 1;
while (true)
{
cout << j++ << " ";
int i;
int num = 0;
for (i = 0; i < 3; i++)
{
if (L(y[i], x[i]) == 1)
{
cout << "error point:";
cout << "x" << i <<" w:";
int j;
for (j = 0; j < 2; j++)
{
w[j] += y[i] * x[i][j];
cout << w[j] << " ";
}
b += y[i];
cout << "b:" << b <<endl;
num++;
break;
}
}
if (num == 0)
break;
}
return 0;
}
实验结果:
1 error point:x0 w:3 3 b:1
2 error point:x2 w:2 2 b:0
3 error point:x2 w:1 1 b:-1
4 error point:x2 w:0 0 b:-2
5 error point:x0 w:3 3 b:-1
6 error point:x2 w:2 2 b:-2
7 error point:x2 w:1 1 b:-3
这跟p30的结果是一样的,不过要注意的是,在极小化的过程中,为了达到书中的结果,选择的误分类点都是第一次遇到的误分类点,而实际上在选择误分类点时应该采用随机的方法来选取,而且每次梯度下降的时候并不是对所有误分类点进行梯度下降,而是只对随机选择的一个误分类点进行梯度下降。结果与误分类点的选择有关。
2)对偶形式,代码如下:#include <iostream>
using namespace std;
int x[3][2] = {
{3, 3},
{4, 3},
{1, 1}
};
int y[3] = {1, 1, -1};
int b = 0;
int a[3] = {0};
int G[3][3] = {
{18, 21, 6},
{21, 25, 7},
{6, 7, 2}
};//Gram matrix
int L(int j)
{
int temp = 0;
for (int i=0 ;i < 3; i++)
{
temp += a[i] * G[i][j] * y[i];
}
temp += b;
temp *= y[j];
if (temp <= 0)
return 1;//存在错误点
else
return 0;
}
int main(void)
{
int j = 1;
while (true)
{
cout << j++ << " ";
int i;
int num = 0;
for (i = 0; i < 3; i++)
{
if (L(i) == 1)
{
cout << "error point:";
cout << "x" << i <<" a:";
int j;
a[i] += 1;
for (j = 0; j < 3; j++)
{
cout << a[j] << " ";
}
b += y[i];
cout << "b:" << b <<endl;
num++;
break;
}
}
if (num == 0)
break;
}
return 0;
}
实验结果如下:
1 error point:x0 a:1 0 0 b:1
2 error point:x2 a:1 0 1 b:0
3 error point:x2 a:1 0 2 b:-1
4 error point:x2 a:1 0 3 b:-2
5 error point:x0 a:2 0 3 b:-1
6 error point:x2 a:2 0 4 b:-2
7 error point:x2 a:2 0 5 b:-3